Claude Mythos Cybersecurity Capabilities: What Developer and Security Teams Need to Know
Claude Mythos has raised serious cybersecurity concerns. Here's what the leaked claims mean for developer and security teams evaluating this model.

“Should we be worried about this?” The messge from the client’s security team landed in Slack while I was reviewing internal AI tooling options and the Anthropic leak story landed in my feed.
Try the latest Claude on WaveSpeedAI — Opus 4.7 ships with vision and tool use, OpenAI-compatible endpoint, transparent per-token pricing. Claude Opus 4.7 API → · Open the Playground →
That question kept coming up over the next 48 hours. Not from AI enthusiasts but CISOs, security leads, and developers who build on AI infrastructure and suddenly found themselves in a conversation they weren’t prepared for.
The Mythos story isn’t just an AI product announcement. It’s a signal about where the threat environment is heading, and understanding what’s actually confirmed versus what’s speculation matters more than it usually does when a new model drops. And in this piece, we are going to probe into the answer to this question together.
What the Leaked Draft Revealed About Mythos Cybersecurity Capabilities
The leaked draft blog post — part of nearly 3,000 exposed internal assets — contained two striking claims about cybersecurity that have been widely quoted. Anthropic’s own words, written internally before any public announcement, described the unreleased model (internally tied to the “Capybara” tier and referred to as Claude Mythos) as “currently far ahead of any other AI model in cyber capabilities.” It further warned that the model “presages an upcoming wave of models that can exploit vulnerabilities in ways that far outpace the efforts of defenders.”
A second key passage showed unusual caution: “In preparing to release Claude Mythos, we want to act with extra caution and understand the risks it poses — even beyond what we learn in our own testing. In particular, we want to understand the model’s potential near-term risks in the realm of cybersecurity — and share the results to help cyber defenders prepare.”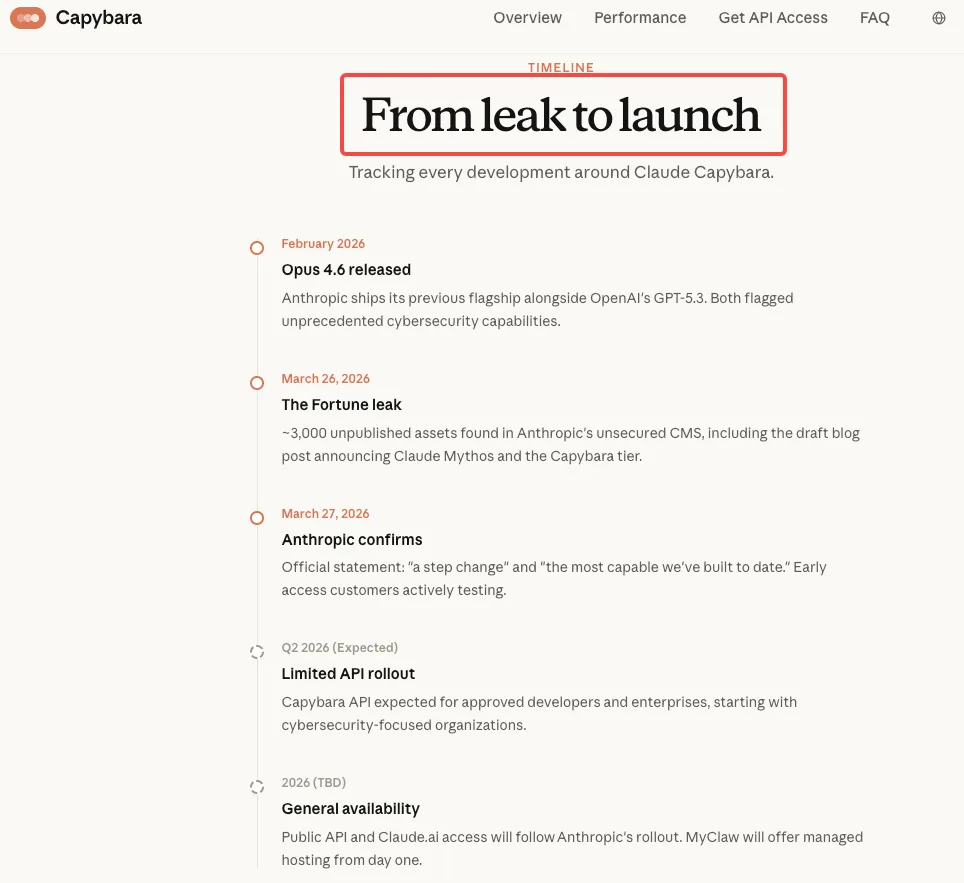
This framing treats cybersecurity risk not as a manageable limitation, but as a significant externality requiring proactive sharing with defenders. It’s a notably different posture from Anthropic’s previous releases.
What’s missing from the leak? Specific benchmark numbers, exploit categories, or detailed methodology. Claims of “dramatically higher scores on tests of cybersecurity” represent the full extent of disclosed capability. Anything more specific circulating online is extrapolation.
Why Anthropic Is Treating This as an Unprecedented Risk
What “Far Ahead of Any Other AI Model in Cyber Capabilities” Actually Means
This claim lands differently if you understand what Opus 4.6 — the current baseline — is already capable of. This isn’t Mythos outperforming a low bar.
Using Claude Opus 4.6, Anthropic’s Frontier Red Team found and validated more than 500 high-severity vulnerabilities in production open-source codebases — bugs that had gone undetected for decades, despite years of expert review. The team used no specialized instructions or custom harness, relying solely on the model’s out-of-the-box capabilities.
One notable case: Opus 4.6 identified a blind SQL injection in Ghost CMS (a platform with 50,000+ GitHub stars and a previously spotless security record) in roughly 90 minutes.
The structural difference between AI-powered vulnerability discovery and traditional fuzzing is important context here. Fuzzers feed inputs into code until something breaks. Claude reasons about code: tracing logic across components, reading commit histories to find unpatched variants of fixed bugs, and evaluating which code paths are inherently risky rather than studying every possible input. Mythos, according to Anthropic’s own internal assessment, does this better than anything else currently available — by a significant margin.
The Defender Gap Problem: Why Offense May Outpace Defense
The draft’s most important insight wasn’t cataloging new attack types. It was articulating why the attacker-defender asymmetry exists in the first place. Attackers need to find one weakness. Defenders need to cover everything. An AI model that can reason about code, identify potential vulnerability patterns, and assist with exploit refinement compresses the time from “idea” to “working attack.”
Anthropic has reportedly warned senior government officials that Mythos could make large-scale cyberattacks more likely in 2026 by enabling highly sophisticated autonomous agents. A Dark Reading poll from early 2026 found that 48% of cybersecurity professionals now rank agentic AI as the top attack vector for the year — ahead of deepfakes and social engineering.
This isn’t a problem Mythos creates from scratch; it’s an accelerant. Adversaries already use AI without hesitation or compliance friction. Defenders who self-restrict access to frontier models risk ceding critical ground.
Defensive vs Offensive Applications: Where the Line Is
Legitimate Use Cases: Vulnerability Scanning, Red Teaming, Code Hardening
The defensive applications of Mythos’s capabilities are genuinely significant — and they’re the primary reason Anthropic is building and releasing this at all.
**Claude Code Security**, a new capability built into Claude Code, scans codebases for security vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix security issues that traditional methods often miss. Nothing is applied without human approval: Claude Code Security identifies problems and suggests solutions, but developers always make the call.
Mythos-tier capability applied to this workflow would mean finding vulnerability classes that even Opus 4.6 misses — context-dependent flaws in business logic, multi-component interaction patterns, authentication bypasses that require understanding system architecture rather than code patterns. For security teams currently paying for manual penetration testing on a quarterly cycle, AI-driven continuous scanning at Mythos-level reasoning quality represents a meaningful shift in what’s operationally achievable.
For red teams, the same power requires strict scoping and authorization. The model itself doesn’t distinguish between authorized testing and malicious use — that responsibility stays with your processes and guardrails.
What Anthropic Is Doing to Limit Misuse
Alongside Opus 4.6, Anthropic deployed activation-level probes to detect and block cyber misuse in real time, acknowledging potential friction for legitimate security research. “This will create friction for legitimate research and some defensive work, and we want to work with the security research community to find ways to address it as it arises,” the company warned.
For Mythos specifically, the controls are structural rather than just technical. Based on the leaked documents and Anthropic’s public statements, initial access is restricted to vetted security researchers and defenders — the goal is to build defensive tooling before offensive capabilities become broadly available. This mirrors Anthropic’s handling of previous high-risk releases and aligns with practices recommended by NIST’s AI Risk Management Framework, which advocates staged deployment with ongoing monitoring for dual-use AI systems.
The MITRE ATT&CK framework’s adversarial AI tactics section is worth reviewing for any security team trying to model the threat surface here. The tactics documented there assume significantly less capable models than what Mythos represents.
What Early Access Security Customers Are Evaluating
The leaked draft was explicit about Anthropic’s rollout priority: “We’ll be slowly expanding access to Claude Mythos to more customers using the Claude API over the coming weeks. Since we’re particularly interested in cybersecurity uses, that’s where we aim to expand the EAP initially.”
The early access cohort is evaluating Mythos against the specific problem the model was designed to address: finding vulnerabilities in hardened production codebases faster and more comprehensively than existing tools. Analysts note it could compress the offense-defense gap in both directions — enabling faster vulnerability discovery, continuous red-teaming, and threat hunting, while also lowering the bar for sophisticated attacks if misused.
For security customers currently in the evaluation period, the practical questions center on three areas: how Mythos integrates with existing SIEM and vulnerability management workflows, whether the model’s findings can be surfaced in formats compatible with existing ticketing systems, and what the human review requirements look like at scale.
In interviews with more than 40 CISOs across industries, VentureBeat found that formal governance frameworks for reasoning-based scanning tools are the exception, not the norm. The most common responses were that the area was considered so nascent that many CISOs didn’t think this capability would arrive so early in 2026. The teams inside the early access program are, in a real sense, writing the governance playbook that the rest of the industry will follow.
Implications for Developer Teams Building on AI Infrastructure
If your team is building products on top of Claude or any frontier AI model, the Mythos situation creates two distinct categories of concern.
The first is direct: you are a potential target for AI-assisted attacks, and those attacks are getting more capable.
The second concern is architectural: how your AI infrastructure is secured against prompt injection, unauthorized tool access, and agent misuse. Organizations need to treat every agent, bot, and AI service as an identity, bringing the same level of controls, permissions, and oversight to non-human identities as they do human users — requiring inventory of access, and eliminating hard-coded credentials that create insecure bots.
Practically, this means several things for teams building on Claude today:
Scope MCP server access tightly. Every MCP server you connect to a Claude agent is a potential attack surface. The expanded agentic capabilities that make Claude Code powerful also make poorly scoped agent permissions a meaningful risk vector.
Treat CLAUDE.md as a security document. Instructions in CLAUDE.md that define what tools an agent can use, which files it can read, and what operations it can perform are security controls, not just productivity helpers. A poorly written CLAUDE.md that grants broad file access or tool permissions amplifies risk.
Apply human review to AI-generated patches, not just AI-generated code. AI-generated code is 2.74x more likely to introduce XSS vulnerabilities and 1.91x more likely to introduce insecure object references compared to human-written code. The same reasoning capability that finds vulnerabilities can introduce them. Human review of security-relevant changes isn’t optional.
FAQ
Can security teams access Claude Mythos now?
Not through any public channel. The model’s rollout plan reflects the cybersecurity concern: Early access is restricted to vetted defensive cybersecurity organizations. For security teams wanting to prepare, Claude Code Security — built on Opus 4.6, available now in limited research preview for Enterprise and Team customers — is the closest publicly accessible tool, and a useful baseline for understanding what Mythos-tier capability would extend.
What safeguards is Anthropic building in?
Confirmed measures include real-time misuse detection probes, staged rollout prioritizing defenders, and human-in-the-loop requirements for patches. For Mythos, emphasis is on deployment governance, tool boundaries, and audit trails.
Will Claude Mythos be available for commercial red teaming?
Not confirmed. The early access cohort is focused on defensive security use cases. Commercial red teaming — where organizations hire security firms to actively probe their systems — sits in an ambiguous zone: it’s authorized offense. Given the company’s stated concern about offensive misuse, expect meaningful access controls rather than open API access for red teaming use cases.
Previous Posts:
- Claude Mythos vs Claude Opus 4.6: What the Leak Reveals for Developers
- Claude Mythos (Opus 5) Leaked: What We Know So Far
- What Is Claude Mythos? Leak, Capybara Tier & What Anthropic Confirmed
- Claude Sonnet 4.6: A “Non-Hogging the Spotlight” Work Model
- Claude Opus 4.6 and Sonnet 4.6: Everything You Need to Know





