Claude Opus 4.7: Why AI Teams Need a Unified Model API Layer
Claude Opus 4.7 is nearly here. Here's why frequent model drops expose the real cost of direct API integrations—and what AI teams are doing about it.

The conclusion first: the hardest part of Claude Opus 4.7 isn’t the model. It’s the migration.
I — Dora — run AI generation pipelines for production content. Images, video, multi-model orchestration. When Anthropic dropped Opus 4.6 in February, my team spent four days re-validating prompts, adjusting token budgets, and fixing one billing discrepancy that didn’t surface until day three. Now, barely two months later, Anthropic has released Opus 4.7 with a new tokenizer, breaking API changes, and a new effort level. If you’re the person on your team who maintains the model integration layer, you already feel the weight of that sentence.
This piece documents what’s confirmed about Opus 4.7 so far, what the upgrade treadmill actually costs engineering teams, and when the math starts favoring an aggregation layer over direct provider APIs.

What We Know About Claude Opus 4.7 (And What’s Still Unconfirmed)
The information: confirmed vs. rumored
Opus 4.7 went generally available on April 16, 2026. The model ID is claude-opus-4-7. Pricing stays at $5 per million input tokens and $25 per million output tokens — same as Opus 4.6. The 1M token context window is unchanged. Max output remains 128k tokens.
What did change: high-resolution vision support up to 3.75 megapixels (more than triple the 1.15 MP limit on 4.6), a new xhigh effort level between high and max, and task budgets for agentic loops — a beta feature that gives the model a token countdown across an entire multi-turn workflow.
The breaking changes matter more than the features. Extended thinking budgets are removed. Sampling parameters are gone. The new tokenizer processes the same text into roughly 1.0–1.35x more tokens depending on content type. Per-token price is flat, but your actual bill can rise up to 35% without you changing a single prompt.
What changed from Opus 4.6 to 4.7 — why it matters for builders
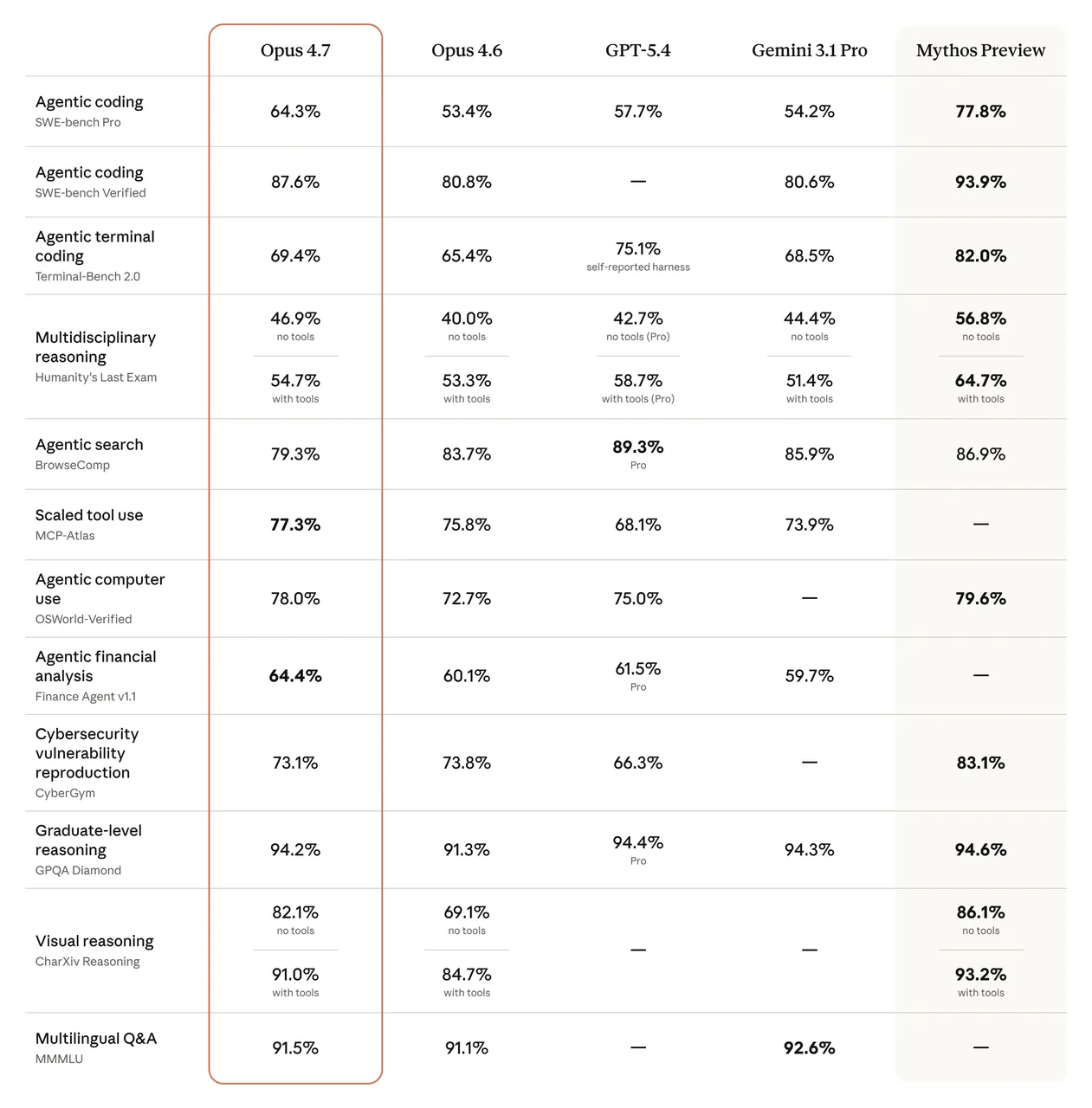
The benchmark numbers are real. SWE-bench Verified went from 80.8% to 87.6%. CursorBench jumped from 58% to 70%. On SWE-bench Pro, Opus 4.7 scores 64.3% — up from 53.4% on 4.6 and ahead of GPT-5.4 at 57.7%.
But here’s the part that actually affects production teams: Opus 4.7 follows instructions more literally. Prompts that were “loose” or conversational with 4.6 may produce rigid or unexpected results. If you’ve spent weeks tuning prompt libraries, that behavioral shift means re-testing — not just swapping a model string.
The Real Problem Isn’t the New Model — It’s the Upgrade Treadmill
What “a new Claude every month” actually costs an engineering team
Anthropic shipped Opus 4.5 in November 2025. Opus 4.6 in February 2026. Opus 4.7 in April 2026. That’s three major model versions in five months. Each one brought parameter changes, behavioral shifts, or breaking API updates.
The engineering cost of each upgrade isn’t the model swap. It’s the validation loop. Prompt regression testing. Token budget recalibration. Billing projection updates. Integration smoke tests across staging and production. For my workflows, each migration eats three to five engineering-days — and that’s for a team that’s done it before.
Versioning risk: when your prompts break after a model update
The migration guide for Opus 4.7 is transparent about this. The updated tokenizer means /v1/messages/count_tokens returns different numbers for the same input. If your system has hard-coded max_tokens limits, they may now clip output prematurely. If you relied on prefill or sampling parameters, those are gone.
I’ve seen teams treat model upgrades like dependency bumps — change the version string, run the tests, ship it. That approach stopped working around Opus 4.5.
Who bears the most pain: direct API vs. aggregation layer teams
Teams calling Anthropic’s API directly absorb every breaking change themselves. Teams behind an aggregation layer — a middleware that normalizes provider APIs into a single interface — absorb it once, centrally. The difference compounds. Three provider upgrades per year across two or three providers means six to nine migration events. Aggregation layers turn that into a configuration update.
This isn’t hypothetical. I maintain integrations with multiple model providers. The ones routed through a unified layer took hours to update. The direct ones took days.
How AI Product Teams Are Structuring Model Access in 2026
Direct provider API: when it still makes sense
Direct API wins when you need day-zero access to new features, when your workload exploits provider-specific capabilities (like Opus 4.7’s task budgets), or when you’re deep enough into one provider that switching cost is effectively zero because you’re not switching.
If your entire product is built on Claude and only Claude, and you have the engineering bandwidth to absorb quarterly breaking changes, direct API is still the straightforward path.
Aggregation layer: when the switch-cost math flips
The inflection point is multi-model usage combined with frequent provider updates. Once you’re calling Claude for reasoning, a different model for classification, and a third for embeddings — and each provider ships breaking changes on its own schedule — the coordination overhead starts eating real engineering time.
According to Gartner’s forecast, roughly 40% of enterprise applications will embed task-specific AI agents by end of 2026. Each agent may call a different model. Managing that through direct provider APIs isn’t wrong — it’s just expensive in a way that shows up as engineer-hours, not on an invoice.
The evaluation checklist before migrating to any new Claude version
Before swapping claude-opus-4-6 for claude-opus-4-7 in production, there’s a short list I run through: tokenizer impact testing (run your actual prompts through count_tokens on both versions and compare), prompt behavior regression (the literal-instruction change will surface here), billing projection update (the 1.0–1.35x token increase is content-dependent — measure it on your data, not Anthropic’s averages), and feature dependency audit (check if you’re using anything that’s been removed or changed).
If your team can’t do this in under a day, that’s a signal about your architecture, not about the model.
What to Watch After Opus 4.7 Officially Drops
API availability timeline and access tiers
Opus 4.7 is already live across Claude’s API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Claude Pro, Max, Team, and Enterprise plans all have access. Rate limits are pooled across Opus versions, so you can run 4.6 and 4.7 traffic side by side during migration.
Pricing vs. 4.6 — confirmed vs. speculative
The rate card is identical. $5/$25 per million tokens. Prompt caching still offers up to 90% savings; batch processing still gives 50% off. But the tokenizer change means effective cost per prompt is higher — how much higher depends on your content mix. Dense code? Expect closer to 1.35x. Short conversational prompts? Closer to 1.0x.
One thing I’m still watching: Opus 4.7’s new tokenizer reportedly handles multilingual content differently. For teams processing non-English text at scale, the token inflation could be even higher than 35%. I don’t have enough data on this yet.
Compatibility signals: context window, tool use, structured output
Context window: 1M tokens, unchanged. Tool use: same set as 4.6 — bash, code execution, computer use, text editor, web search, MCP connector. Structured output: supported. The Opus 4.7 system card notes that the model is more thorough at self-verifying outputs, which means some existing prompt scaffolding (“double-check the slide layout before returning”) can be removed.
The relationship to Claude Mythos is worth noting: Opus 4.7 is explicitly positioned as the testbed for safeguards that Anthropic eventually wants to deploy on Mythos-class models. Opus 4.7 carries automated cyber-use detection that Mythos Preview doesn’t have in the same form. This isn’t directly relevant to API integration — but it signals where Anthropic’s model roadmap is heading.
FAQ
Is Claude Opus 4.7 available via API yet?
Yes. It went generally available on April 16, 2026. The model ID is claude-opus-4-7. Available on Anthropic’s direct API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry.
How does Opus 4.7 pricing compare to Opus 4.6?
Rate card is identical: $5 per million input tokens, $25 per million output tokens. But the updated tokenizer can inflate actual token counts by up to 35%, meaning the same prompt may cost more to run on 4.7 than on 4.6.
Can I run Claude Opus 4.7 through a third-party inference API?
Yes. Multiple aggregation platforms and routing layers support Opus 4.7. The key question is whether the third-party layer exposes 4.7-specific features like task budgets and the xhigh effort level, or only passes through standard completions.
What’s the difference between Claude Opus 4.7 and Claude Mythos?
Mythos Preview is Anthropic’s most powerful model, restricted to select partners under Project Glasswing for defensive cybersecurity work. Opus 4.7 is generally available and carries automated safeguards that Anthropic is testing before eventually broadening Mythos-class access. They’re different capability tiers with different access models.
Should my team wait for Opus 4.7 or stay on 4.6 for production?
If your prompts are battle-tested on 4.6 and your system is performing well, don’t rush. Pilot 4.7 on a small slice of traffic, measure tokenizer impact and prompt behavior changes, then migrate in stages. The model is better — but the migration is not zero-effort.
I’m still running 4.6 and 4.7 in parallel on my own pipelines. The benchmark gains are real, but so is the prompt re-tuning. I’ll have more data in a week or two on whether the tokenizer overhead nets out against the efficiency gains from fewer tool calls. That part isn’t settled yet.
Previous posts:





