GLM-5V-Turbo vs GPT-4o Vision: Which Model Wins for UI Coding?
GLM-5V-Turbo vs GPT-4o Vision for design-to-code tasks. Compare capabilities, API access, pricing, and real use case fit in 2026.

Someone on my team asked me this last week: “Should we switch from GPT-4o to GLM-5V-Turbo for our design-to-code pipeline?” My first instinct was to say “test both.” My second instinct was to actually do the research first, so the test has a hypothesis going in.
Here’s what I found — covering the specific task of UI coding and frontend generation from visual input. Not general coding, not reasoning benchmarks, not a broad model review. Just the narrow question of which one you should reach for when the input is a design and the output is code.
The Short Answer
If your primary task is turning visual designs into frontend code at scale, GLM-5V-Turbo is the cheaper option and claims stronger Design2Code performance. If you need general-purpose multimodal reasoning, backend coding support, or a model with a longer track record in production, GPT-4o is the safer default.
The comparison only gets interesting when you’re specific about what you’re building.
What Each Model Is Optimized For
GLM-5V-Turbo is a native multimodal agent model from Z.ai (Zhipu AI), released April 1, 2026. It was designed around visual-first coding tasks — design reproduction, GUI navigation, and screen-to-action workflows. Vision isn’t a capability added on; it’s the center of the architecture.
GPT-4o is OpenAI’s multimodal model, released May 2024 and still widely used for production vision workloads. It handles image, text, and audio. It’s a general-purpose model that’s good at visual reasoning, but not specifically optimized for design-to-code tasks. By late 2025 it’s something of a known quantity — well-tested, stable, with broad ecosystem support.
These two models are solving adjacent but distinct problems. That’s actually the most useful thing to understand before comparing them.
Capability Comparison
Design-to-Code and UI Reproduction
This is where the gap is most pronounced. Z.ai reports GLM-5V-Turbo scored 94.8 on the Design2Code benchmark, compared to Claude Opus 4.6’s 77.3 and GPT-4o’s performance in a similar range. Design2Code measures how closely the generated HTML/CSS reproduces a reference mockup — pixel accuracy, structural fidelity, and visual completeness.
Again: these are Z.ai’s own numbers. The gap is large enough to be worth taking seriously, but not large enough to skip independent validation with your own design assets before committing.
In practice, this means GLM-5V-Turbo is worth testing for: Figma-to-code pipelines, screenshot-to-component generation, design spec reproduction across breakpoints, and UI migration workflows where a visual reference exists. Tasks where “it looked like the mockup” is the success metric.
GUI Agent Tasks
Both models support GUI agent workflows, but with different levels of native integration. GLM-5V-Turbo was built with agentic use in mind — the model handles the full “perceive → plan → execute” loop and supports tool calling with what Z.ai describes as improved invocation stability (fewer failed tool calls in agent chains). Z.ai’s documentation positions this as a core design goal, not a feature add-on.
GPT-4o can be used in GUI agent workflows but does so through OpenAI’s function calling and Responses API infrastructure. As of early 2026, GPT-4o is not the frontier choice for GUI agents — GPT-5.4 with its native Computer Use API has taken that position within OpenAI’s lineup. GPT-4o is adequate, not leading.
General Coding and Backend Tasks
This is where the comparison tips clearly in GPT-4o’s direction. GLM-5V-Turbo is a vision-specialized model. Z.ai acknowledges it trails Claude and GPT-4o in pure-text coding categories — backend logic, multi-file repository work, API integration, debugging without visual context. The model doesn’t compete in this space, and Z.ai isn’t claiming it does.
GPT-4o handles general coding tasks well, though it’s not the strongest option in the current market even from OpenAI’s own lineup. For text-only coding work, you’d likely be comparing GPT-4.1 or GPT-5.4 rather than GPT-4o anyway.
The practical takeaway: don’t use GLM-5V-Turbo for a task that doesn’t start with visual input. It’s the wrong tool.
Multimodal Understanding (Image, Video)
GLM-5V-Turbo accepts images, short video clips, and text in the same context. Video input opens up screen recording analysis, product walkthrough documentation, and temporal UI state tracking. Context window is 202,752 tokens, max output 131,072 tokens — generous for multi-image or video-frame-heavy prompts.
GPT-4o supports image input (including multiple images per request) with a 128K context window. Images consume tokens based on resolution — a 1024×1024 image in high-detail mode costs roughly 765 tokens, as documented in OpenAI’s vision guide. GPT-4o does not natively handle video as continuous input; video analysis requires frame extraction on your end.
For pipelines involving screen recordings or multi-frame visual sequences, GLM-5V-Turbo has a structural advantage here.
Side-by-Side Comparison
| Dimension | GLM-5V-Turbo | GPT-4o |
|---|---|---|
| API availability | Z.ai native API + OpenRouter | OpenAI API |
| Input pricing | $1.20 / 1M tokens | $2.50 / 1M tokens |
| Output pricing | $4.00 / 1M tokens | $10.00 / 1M tokens |
| Cached input | $0.24 / 1M tokens | $1.25 / 1M tokens |
| Context window | 202,752 tokens | 128,000 tokens |
| Max output | 131,072 tokens | ~16,384 tokens |
| Design2Code | 94.8 (Z.ai self-reported) | Not independently benchmarked for this task |
| Pure-text coding | Weaker — trails frontier text models | Solid general-purpose performance |
| Agentic workflow | Native design, tool-call focus | Capable via function calling; not the current frontier |
| Video input | Yes — native | No — requires frame extraction |
| Track record | Released April 2026 | In production since May 2024 |
GPT-4o pricing from OpenAI’s official API pricing page. GLM-5V-Turbo pricing from Z.ai’s official pricing documentation. Verify both before production budget planning — pricing has shifted with each model generation on both platforms.
API and Pricing Comparison
GLM-5V-Turbo Pricing and Access
$1.20 per million input tokens, $4.00 per million output tokens. Accessible via Z.ai’s OpenAI-compatible API or through OpenRouter for multi-provider routing. Standard API key setup, function calling supported, streaming supported.
One thing worth noting: Z.ai has had infrastructure strain with previous model launches. GLM-4.7’s launch saw capacity throttling; GLM-5 launched with a 30% price increase alongside compute pressure warnings. GLM-5V-Turbo is newly released — test throughput under realistic load before committing a production pipeline to it.
GPT-4o Pricing and Access
$2.50 per million input tokens, $10.00 per million output tokens, cached input at $1.25 per million. Available via OpenAI’s API with strong rate limit documentation, enterprise agreements, and two years of production stability. The infrastructure story here is mature — you know what you’re getting.
Cost Per Task Estimate for UI Coding Workflows
For a typical design-to-code task (~1,500 image + prompt tokens in, ~2,000 tokens out):
- GLM-5V-Turbo: ~$0.004 per task
- GPT-4o: ~$0.027 per task
That’s roughly a 6–7x difference. At 10,000 tasks per month: ~$40 vs ~$270. Significant at scale; irrelevant for low-volume evaluation.
When to Use GLM-5V-Turbo
Design → Frontend Code Pipelines
If your workflow starts with a design artifact — Figma export, screenshot, wireframe — and ends with HTML, CSS, or a component scaffold, GLM-5V-Turbo is worth benchmarking against your current solution. The Design2Code numbers are self-reported but directionally credible. The cost per task is meaningfully lower. And the architecture is purpose-built for this use case rather than adapted from a general model.
Low-Cost Visual Coding Tasks
For teams running high-volume, image-in-code-out pipelines — design system generation, batch UI reproduction, style extraction from screenshots — the cost differential adds up. At $1.20/$4.00, GLM-5V-Turbo is cheaper than GPT-4o on both ends.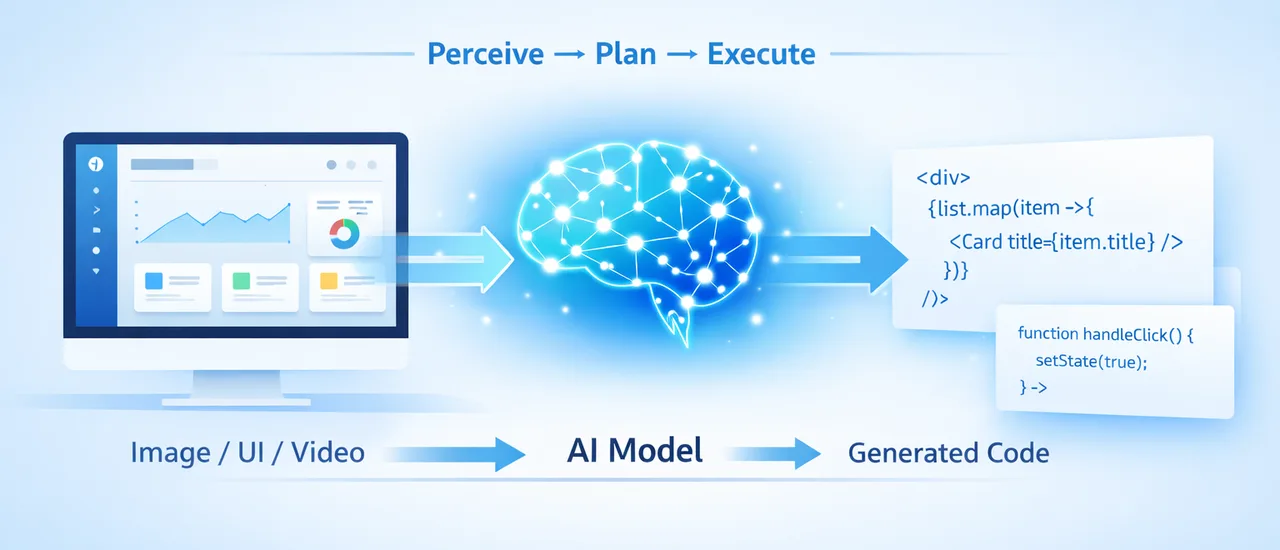
When to Use GPT-4o Vision
General-Purpose Multimodal Reasoning
GPT-4o is the better choice when visual coding is one part of a broader workflow — image analysis, mixed reasoning, document understanding, or tasks where the visual input is context rather than the primary subject. It’s more general and more reliable outside the specific design-to-code niche.
Established API Ecosystem and Stability
Two years of production use translates to well-tested rate limits, established error handling patterns, and a large body of community knowledge. If your team is already integrated with OpenAI’s ecosystem — using their SDKs, monitoring tools, or compliance infrastructure — staying on GPT-4o for vision tasks carries lower switching cost than it might appear.
Decision Framework
Choose by Task, Not by Benchmark Ranking
The mistake most teams make when comparing models is treating benchmark rankings as a proxy for fit. GLM-5V-Turbo’s Design2Code score doesn’t mean it’s a better model — it means it’s a better model for that specific task type. GPT-4o’s broader capabilities don’t make it better for your pipeline if your pipeline is purely visual-to-frontend.
The decision tree is simpler than it looks:
Does your task start with visual input and end with code?
- Yes, and volume is meaningful → Test GLM-5V-Turbo first. The cost case is strong and the benchmark numbers are directionally favorable.
- Yes, but volume is low → Either works; GPT-4o is lower friction to set up if you’re already on OpenAI.
Does your task involve any non-visual coding, reasoning, or backend work?
- Yes → GPT-4o, or consider a text-only model entirely.
Do you need production infrastructure stability?
- Yes, and launching soon → GPT-4o. GLM-5V-Turbo is three days old.

FAQ
Q: Is GLM-5V-Turbo better than GPT-4o for design-to-code? Based on Z.ai’s self-reported Design2Code benchmark (94.8 vs comparable GPT-4o-range scores), yes — in that specific task. These numbers haven’t been independently verified yet. Test with your own design assets before treating this as settled.
Q: How much does GLM-5V-Turbo cost vs GPT-4o? GLM-5V-Turbo: $1.20/$4.00 per million input/output tokens. GPT-4o: $2.50/$10.00. Roughly 2x cheaper on input, 2.5x on output. For a typical UI coding task, the difference is ~$0.004 vs ~$0.027 per task. Confirm current pricing at docs.z.ai and openai.com/api/pricing before budgeting.
Q: Can GLM-5V-Turbo handle video input? Yes — short video clips alongside images and text in the same context. GPT-4o does not natively accept continuous video; it requires frame-by-frame extraction on your end.
Q: Which model is better for production UI coding pipelines? Depends on your timeline. GLM-5V-Turbo has the better cost structure and benchmark claims for this use case, but was released April 1, 2026 — it has no production track record yet. GPT-4o is the lower-risk choice for anything launching in the near term. Revisit GLM-5V-Turbo in 60–90 days once independent evaluations are available.
Q: Where can I access GLM-5V-Turbo via API? Via Z.ai’s native API (OpenAI-compatible format) at z.ai, or through OpenRouter as an alternative routing layer. Standard API key registration required.
The honest answer to “which model wins” is: it depends on whether winning means lowest cost per task, strongest benchmark on a specific test, or lowest risk in a production system. GLM-5V-Turbo makes a credible case for the first two in the design-to-code category. GPT-4o makes a credible case for the third.
Neither answer is permanent. Z.ai releases models fast. OpenAI does too. The comparison that matters is the one you run on your own data, with your own design assets, against your own quality bar.
All prices verified as of April 2, 2026. GLM-5V-Turbo benchmark data is Z.ai self-reported; no independent third-party evaluation has been published at time of writing. Verify current pricing at official sources before production budget decisions.
Previous Posts:





