GPT-5.5 vs GPT-5.4 for Production Teams
Compare GPT-5.5 vs GPT-5.4 through a production lens: availability, rollout timing, migration readiness, and where each model fits today.

Hi, I’m Dora. OpenAI shipped GPT-5.5 on April 23, 2026. Less than two months after GPT-5.4. The API was held back for a day, then opened on April 24 with what OpenAI called “different safeguards.” If you’re running a coding agent on GPT-5.4 today, the question isn’t whether GPT-5.5 is smarter. The benchmarks already say it is. The question is whether your specific API workload is the kind that benefits enough to justify a migration this week.
I’m writing this as someone who’s had to make this call before. Same situation, different model number. The honest answer is that it depends on three things you can verify in an afternoon, and one thing you can’t verify yet at all.
This piece is about how to tell the difference.

GPT-5.5 vs GPT-5.4 at a Glance
Availability and rollout differences
GPT-5.5 went live on April 23 in ChatGPT and Codex for Plus, Pro, Business, and Enterprise tiers. The API followed on April 24. Per OpenAI’s official launch post for GPT-5.5, pricing is $5 per 1M input tokens and $30 per 1M output tokens, with a 1M context window. GPT-5.5 Pro sits at $30/$180 per 1M.
GPT-5.4 stays on the rate card. You can confirm both on OpenAI’s official API pricing page. GPT-5.4 standard runs at $2.50 input / $15 output. So the headline price gap is 2x on the surface.
OpenAI’s own framing is that GPT-5.5 uses fewer tokens per task, especially in Codex workloads, so the effective cost gap is narrower than the rate card suggests. That’s a reasonable claim. It’s also a claim you have to verify on your own traffic before betting a budget on it.
What is officially stated vs inferred
Stated, with sources: pricing, latency parity per token vs GPT-5.4, 1M context, the safeguard delta on API serving. Stated by OpenAI but worth reading carefully: the agentic-coding gains, the Terminal-Bench 2.0 score of 82.7%, the long-context retrieval jump on MRCR v2.
Inferred and circulating: that GPT-5.5 will replace GPT-5.4 in most production workloads “soon.” OpenAI hasn’t said that. GPT-5.4 isn’t being deprecated. Don’t plan against a sunset that isn’t on the docs.
I paused here when I read the TechCrunch coverage of the GPT-5.5 launch — the framing leans hard on “super app” ambition, which is a strategy story, not a migration trigger.
Where GPT-5.5 Appears Stronger
Agentic coding and computer use claims
The benchmark deltas OpenAI published are real numbers, but they’re OpenAI’s own evals. Take them as directional, not as ground truth.
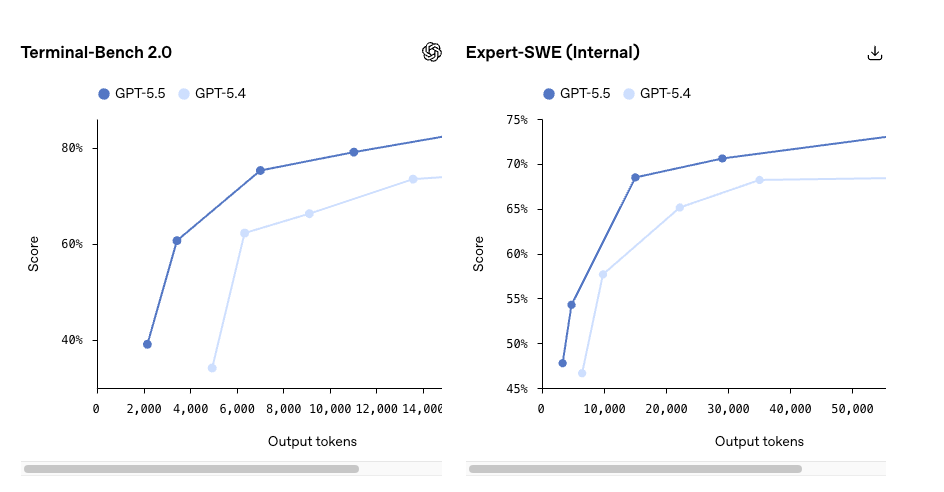
- Terminal-Bench 2.0: 82.7% (GPT-5.5) vs 75.1% (GPT-5.4)
- SWE-Bench Pro: 58.6% vs OpenAI’s previous reported 55–57% range
- OSWorld-Verified (computer use): 78.7%
- MRCR v2 long-context retrieval (512K–1M): 74.0% vs 36.6%
That last one is the one I’d actually pay attention to. A 37-point jump in long-context retrieval is the kind of delta that changes what’s feasible, not just what’s faster. If your workload routinely pushes past 256K tokens — entire codebases, multi-hour agent traces, full document sets — this is where the upgrade story gets real.
If your workload is short-context chat completions and structured outputs, none of that applies to you. Better than expected, but only slightly.
Efficiency and workflow implications
OpenAI’s claim is that GPT-5.5 uses roughly 40% fewer output tokens for equivalent Codex tasks. If that holds on your traffic, the 2x rate-card increase compresses to something like a 20% effective increase. That’s a meaningful difference in the migration math.
It also means you can’t trust your existing cost projections. The token accounting changes. Run a real workload for a week before you extrapolate.
Why GPT-5.4 May Still Be the Better API Choice Today
Three reasons this isn’t a clean upgrade.
One: refusal behavior. OpenAI shipped GPT-5.5 with a stronger safeguard suite — they call it the strongest set to date. The full picture is in the GPT-5.5 system card. For most teams this is invisible. For teams running dual-use, security, or agentic workloads near policy edges, the refusal surface has changed, and it changed in ways the system card doesn’t fully enumerate. Run your existing prompt set through it before assuming behavior parity.
Two: tooling stability. Tool-calling schemas, structured output behavior under reasoning effort, parallel tool calls — these surfaces tend to drift between model generations. The contract you’ve tuned against on GPT-5.4 isn’t guaranteed to hold. You’ll find the deltas faster by replaying production traffic than by reading docs.
Three: cost predictability under bursty load. GPT-5.5’s “fewer tokens” claim is a population average. Individual workloads vary. If your traffic has long tails — agents that occasionally spiral into long reasoning chains — you can hit cost spikes that don’t show up in the average. GPT-5.4 has a predictable cost shape your finance team has already accepted.
None of this means stay forever. It means don’t migrate on the announcement.

A Practical Decision Framework for Teams
Four questions, in this order:
- Is your workload long-context bound? If you regularly run prompts above 200K tokens and retrieval quality is your ceiling, GPT-5.5 is probably worth a serious test now. The MRCR v2 delta isn’t the kind of number you ignore.
- Is your workload agentic / multi-step / Codex-style? Worth a parallel A/B. Not worth a full migration until you’ve measured token consumption on your actual tasks. The 40% reduction is plausible. It’s also a claim that needs your data, not OpenAI’s.
- Is your workload short-context chat or single-shot generation? Stay on GPT-5.4. The price increase is real and the capability delta on these tasks is small. Hypothesis confirmed by reading the benchmark categories — the gains concentrate in long-horizon and computer-use evals, not in short turns.
- Do you have a current production incident or capacity issue? Don’t migrate during a fire. New model + new safeguards + new token accounting is three changes at once. Run the comparison on a parallel branch.
Things to verify before any switch, regardless of category: refusal behavior on your prompt corpus, tool-calling schema parity (check the GPT-5.5 model page in OpenAI’s API docs), end-to-end latency on your routing layer, and a one-week cost projection on real traffic. Not synthetic. Real traffic.

FAQ
Should teams switch from GPT-5.4 now?
Not by default. Switch if you’re long-context-bound or running a multi-step agent stack. Otherwise, run a parallel test for two weeks, compare on your metrics, then decide. The “newer is better” reflex has cost more teams more money than I want to count.
Is GPT-5.5 usable in production today?
Yes. The API has been live since April 24, 2026, with documented pricing and rate limits. “Usable” and “appropriate for your workload” are different questions. The first is settled. The second is yours to answer.
What should teams test before migrating?
Refusal behavior on your prompt set. Token consumption on representative tasks (not synthetic ones). Tool-calling schema and structured output parity. Latency at your real concurrency. Cost over a full week of normal traffic. If any of those break, stay put until they don’t.
When is staying on GPT-5.4 the better call?
Short-context workloads. Stable, well-tuned production systems. Cost-sensitive workloads where the 2x rate-card increase isn’t offset by token efficiency on your specific traffic. Teams in the middle of a release cycle. Teams without bandwidth to re-validate refusal behavior. GPT-5.4 isn’t being deprecated. Staying is a valid call, not a delayed migration.
Conclusion
The answer to GPT-5.5 vs GPT-5.4 for production teams isn’t a single answer. It’s a workload question disguised as a model question. Long-context and agentic workloads have a real reason to test now. Short-context workloads have a real reason to wait. Everyone in the middle has a reason to run the parallel comparison and let the data decide.
That’s where my data ends. The benchmarks I’m citing are mostly OpenAI’s own. The token-efficiency claim is plausible but unverified outside their evals. The safeguard delta will surface in production in ways the system card doesn’t predict.
Run it yourself on your traffic for a week. That’ll tell you more than anything I say.
More to come once the post-launch behavior settles.
Previous Posts:
- GPT-5.5 for Builders: API Capabilities, Pricing, and When to Upgrade
- GPT-5 Model Versions Explained: Differences, Use Cases, and Migration Paths
- GPT-5.4 vs GPT-5.3: What Changed for Developers and API Workloads
- Agentic Workflow Patterns: Tool Wiring, Pitfalls, and Real-World Tradeoffs
- DeepSeek V4 Pro vs Flash: Cost, Speed, and Performance Trade-offs
Related Articles

Claude Fable 5 Fallback to Opus 4.8 Explained

GLM-5.2 API: Pricing, 1M Context, and Production Routing

TripoSplat: Image-to-3D Gaussian Splatting for Builders

GPT-5.4 Mini Pricing: Input, Cached & Output Cost

MAI-Image-2.5 API: What Builders Should Know
