Direkt zu OpenAI oder eine Plattform für GPT-5.5?
Sollten Teams GPT-5.5 direkt über OpenAI nutzen oder über eine Modellplattform? Vergleich von Rollout-Geschwindigkeit, Fallback, Routing und operativer Kontrolle.

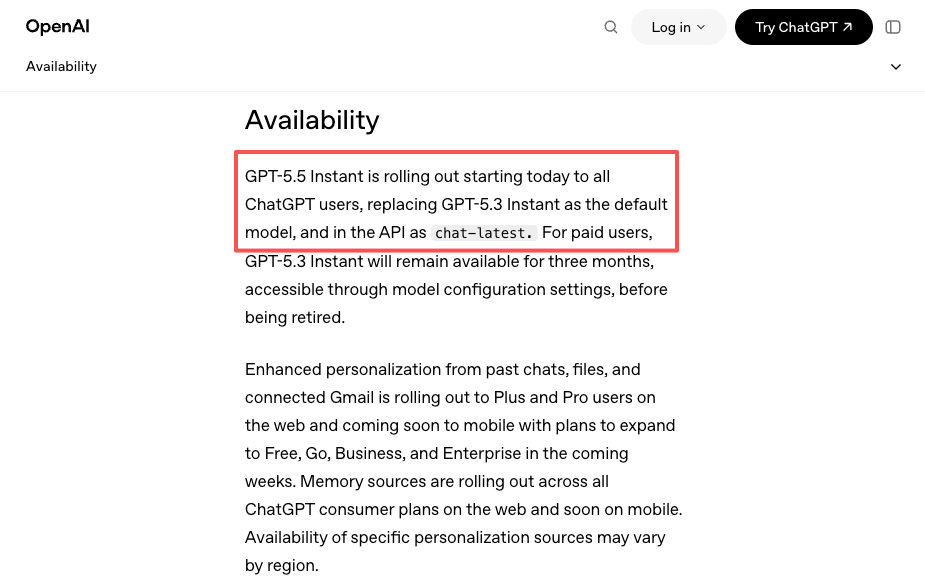
GPT-5.5 wurde am 23. April in ChatGPT und Codex veröffentlicht. Die API folgte einen Tag später, am 24. April. Am 5. Mai wurde GPT-5.5 Instant dann das Standard-ChatGPT-Modell und gelangte als chat-latest in die API. Drei verschiedene Rollout-Momente innerhalb von zwei Wochen, jeweils mit unterschiedlicher Tier-Berechtigung und unterschiedlichen Oberflächen.
Hier ist Dora. Ich habe das verfolgt, weil ich es musste. Ein Workflow von mir berührt GPT-5-Modelle, und die 24-stündige API-Lücke zwischen dem ChatGPT-Release und dem API-Release war für mich nicht theoretisch. Es bedeutete entweder warten oder über etwas routen, das bereits Zugang hatte. Diese Entscheidung — warten oder routen — ist dieselbe Entscheidung, die jedes Team, das ein Frontier-Modell nutzt, bei jedem Release treffen muss. Darum geht es in diesem Beitrag.
Die Frage ist nicht „Ist OpenAI gut?”. Die Frage ist: Wenn GPT-5.5 (oder was auch immer als Nächstes kommt) stufenweise ausgerollt wird, rufst du OpenAI direkt an, oder sitzt du hinter einer Plattform, die das Staging für dich übernimmt? Beide Antworten sind für verschiedene Teams richtig. Im Folgenden zeige ich, was ich sehe, wenn ich es ehrlich betrachte.
Die zwei Wege, wie Teams auf GPT-5.5 zugreifen werden
Direkter Provider-Zugang
Du triffst api.openai.com mit einem OpenAI-Schlüssel. Ein SDK, ein Satz Dokumentation, eine Rechnung. Wenn OpenAI einen neuen Modellnamen ausliefert, änderst du einen String in deiner Konfiguration und verwendest ihn — vorausgesetzt, dein Tier hat am ersten Tag Zugang.
Die Preise findest du auf der offiziellen OpenAI-Preisseite: GPT-5.5 zu 5 $/M Eingabe und 30 $/M Ausgabe, GPT-5.5 Pro zu 30 $/M Eingabe und 180 $/M Ausgabe. Ungefähr das Doppelte von GPT-5.4. Du zahlst direkt an OpenAI.
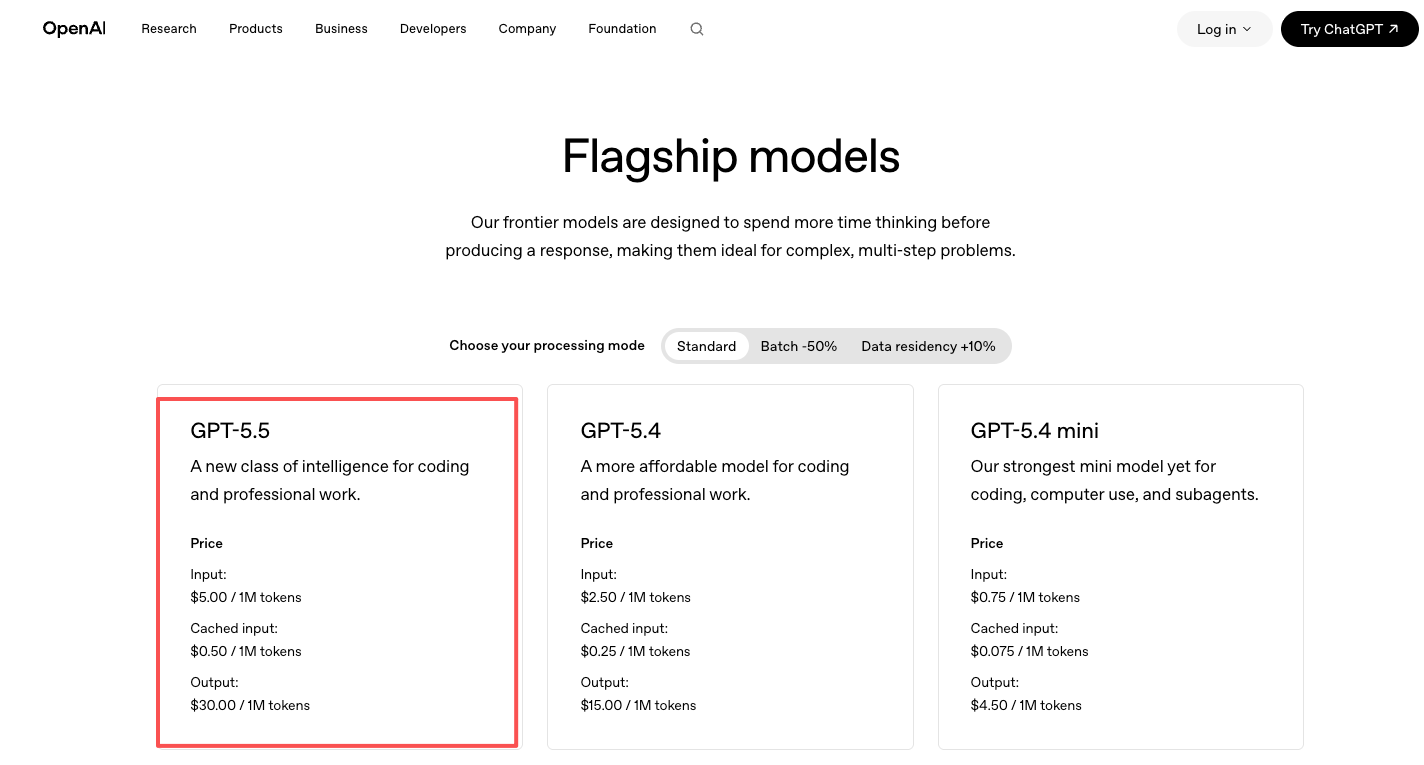
Zugang über eine Modellplattform
Du triffst eine Routing-Schicht — OpenRouter, LiteLLM, ein internes Gateway oder eine Multi-Modell-Plattform — und diese Schicht spricht in deinem Auftrag mit OpenAI. Dieselbe OpenAI-SDK-Form (die meisten Plattformen sind OpenAI-kompatibel), aber der Modell-String kann auf GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro oder eine Fallback-Kette über alle drei verweisen.
Du zahlst die Plattform. Die Plattform zahlt OpenAI. Es gibt einen kleinen Aufschlag, manchmal keinen. Im Gegenzug erhältst du eine Rechnung über alle Provider hinweg, Modellwechsel ohne Code-Änderungen und einen Fallback-Pfad, wenn etwas kaputt geht.
Das ist das gesamte Bild. Keine Option ist „besser”. Sie optimieren für verschiedene Dinge.
Wo direkter Zugang gewinnt
Einfachheit, geringere Abstraktion und Provider-spezifische Optimierung
Wenn du nur OpenAI-Modelle verwendest, ist der direkte Aufruf bei OpenAI die einfachst mögliche Architektur. Ein Anbieter. Ein Satz Fehlercodes. Eine Statusseite zum Beobachten. Wenn etwas kaputt geht, weißt du, wen du fragen musst.
Es ist auch wichtig, dass OpenAI Funktionen ausliefert, die nicht immer sofort über Abstraktionsschichten verfügbar sind. Responses API. Reasoning-Effort-Steuerung. Strukturierte Ausgaben mit strengen Schemas. Die Codex-Tool-Oberfläche. Provider-spezifische Tool-Calling-Formate. Eine Plattformschicht holt schließlich auf, aber „schließlich” kann Wochen bedeuten. Wenn dein Produkt am ersten Tag von einer bestimmten OpenAI-Funktion abhängt, ist der direkte Weg der einzige Weg.
Es gibt auch einen echten Kostenfaktor bei Indirektion, über den niemand spricht. Jede Schicht zwischen deinem Code und dem Modell ist ein weiterer Ort, an dem etwas schiefgehen kann, eine weitere Statusseite eines Teams, die überwacht werden muss, eine weitere Abrechnungsüberraschung am Monatsende. Für ein kleines Team, das ein Modell in der Produktion betreibt, kann dieser Overhead den Nutzen überwiegen.
Wenn ein Modell ausreicht
Viele Teams brauchen wirklich nur ein Modell. Sie haben vor einem Jahr GPT-5 gewählt, der Workflow funktioniert, die Prompts sind abgestimmt, die Evals sind stabil. Sie wollen nicht gegen Claude A/B-testen. Sie wollen nicht zu Gemini failovern. Sie wollen, dass das Modell weiter funktioniert und die Rechnung weiter vorhersehbar ist.
Für dieses Team löst eine Routing-Schicht ein Problem, das sie nicht haben. Direkter Zugang ist die richtige Antwort, und eine Plattform darüber zu legen ist die falsche. Zahle keine Komplexitätssteuer für Optionalität, die du nicht nutzen wirst.
Wo eine Modellplattform gewinnt
Rollout-Geschwindigkeit, Fallback und Routing-Kontrolle
Hier hat der GPT-5.5-Zeitplan tatsächlich eine Rolle gespielt. Zwischen dem 23. und 24. April war GPT-5.5 in ChatGPT live, aber nicht in der API. CNBC berichtete damals, dass OpenAI „unterschiedliche Schutzmaßnahmen” für den API-Rollout ankündigte, ohne ein verbindliches Datum zu nennen. Für die meisten Teams war diese 24-stündige Lücke nichts. Für einige wenige — jeder mit einem vertraglichen „Wir liefern das neueste Modell innerhalb von X Stunden” — war es ein Problem.
Eine Plattformschicht macht OpenAI nicht schneller. Aber sie verändert, wie „Warten” aussieht. Während GPT-5.5 noch nicht in der OpenAI-API war, war Claude Opus 4.7 verfügbar. Gemini 3.1 Pro war verfügbar. Ein geroutetes Setup kann GPT-5.5 bevorzugen, sobald es verfügbar ist, auf das aktuell verfügbare Frontier-Modell zurückfallen und keinen Code-Deploy erfordern, wenn sich die Situation ändert.
Dieselbe Logik gilt für Ausfälle. OpenAI hatte dieses Jahr mehrere API-Vorfälle über mehrere Stunden. So auch jeder andere Provider. Wenn dein Produkt zwingend „ein LLM, das gerade jetzt funktioniert” benötigt, baust du den Fallback entweder selbst oder lässt eine Plattform damit umgehen. Sowohl die Fallback-Dokumentation von OpenRouter als auch die Router-Dokumentation von LiteLLM beschreiben dies in konkreter Konfiguration: primäres Modell deklarieren, Fallbacks auflisten, eine funktionierende Antwort erhalten, wenn das primäre Modell ausfällt.
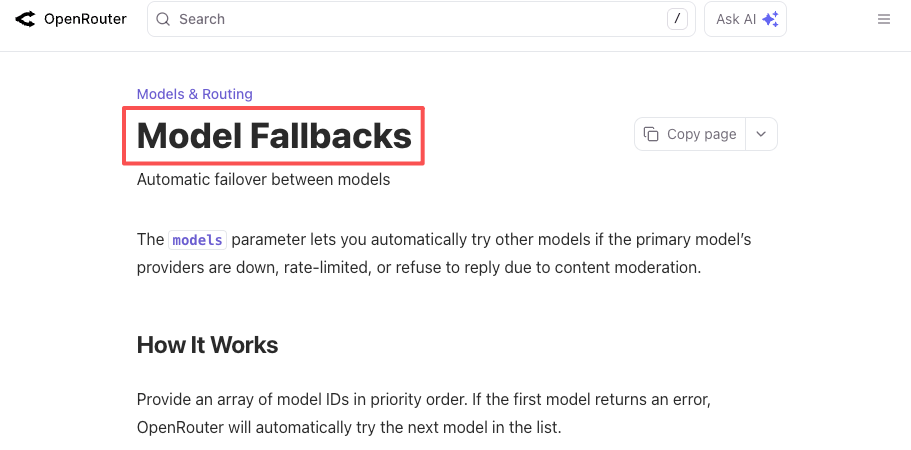
Das ist kein hypothetisches Szenario. Es ist ein Szenario, das ich in diesem Quartal zweimal erlebt habe.
Multi-Modell-Experimente und Beschaffungsresilienz
Der andere Bereich, in dem eine Plattform ihren Wert beweist, ist, wenn du noch nicht weißt, welches Modell für die Aufgabe das richtige ist — oder wenn du vermutest, dass sich diese Antwort in sechs Monaten ändern wird.
Die Führerschaft bei Frontier-Modellen rotiert auf einem Zyklus von etwa 3 bis 6 Monaten. GPT-5.5 kommt, dann kommt Anthropic, dann kommt Google, und die Antwort auf „bestes Modell für Code” oder „bestes Modell für Langkontext-Analyse” verschiebt sich ständig. Wenn du gegen das SDK eines einzelnen Providers integriert hast, bedeutet ein Wechsel echte Engineering-Arbeit. Wenn du hinter einer Routing-Schicht bist, bedeutet ein Wechsel die Änderung eines Modell-Strings.
Dieselbe Logik gilt für die Beschaffung. Eine Plattform konsolidiert die Ausgaben über mehrere Provider in einer Rechnung, einem Satz Nutzungsanalysen und einer Budgetkontrolle. Finance-Teams kümmert das mehr, als Engineering-Teams erkennen. „Wir haben einen KI-Anbieter” ist leichter zu verwalten als „Wir haben drei KI-Anbieter und die Ausgaben pro Anbieter ändern sich monatlich.”
Und dann gibt es ein weicheres Signal: Die Veröffentlichung von GPT-5.5 Instant am 5. Mai als neues ChatGPT-Standard-Modell — gedeckt durch OpenAIs eigene Ankündigung — ging als chat-latest in die API. Teams, die an diesen Alias gebunden waren, erhielten das Upgrade automatisch. Teams, die an ein bestimmtes Versionsdatum gebunden waren, nicht. Eine Plattform kann dir eine einheitliche Abstraktion über beide Verhaltensweisen hinweg über Provider geben, anstatt dass du die Versionierungsregeln jedes Providers separat verfolgen musst.
Ein Entscheidungsrahmen nach Teamtyp
Ich mag Framework-Tabellen in Blogbeiträgen nicht, weil sie vereinfachen. Aber eine grobe Heuristik hilft hier, also:
| Teamprofil | Wahrscheinlich besser geeignet | Grund |
|---|---|---|
| Solo-Entwickler, ein Modell, ein Produkt | Direkt OpenAI | Routing-Schicht verursacht Kosten, ohne ein echtes Problem zu lösen |
| Produktionsteam, nur OpenAI-Stack, abhängig von Provider-spezifischen Funktionen | Direkt OpenAI | Sofortiger Zugang zu Responses API, strukturierten Ausgaben usw. |
| Produktionsteam, Multi-Modell in Evals, plant multi-modell zu bleiben | Plattform | Wechselkosten sind die dominante Variable |
| Team mit striktem Uptime-SLA für eine LLM-gestützte Funktion | Plattform | Fallback-Ketten sind die günstigste Versicherung |
| Team, das interne Tools betreibt, nicht kundenorientiert | Beides | Wähle das mit weniger Ops-Overhead für dich |
| Unternehmen mit Beschaffung, Sicherheitsüberprüfung pro Anbieter | Plattform | Ein Vertrag schlägt N Verträge |
| Forschungs-/Experimentierteam, das Frontier-Modelle vergleicht | Plattform | Modellwechsel ist der gesamte Workflow |
| Team, das sofortigen Zugang zu brandneuen Modellversionen benötigt | Plattform mit Day-Zero-Abdeckung oder direkter Provider mit hohem Tier | Beides funktioniert, aber Tier-Berechtigung ist wichtiger als die meisten denken |
Die Tabelle ist kein Urteil. Sie ist eine Ausgangsfrage: Welche Zeile ist meinem Team am nächsten, und was impliziert das für meine Standard-Architektur?
FAQ

Wann ist eine direkte OpenAI-Integration ausreichend?
Wenn du dich bereits für OpenAI entschieden hast, dein Nutzungsvolumen nicht groß genug ist, um einen separaten Plattformvertrag zu rechtfertigen, und du keinen expliziten Bedarf an einem Fallback zu einem anderen Provider hast. Die meisten kleinen und mittelgroßen Teams, die OpenAI-Workloads in der Produktion betreiben, fallen hier hinein.
Warum würden Teams eine Modellplattform darüber legen?
Die drei häufigsten Gründe: Multi-Modell-Routing ohne Code-Änderungen, Fallback bei Ausfällen oder Partial-Rollouts und konsolidierte Abrechnung über Provider hinweg. Wenn keiner davon gerade auf dich zutrifft, brauchst du es wahrscheinlich gerade nicht.
Hilft eine Plattform bei Partial-Launches?
Ja — aber nur für das Fehlermuster „Ich brauche ein funktionierendes Frontier-Modell, und das, das ich bevorzuge, ist noch nicht verfügbar.” Sie hilft nicht, wenn du speziell GPT-5.5 und nur GPT-5.5 benötigst. Eine Plattform kann zum besten verfügbaren Modell aus einer Liste routen. Sie kann keinen Zugang zu einem Modell zaubern, das OpenAI noch nicht ausgeliefert hat.
Welche Kompromisse bringt eine weitere Schicht mit sich?
Du fügst einen Anbieter zwischen dich und das Modell ein. Das bedeutet eine weitere Statusseite, eine weitere Abrechnungsoberfläche, einen weiteren potenziellen Fehlerpunkt, manchmal einen kleinen Aufschlag und gelegentlich eine Verzögerung bei Provider-spezifischen Funktionen. Keiner davon ist ein Dealbreaker. Es sind echte Kosten, die du einkalkulieren solltest.
Fazit
Die ehrliche Version ist diese. Direktes OpenAI ist für viele Teams die richtige Antwort — wahrscheinlich mehr, als die Plattform-Evangelisten zugeben. Eine Modellplattform ist für viele andere Teams die richtige Antwort — wahrscheinlich mehr, als die OpenAI-only-Fraktion zugeben. Die Aufteilung ist nicht ideologisch. Es geht darum, wie viele Modelle du tatsächlich nutzt, wie sehr deine Uptime-Geschichte vom LLM abhängt und wie viele Wechselkosten du verkraften kannst, wenn das nächste Frontier-Modell erscheint.
Der GPT-5.5-Rollout war ein nützlicher Stresstest, weil er drei Momente in zwei Wochen hatte: ChatGPT zuerst, API einen Tag später, Instant-Variante zwölf Tage danach. Jedes Team, das ein Frontier-Modell nutzt, wird dieses Muster immer wieder durchleben. Es lohnt sich, sich jetzt, an einem ruhigen Tag, zu entscheiden, welche Architektur man beim nächsten Mal in der Hand haben möchte.
Rechne die Zahlen gegen dein eigenes Setup. Das sagt dir mehr als dieser Beitrag.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
