Claude Managed Agents Pricing and Beta Limits
Claude Managed Agents charges tokens plus $0.08/session-hour runtime, with web search at $10/1,000 calls. Here's what the beta billing structure means for your workload.

I pulled up our agent infra cost sheet yesterday and stared at it for a while. I’m Dora. We’ve been running a self-hosted agent loop — tool orchestration, sandboxing, error recovery, checkpoint logic — and it eats roughly 0.4 of an engineer’s time just to keep it from falling over. When Anthropic dropped Claude Managed Agents on April 8, the first thing I did wasn’t read the feature list. I opened the pricing page.
This piece documents what the billing structure actually looks like when you run the numbers, where the rate limits sit, and what’s still uncertain because of the beta label.
How Claude Managed Agents Is Priced
Two-part billing: tokens + session runtime
Managed Agents billing has two dimensions: tokens and session runtime. Tokens are charged at standard Claude API model rates — same per-million-token pricing you’d pay through the Messages API. Opus 4.6 runs **$5 input / $25 output per MTok. Sonnet 4.6 is $3 / $15**. Prompt caching multipliers carry over identically: cache reads cost 10% of base input price.
The second dimension is the infrastructure fee for the managed container.
Session runtime: $0.08 per session-hour
The runtime charge is $0.08 per session-hour for active runtime, billed on consumption. That’s the infrastructure cost of the sandboxed container your agent runs in.
One detail worth flagging: session runtime replaces the Code Execution container-hour billing model when using Managed Agents — you’re not double-charged.
Web search: $10 per 1,000 searches
Web search triggered inside a Managed Agents session costs the standard **$10 per 1,000 searches**. Same rate as the standalone API. A research agent that fires off dozens of web searches per session will feel this line item.
Only available via Claude API directly
Managed Agents is billed through the Claude Platform directly. Third-party platform pricing — Bedrock, Vertex AI, Foundry — does not apply here. If you’re running agents through one of those providers, this is a separate billing relationship.
Session Runtime Cost: What It Means in Practice
What counts as session runtime
Runtime is measured to the millisecond and only accrues while the session’s status is running. Idle time — waiting for your next message, a tool confirmation, or sitting terminated — doesn’t count. The meter pauses when the agent has nothing to do.
This matters more than it sounds. An agent that finishes a task and waits 20 minutes for user input isn’t burning $0.08/hr during those 20 minutes.
Long-running vs. short-task agents
A 10-minute file processing job on Sonnet 4.6 costs roughly **$0.013 in runtime**. Barely registers. The token cost dominates.
A 4-hour research agent session on Opus 4.6 is different. That’s **$0.32 in runtime**, but if the agent is actively reasoning through complex tool chains, you might burn through 200k+ input tokens and 50k+ output tokens. The token bill alone could exceed $1.25 before caching kicks in.
Example cost estimate
Here’s the worked example from Anthropic’s pricing docs: a one-hour coding session on Opus 4.6 consuming 50,000 input tokens and 15,000 output tokens costs about $0.70 total. With prompt caching active and 40,000 of those inputs hitting cache, it drops meaningfully. Runtime accounts for $0.08 of that total.
The real question isn’t “is $0.08/hour expensive?” It’s “how token-hungry is my agent’s tool loop?” Every bash command, file read, web fetch, and web search contributes tokens. A heavily agentic session with dozens of tool calls burns through context fast.
Rate Limits and Quotas
Create endpoints: 60 requests per minute
Managed Agents endpoints are rate-limited per organization, and these limits are separate from the Messages API rate limits. Create endpoints allow 60 RPM at the org level.
Read endpoints: 600 requests per minute
Read endpoints are capped at 600 RPM org-level. If you’re polling session status frequently across many concurrent agents, this is the ceiling you’ll hit first.
Org-level spend limits and tier-based rate limits also apply
Standard tier-based rate limits layer on top. Token-per-minute and request-per-minute limits from your API tier still apply to the underlying model calls your agents make.
How to request higher limits
For production workloads that need more headroom, Anthropic offers Priority Tier with committed spend. Contact their sales team through the Claude Console for custom rate limit arrangements. The Console’s rate limit charts show real-time headroom — use them to see when you’re approaching limits before hitting 429 errors.
Beta Header and What Changes at GA
managed-agents-2026-04-01: required on every request
All Managed Agents endpoints require the managed-agents-2026-04-01 beta header. The SDK sets it automatically. If you’re using raw cURL or a custom HTTP client, add it manually to every request.
Beta-era uncertainty
The official documentation states that behaviors may be refined between releases to improve outputs. That’s a standard beta caveat.
I want to be precise about what this means for pricing. It is not an announcement that Anthropic plans to change pricing at GA. It means the current numbers aren’t a permanent contractual commitment — which is true of any beta-era pricing, anywhere. Build your cost models with that uncertainty factored in, but don’t read it as a signal of impending price changes.
Research preview features remain gated
Certain features — outcomes, multi-agent coordination, and memory — are in research preview and require separate access requests. These could carry additional cost implications when they leave preview. I don’t know yet. Neither does anyone outside Anthropic.
Batch API and Caching Interactions
Batch API: not available for Managed Agents
This is the one that’ll trip people up. The Messages API modifiers including Batch API do not apply to Claude Managed Agents sessions. If you’ve been relying on the 50% discount for bulk processing, you cannot replicate that cost structure with Managed Agents. This is a confirmed limitation, not a roadmap item.
Prompt caching: built in
Prompt caching is built into the Managed Agents harness. Standard multipliers apply — cache writes at 1.25x base input for 5-minute TTL, cache reads at 0.1x. For long-running sessions where the system prompt and early context get reused across many tool calls, caching can meaningfully reduce the token bill.
Compaction: built in
The harness supports built-in compaction and other performance optimizations for efficient agent outputs. For sessions that run long enough to approach context window limits, compaction automatically summarizes earlier conversation turns. This helps manage token accumulation without you building a custom truncation strategy.
Hidden Cost Considerations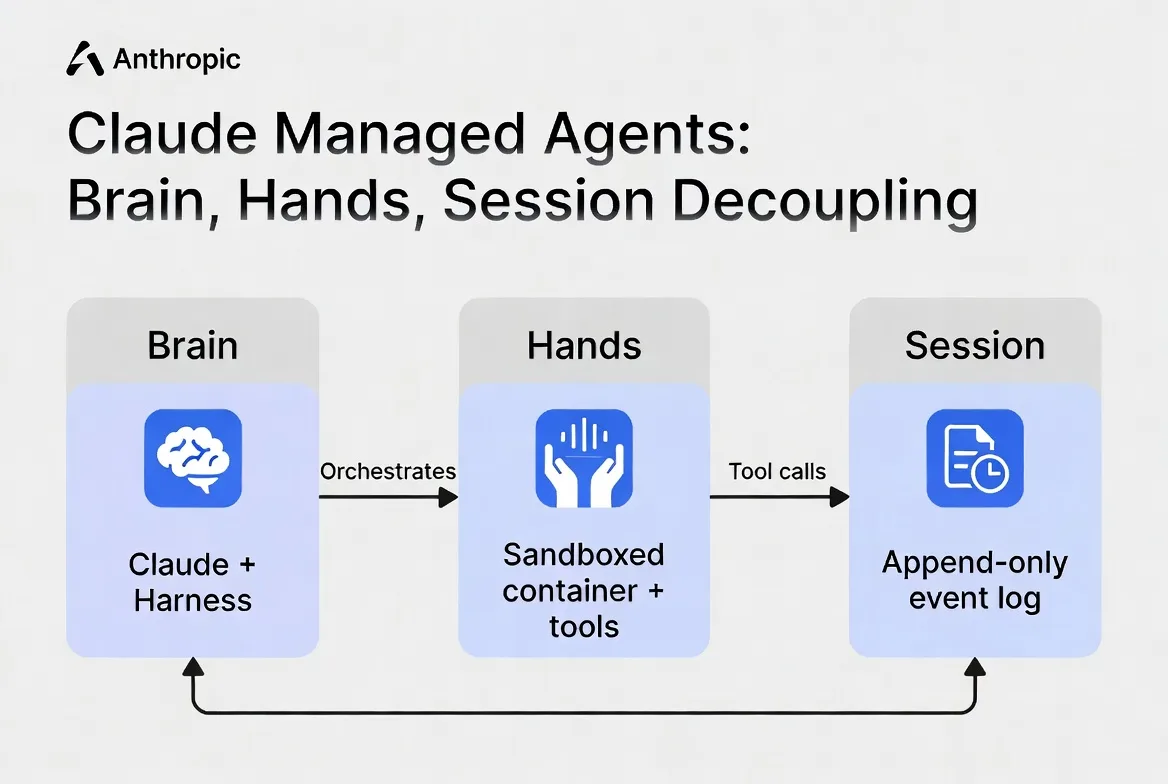
Tool execution overhead
Every tool call generates tokens. Bash commands, file reads, web fetches — each one adds input and output tokens to your session total. A research agent that chains 30+ tool calls in a single session will accumulate token costs that dwarf the $0.08/hour runtime fee.
Web search at $10/1,000 calls is the most visible per-call cost. But the less visible one is the token overhead from tool results flowing back into context. A web fetch that returns a long page dumps thousands of tokens into your session.
Research preview features: potential cost multiplier
Multi-agent coordination — where agents can spin up and direct other agents — is available in research preview. Each sub-agent runs its own session with its own token consumption and runtime meter. The cost multiplier depends on how many sub-agents get spawned and how long each runs. I haven’t been able to verify whether sub-agent sessions carry separate runtime fees or share the parent’s. This is one to watch.
FAQ
Is Claude Managed Agents free during beta?
No. Consumption-based pricing is active now — standard token rates plus $0.08 per session-hour for active runtime. There’s no free tier specifically for Managed Agents. New API users receive a small amount of free credits for initial testing, but that’s the standard API onboarding credit, not a Managed Agents perk.
How does session runtime billing work for async agents?
Runtime only accrues while the session status is running. If an agent finishes a task and enters idle — waiting for the next user message or a tool confirmation — that idle time costs nothing. The meter pauses and resumes when processing restarts. Metering is to the millisecond.
Can I use the Batch API discount with Managed Agents?
No. The 50% Batch API discount does not apply. If batch-level savings are critical to your workflow, evaluate whether the infrastructure savings from managed hosting offset losing the batch discount. For some workloads, running your own agent loop on the Messages API with batch processing will still be cheaper.
What happens to billing when beta ends?
Anthropic hasn’t committed to specific GA pricing. The current $0.08/session-hour and standard token rates are beta-era numbers. The billing model will likely persist in some form, but specific numbers could change. Factor that uncertainty into any long-term cost projections.
Is there a free tier or trial?
No dedicated Managed Agents trial exists. Standard API free credits apply. For enterprise evaluation, Anthropic’s sales team can discuss extended trial arrangements — reach them through the Claude Console or at sales@anthropic.com.
That’s what I can confirm as of April 9, 2026. The pricing structure is straightforward once you separate the two billing dimensions, but the real variable is tool-call token accumulation — that’s where your estimates will diverge from reality. I’m still running test sessions to get a better read on how compaction and caching interact at the 2-hour-plus mark. More to come.
Previous posts:





