
video-extend
alibaba / happyhorse-1.0 / video-extend
Alibaba Happy Horse 1.0 (Video Extend) extends existing videos with seamless AI-generated continuation, supporting 720p/1080p output. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-to-video
alibaba / happyhorse-1.0 / video-edit
Alibaba Happy Horse 1.0 (Video Edit) performs prompt-driven video editing with multi-image reference support, supporting 720p/1080p output. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

image-to-video
alibaba / happyhorse-1.0 / reference-to-video
Alibaba Happy Horse 1.0 (Reference-to-Video) generates new video scenes guided by reference images, maintaining consistent characters, styles, and visual identity. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

image-to-video
alibaba / happyhorse-1.0 / image-to-video
Alibaba Happy Horse 1.0 (Image-to-Video) animates a reference image into a cinematic 720p / 1080p video, optionally guided by a text prompt. Smooth camera movement and expressive, stable motion. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

text-to-video
alibaba / happyhorse-1.0 / text-to-video
Alibaba Happy Horse 1.0 (Text-to-Video) generates cinematic 720p / 1080p videos from text prompts with smooth camera movement, expressive motion, and strong prompt fidelity. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-extend
bytedance / seedance-2.0-fast / video-extend
Seedance 2.0 Fast (Video-Extend) extends an input video with a new cinematic continuation generated from its last frame and a natural-language prompt — at the faster, cheaper Seedance 2.0 Fast tier. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-extend
bytedance / seedance-2.0 / video-extend
Seedance 2.0 (Video-Extend) extends an input video with a new cinematic continuation generated from its last frame and a natural-language prompt. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-to-video
bytedance / seedance-2.0-fast / video-edit-turbo
Seedance 2.0 Fast (Video-Edit Turbo) is the fastest, cheapest turbo tier for editing an input video from a natural-language prompt — high-resolution output with optimized cost and speed. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-to-video
bytedance / seedance-2.0 / video-edit-turbo
Seedance 2.0 (Video-Edit Turbo) is the turbo tier for editing an input video from a natural-language prompt — faster, more affordable high-resolution output while preserving subject identity, composition, and motion. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-to-video
bytedance / seedance-2.0-fast / video-edit
Seedance 2.0 Fast (Video-Edit) edits an input video from a natural-language prompt at a faster, cheaper tier. Built on ByteDance Seed's unified multimodal architecture, it preserves subject identity, composition, and motion while rewriting lighting, style, weather, environment, or specific elements as instructed. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

video-to-video
bytedance / seedance-2.0 / video-edit
Seedance 2.0 (Video-Edit) edits an input video from a natural-language prompt. The reference video drives subject identity, composition, and motion while the model rewrites lighting, style, weather, environment, or specific elements as instructed. Built on ByteDance Seed's unified multimodal architecture for cinematic, motion-stable output. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

text-to-video
kwaivgi / kling-v3.0-4k / text-to-video
Kling V3.0 4K delivers top-tier 4K text-to-video generation with smooth motion, cinematic visuals, accurate prompt adherence, and optional audio. Supports flexible aspect ratios, multi-prompt, and element references. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
kwaivgi / kling-v3.0-4k / image-to-video
Kling V3.0 4K delivers top-tier 4K image-to-video generation with smooth motion, cinematic visuals, accurate prompt adherence, and optional audio. Supports start/end frame control, multi-prompt, and element references. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
kwaivgi / kling-video-o3-4k / reference-to-video
Kling Video O3 4K Reference-to-Video generates creative 4K videos using character, prop, or scene references from multiple viewpoints. Extracts subject features and creates new video content while maintaining identity consistency across frames. Supports multi-reference images, video guidance, and optional audio generation. Ready-to-use REST API, best performance, no cold starts, affordable pricing.

text-to-video
kwaivgi / kling-video-o3-4k / text-to-video
Kling Video O3 4K generates cinematic 4K videos from text prompts with subject consistency, natural physics simulation, and precise semantic understanding. Supports multi-prompt scene transitions, element references, and optional audio generation. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

image-to-video
kwaivgi / kling-video-o3-4k / image-to-video
Kling Video O3 4K Image-to-Video transforms static images into dynamic cinematic 4K videos. Maintains subject consistency while adding natural motion, physics simulation, and seamless scene dynamics. Supports start/end frame control, multi-prompt, and optional audio generation. Ready-to-use REST API, best performance, no coldstarts, affordable pricing.

image-to-image
openai / gpt-image-2 / edit
OpenAI's GPT Image 2 Edit enables image editing from natural-language instructions with one or more reference images. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.
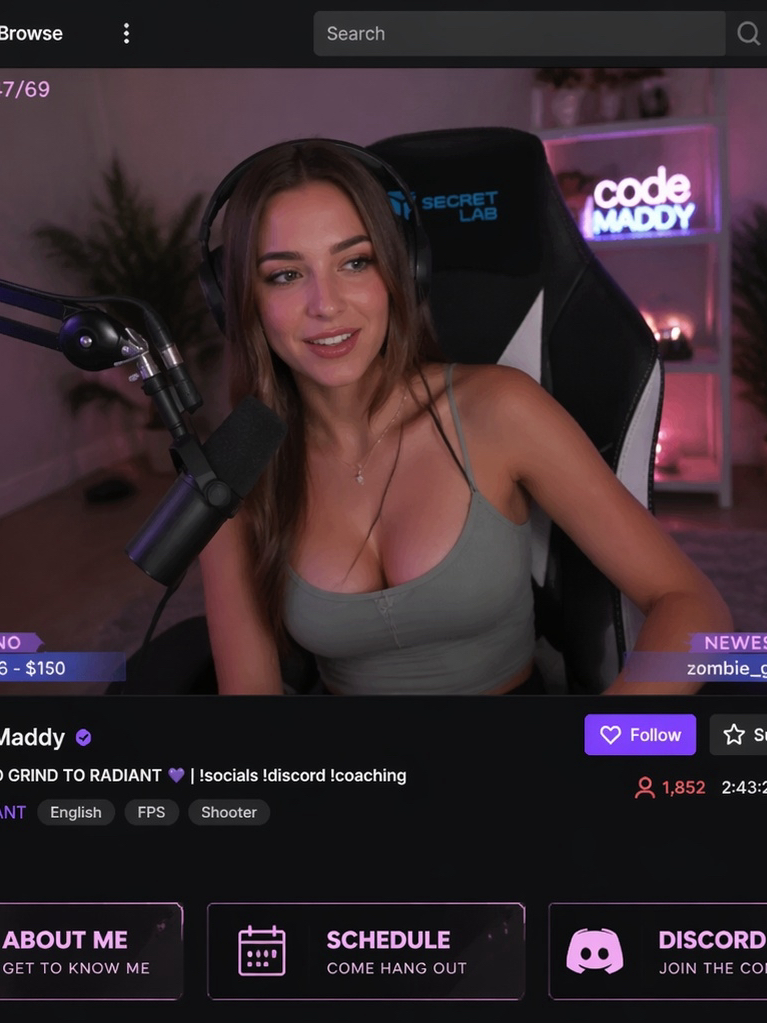
text-to-image
openai / gpt-image-2 / text-to-image
OpenAI's GPT Image 2 Text-to-Image generates high-quality images from natural-language prompts. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / patina / material-extract
PATINA Material Extract turns any photograph or reference image into a complete seamlessly tiling PBR material set (basecolor, normal, roughness, metalness, height), guided by a text prompt. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
wavespeed-ai / patina / material
PATINA Material generates complete seamlessly tiling PBR material sets (basecolor, normal, roughness, metalness, height) from text prompts — perfect for game engines, 3D rendering, and material libraries. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / patina / image-to-map
PATINA generates seamless high-resolution PBR material maps (basecolor, normal, roughness, metalness, height) from a single image, ready for use in Unreal, Unity, Blender, and other 3D pipelines. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

video-to-video
wavespeed-ai / void-video-inpainting / mask
VOID Video Inpainting removes objects from videos using mask-guided inpainting. Supports quad-mask or auto-generated SAM-3 masks, optional Pass 2 refinement for temporal consistency, adjustable denoising steps, guidance scale, and temporal window size. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
wavespeed-ai / nucleus-image / text-to-image
Nucleus Image generates high-quality images from text prompts with flexible aspect ratios, adjustable inference steps, and classifier-free guidance. Supports negative prompts, reproducible seeds, and multiple output formats. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-3d
tripo3d / h3.1 / image-to-3d
Tripo3D H3.1 Image-to-3D converts a single image into high-quality 3D models with textures and PBR materials. Supports standard and HD texture quality, detailed geometry, quad mesh topology, texture alignment, and orientation control. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-3d
tripo3d / h3.1 / text-to-3d
Tripo3D H3.1 Text-to-3D generates high-quality 3D models from text descriptions. Supports textures with standard and HD quality, PBR materials, detailed geometry, quad mesh topology, and auto-sizing. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-3d
tripo3d / h3.1 / multiview-to-3d
Tripo3D H3.1 Multiview-to-3D generates high-quality 3D models from 2-4 multi-angle images. Supports standard and HD texture quality, PBR materials, detailed geometry, quad mesh topology, texture alignment, and orientation control. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
wavespeed-ai / ernie-image / text-to-image-turbo
Baidu ERNIE Image Turbo is a distilled, 8-step version of ERNIE Image for fast, low-cost generation. Supports English, Chinese, and Japanese prompts with flexible sizing. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
wavespeed-ai / ernie-image / text-to-image
Baidu ERNIE Image generates high-quality images from text prompts in English, Chinese, and Japanese, with flexible sizing and LLM-enhanced prompt expansion. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

digital-human
wavespeed-ai / music-video-generator
AI Music Video Generator transforms audio + a single photo into a full music video with cinematic camera angles, smooth transitions, and perfect lip sync. Up to 10 minutes, 480p or 720p. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
pixverse / pixverse-c1 / reference-to-video
PixVerse C1 Reference-to-Video generates videos from reference images with subject and background consistency. Use @ref_name in prompts to reference uploaded images. Supports 360p to 1080p resolutions, 1-15 second duration, multiple aspect ratios, and optional audio generation. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
pixverse / pixverse-c1 / transition
PixVerse C1 generates smooth transition videos between two images with flexible duration (1-15s), multiple resolutions up to 1080p, and optional native audio generation. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
pixverse / pixverse-c1 / image-to-video
PixVerse C1 generates film-grade videos from a starting image with flexible duration (1-15s), multiple resolutions up to 1080p, and optional native audio generation. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.
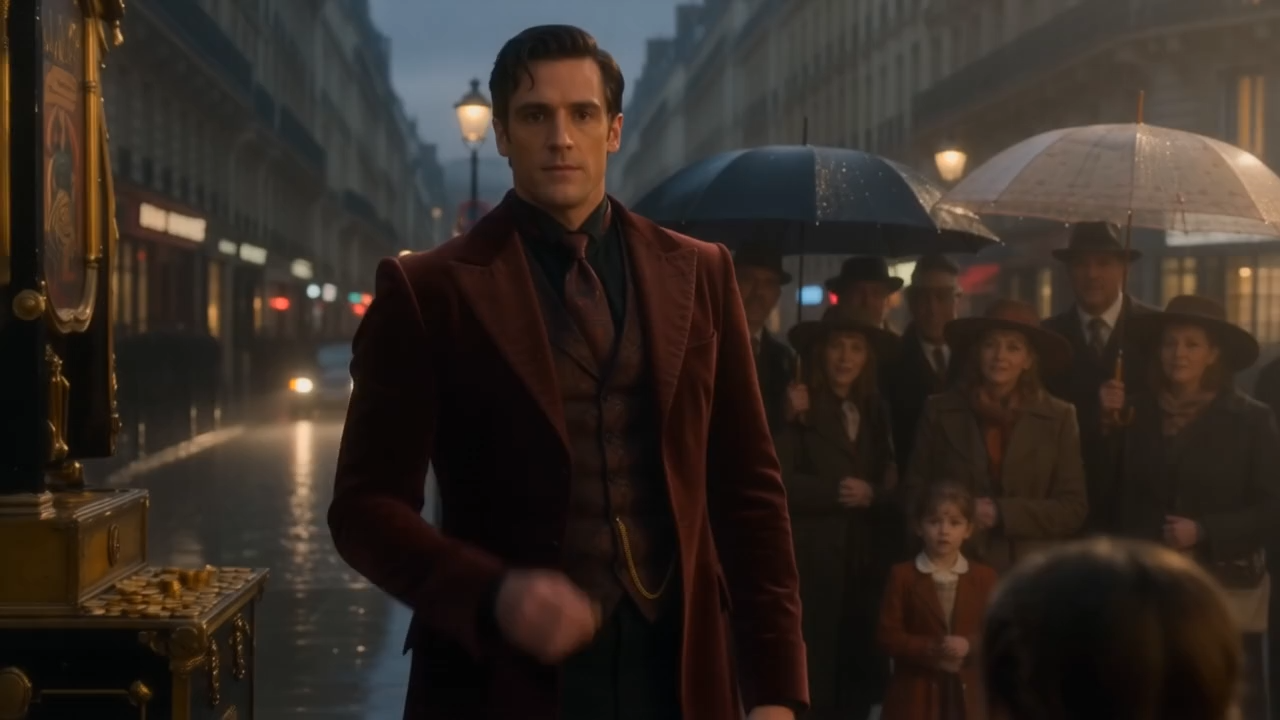
text-to-video
pixverse / pixverse-c1 / text-to-video
PixVerse C1 generates film-grade videos from text prompts with flexible duration (1-15s), multiple resolutions up to 1080p, and optional native audio generation. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

text-to-audio
minimax / music-cover
MiniMax Music Cover transforms existing songs into completely different styles — new arrangement, new vocal character, same melody. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
bytedance / seedance-2.0 / image-to-video-turbo
Seedance 2.0 (Image-to-Video Turbo) generates cinematic 720p/1080p videos from reference images —delivering high-resolution output at near-480p speed with native audio-visual synchronization, director-level control, and exceptional motion stability.

text-to-video
bytedance / seedance-2.0 / text-to-video-turbo
Seedance 2.0 (Text-to-Video Turbo) generates cinematic 720p/1080p videos from text prompts —delivering high-resolution output at near-480p speed with native audio-visual synchronization, director-level control, and exceptional motion stability.

image-to-video
bytedance / seedance-2.0-fast / image-to-video-turbo
Seedance 2.0 Fast (Image-to-Video Turbo) generates cinematic 720p/1080p videos from reference images using speed-optimized inference —the fastest and most affordable Seedance image-to-video option with native audio-visual synchronization and director-level control.

text-to-video
bytedance / seedance-2.0-fast / text-to-video-turbo
Seedance 2.0 Fast (Text-to-Video Turbo) generates cinematic 720p/1080p videos from text prompts using speed-optimized inference —the fastest and most affordable Seedance option with native audio-visual synchronization and director-level control.
audio-to-audio
wavespeed-ai / omnivoice / voice-clone
OmniVoice Voice Clone clones any voice from a short 3-10 second audio sample. Supports 600+ languages with zero-shot voice cloning. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.
text-to-audio
wavespeed-ai / omnivoice / text-to-speech
OmniVoice is a massively multilingual zero-shot TTS supporting 600+ languages. Generate speech with auto voice or design custom voices using natural language descriptions. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / ai-virtual-outfit-tryon
AI Virtual Outfit Try-On generates videos of a person wearing uploaded clothing. Upload a portrait and clothing images, add an optional prompt, and get a try-on video. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / ai-parkour-video
AI Parkour Video generates dynamic parkour action videos from a portrait image. Choose from 6 parkour styles or provide a reference video. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / ai-video-ads
AI Video Ads generates product advertisement videos. Provide a person photo, product name, and optional product image or script, and AI creates a professional ad video. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / ai-talking-photos
AI Talking Photos brings your photos to life — upload a portrait and text, and watch the person speak. Supports 5-15 seconds duration. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ai-travel-trends
AI Travel Trends generates stunning travel-style photos at 30 iconic destinations worldwide. Upload a photo, write a prompt, pick a destination — Paris, Tokyo, Bali, New York, and more. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ai-breast-expansion
AI Breast Expansion transforms portrait photos with an exaggerated breast enlargement effect. Upload a photo and get an entertaining result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ai-instagram-model
AI Instagram Model generates stunning Instagram-style photos from your image and prompt. Choose from 10 style presets — influencer, street fashion, beach, fitness, luxury, casual chic, night glam, anime, cyberpunk, and vintage retro. Ready-to-use REST inference API, no coldstarts, affordable pricing.
text-to-audio
minimax / music-2.6
MiniMax Music 2.6 generates complete songs with vocals and instrumentals from text prompts and lyrics. Supports instrumental-only mode, auto lyrics generation, structure tags for song arrangement, and configurable audio quality. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / joyai-image / edit
JoyAI Image Edit transforms images based on text instructions, allowing you to modify backgrounds, adjust colors, add or remove elements, and more. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
vidu / q3 / reference-to-video
Vidu Q3 Reference-to-Video Mix generates multi-entity consistent videos from 1-4 reference images with text prompt guidance. Supports 360p to 1080p resolutions, up to 16 seconds duration, multiple aspect ratios, and optional audio generation. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
ideogram-ai / ideogram-v3 / generate-transparent
Ideogram V3 Generate Transparent creates high-quality images with transparent backgrounds from text prompts, perfect for logos, stickers, and design assets. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-image
ideogram-ai / ideogram-v3 / remove-text
Ideogram V3 Layerize Text separates flat graphic images into editable layers, extracting text and background for professional design workflows. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

digital-human
sync / lipsync-3
Sync Lipsync 3 synchronizes lip movements in any video to supplied audio using zero-shot lip-sync technology. Supports multiple sync modes for handling duration mismatches, works with live-action, 3D characters, and AI-generated avatars. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-text
kwaivgi / kling-elements-advanced
Kling Advanced Elements creates custom AI elements from reference images or videos for consistent character and object appearance across Kling video generations. Supports multi-image elements with frontal and reference images, video character elements, and optional voice binding. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
bytedance / seedance-2.0-fast / image-to-video
Seedance 2.0 Fast (Image-to-Video) generates cinematic videos from reference images and text prompts with native audio-visual synchronization, director-level control, and exceptional motion stability — optimized for faster generation at lower cost. Built on Seed's unified multimodal architecture.

text-to-video
bytedance / seedance-2.0-fast / text-to-video
Seedance 2.0 Fast (Text-to-Video) generates cinematic videos from text prompts with native audio-visual synchronization, director-level camera and lighting control, and exceptional motion stability — optimized for faster generation at lower cost. Built on Seed's unified multimodal architecture.

image-to-video
bytedance / seedance-2.0 / image-to-video
Seedance 2.0 (Image-to-Video) generates Hollywood-grade cinematic videos from reference images and text prompts with native audio-visual synchronization, director-level camera and lighting control, and exceptional motion stability. Built on Seed's unified multimodal architecture, it preserves the input image's subject and composition while adding expressive, physically accurate motion.

text-to-video
bytedance / seedance-2.0 / text-to-video
Seedance 2.0 (Text-to-Video) generates Hollywood-grade cinematic videos from text prompts with native audio-visual synchronization, director-level camera and lighting control, and exceptional motion stability. Built on Seed's unified multimodal architecture, it leads on instruction adherence, motion quality, and visual aesthetics.

video-extend
alibaba / wan-2.7 / video-extend
WAN 2.7 Video Extend extends existing videos with optional last frame control and audio support, supporting 720p/1080p output. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

video-to-video
alibaba / wan-2.7 / video-edit
WAN 2.7 Video Edit performs prompt-driven video editing with multi-image reference support, supporting 720p/1080p output. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
google / veo3.1-lite / start-end-to-video
Google Veo 3.1 Lite Start-End-to-Video generates high-fidelity videos by interpolating between a start image and an optional end image. Supports 720p and 1080p resolutions, landscape and portrait aspect ratios, and native audio generation. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-video
google / veo3.1-lite / text-to-video
Google Veo 3.1 Lite Text-to-Video generates high-fidelity 720p or 1080p videos with natively generated audio from text prompts. Lightweight variant optimized for cost efficiency. Supports landscape and portrait aspect ratios, dialogue with lip-sync, and customizable duration. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
google / veo3.1-lite / image-to-video
Google Veo 3.1 Lite Image-to-Video transforms static images into high-fidelity 720p or 1080p videos with natively generated audio. Supports many interpolation use cases, landscape and portrait aspect ratios, and customizable duration. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

video-effects
wavespeed-ai / vace-video-joiner
VACE Video Joiner seamlessly joins multiple video clips into one using AI-powered transition generation. Upload 2 to 4 videos and get a smoothly joined result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / image-face-blur
AI Image Face Blur automatically detects and blurs faces in images for privacy protection. Upload an image and get a result with all faces blurred. Ready-to-use REST inference API, no coldstarts, affordable pricing.

video-to-video
wavespeed-ai / video-converter
AI Video Converter converts videos between formats. Upload a video and specify the target format to get a converted result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

audio-to-audio
wavespeed-ai / audio-converter
AI Audio Converter converts audio files between formats. Upload an audio file and specify the target format to get a converted result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / image-converter
AI Image Converter converts images between formats. Upload an image and specify the target format to get a converted result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
alibaba / wan-2.7 / image-edit
WAN 2.7 Image Edit performs prompt-driven image editing with support for multiple-image references. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
alibaba / wan-2.7 / image-edit-pro
WAN 2.7 Image Edit Pro performs prompt-driven image editing with multi-image reference support and up to 2K output. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
alibaba / wan-2.7 / text-to-image-pro
WAN 2.7 Text-to-Image Pro generates high-quality images up to 4K from text prompts with thinking mode for enhanced image quality. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
alibaba / wan-2.7 / text-to-image
WAN 2.7 Text-to-Image generates high-quality images from text prompts with thinking mode for enhanced image quality. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
alibaba / wan-2.7 / reference-to-video
WAN 2.7 Reference-to-Video turns character, prop, or scene references from images or videos into new video shots with preserved identity, style, and layout plus smooth, coherent motion. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
alibaba / wan-2.7 / image-to-video
WAN 2.7 converts images into videos (720p/1080p) with optional audio, supporting first and last frame control. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-video
pixverse / pixverse-v6 / transition
PixVerse V6 Transition creates smooth AI-generated video transitions between a start image and an optional end image. Supports 360p to 1080p resolutions, 1-15 second duration, multiple aspect ratios, optional audio generation, and multi-clip mode. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-video
alibaba / wan-2.7 / text-to-video
WAN 2.7 Text-to-Video turns plain prompts into coherent, cinematic clips with crisp detail, stable motion, and strong instruction-following—great for ads, explainers, and social posts. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

video-extend
pixverse / pixverse-v6 / extend
PixVerse V6 Extend continues and enhances existing video content by analyzing the ending segment and generating new frames forward. Supports 360p to 1080p resolutions, 1-15 second extension duration, optional audio generation, and multiple styles. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
pixverse / pixverse-v6 / image-to-video
PixVerse V6 generates high-quality videos from images with flexible duration (1-15s), multiple resolutions up to 1080p, and optional audio generation. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

text-to-video
pixverse / pixverse-v6 / text-to-video
PixVerse V6 generates high-quality videos from text prompts with flexible duration (1-15s), multiple resolutions up to 1080p, and optional audio generation. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

upscaler
wavespeed-ai / phota / enhance
Phota Enhance improves image quality and detail. Supports batch enhancement up to 4 images with JPEG, PNG, or WebP output. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / phota / edit
Phota Edit transforms existing images using natural language instructions. Supports up to 10 reference images, 1K and 4K resolutions, and batch output up to 4 images. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-image
wavespeed-ai / phota / text-to-image
Phota Text-to-Image generates high-quality personalized photographs from text prompts. Supports 1K and 4K resolutions, multiple aspect ratios, and batch generation up to 4 images. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
x-ai / grok-imagine-video / reference-to-video
X-AI Grok Imagine Video Reference-to-Video generates videos from multiple reference images with preserved identity, style, and scene composition. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

video-extend
x-ai / grok-imagine-video / video-extend
X-AI Grok Imagine Video Extend turns short clips into longer videos with smooth motion continuity and natural scene extension. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-video
wavespeed-ai / davinci-magihuman / text-to-video
daVinci MagiHuman Text-to-Video API — a 15B parameter omni video generation model, the new open-source king on par with WAN 2.5. Generates high-quality AI videos from text prompts with optional audio input. Supports digital humans, talking heads, flexible aspect ratios, durations, and resolutions. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / davinci-magihuman / image-to-video
daVinci MagiHuman Image-to-Video API — a 15B parameter omni video generation model, the new open-source king on par with WAN 2.5. Generates high-quality AI videos from reference images with optional audio input. Supports digital humans, talking heads, and general video generation. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

text-to-audio
google / lyria-3-clip / music
Google Lyria 3 Clip generates novel music tracks from text prompts and optional image input. Produces complete songs with lyrics, descriptions, and audio output. Supports negative prompts and seed control for reproducible results. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.
text-to-audio
google / lyria-3-pro / music
Google Lyria 3 Pro generates high-quality music tracks from text prompts and optional image input. Pro tier delivers enhanced audio quality and richer compositions. Produces complete songs with lyrics, descriptions, and audio output. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ai-smile-filter
AI Smile Filter adds a natural smile to any portrait. Upload a face photo and get an instant smiling result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ai-girl-filter
AI Girl Filter transforms a portrait into a cute girl style. Upload a face photo and get an instant result. Ready-to-use REST inference API, no coldstarts, affordable pricing.
video-to-audio
mirelo-ai / sfx-v1 / video-to-audio
Mirelo SFX V1 Video-to-Audio generates synchronized sound effects from video input with text prompt guidance. Supports multiple sample generation and customizable duration. Ready-to-use REST inference API, best performance, no coldstarts, affordable pricing.

video-to-video
wavespeed-ai / video-fps-increaser
AI Video FPS Increaser doubles your video frame rate for smoother motion and better playback quality. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-image
wavespeed-ai / ai-photo-colorizer
AI Photo Colorizer automatically adds color to black-and-white photos. Upload a grayscale image and get a colorized result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

portrait-transfer
wavespeed-ai / video-body-swap
Video Body Swap replaces the body in a target video with your face. Upload a face image and a body video to get a seamless swap. Ready-to-use REST inference API, no coldstarts, affordable pricing.

portrait-transfer
wavespeed-ai / image-body-swap
Image Body Swap replaces the body in a target image with your face. Upload a face image and a body image to get a seamless swap. Ready-to-use REST inference API, no coldstarts, affordable pricing.

audio-to-audio
wavespeed-ai / audio-vocal-isolator
AI Vocal Remover separates vocals from instrumental in any audio track. Upload an audio file and choose to extract vocals or instrumental. Ready-to-use REST inference API, no coldstarts, affordable pricing.

video-to-video
wavespeed-ai / rife
RIFE Video Interpolation generates smooth intermediate frames between existing video frames for higher frame rates and smoother motion. Ready-to-use REST inference API, best performance, no cold starts, affordable pricing.

image-to-image
wavespeed-ai / ai-gender-swap
AI Gender Swap transforms a portrait to show how you would look as the opposite gender. Upload a face photo and get an instant result. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-video
wavespeed-ai / ghibli-filter / video
AI Ghibli Filter Video transforms a photo into a Studio Ghibli anime style video with customizable duration. Ready-to-use REST inference API, no coldstarts, affordable pricing.

image-to-image
wavespeed-ai / ghibli-filter / image
AI Ghibli Filter transforms a photo into Studio Ghibli anime style. Upload an image and get a Ghibli-style result. Ready-to-use REST inference API, no coldstarts, affordable pricing.