DeepSeek V4 Pro vs Flash: Which One for Production?
Compare DeepSeek V4 Pro vs V4 Flash for production: capability trade-offs, latency, cost, and which version fits your workload.

DeepSeek released V4 as two models, not one: V4-Pro at 1.6T total parameters with 49B activated, and V4-Flash at 284B total with 13B activated. Both share a 1M token context window. Both are open weights under MIT. Both ship on the same API surface.
That matters because the decision is no longer “use DeepSeek or don’t.” It’s which of the two to put behind which endpoint. And the right answer is rarely “just use Pro everywhere.”
This is a selection guide for AI product teams and eng leads trying to route workloads correctly. If you’ve read my earlier piece on DeepSeek V4 features for API developers, that was the single-model era. This is the split-tier version.
All numbers below are as of publication date. Anything I can’t verify against official docs is flagged explicitly.
DeepSeek V4 Pro vs Flash at a Glance
Positioning of each version (per official preview)
Per DeepSeek’s own V4-Pro model card on Hugging Face, the split is intentional — they’re not the same model at different sizes. Flash is trained separately, not distilled from Pro.
DeepSeek’s own framing:
- V4-Pro — rich world knowledge surpassing open models, world-class reasoning across math/STEM/coding, strongest on agentic tasks.
- V4-Flash — reasoning “closely approaches” Pro, performs on par with Pro on simple agent tasks, weaker on complex ones. Cheaper to serve, faster responses.
That “simple vs complex” distinction is the whole decision. DeepSeek is telling you directly where Flash drops off. Don’t ignore it.
Shared features (1M context, thinking mode, API compatibility)
The features that are identical across both:
- 1M token context window on both variants, enabled by DeepSeek’s hybrid attention architecture (CSA + HCA). Per the Hugging Face card, Pro needs only 27% of per-token FLOPs and 10% of the KV cache vs V3.2 at 1M context.
- Three reasoning effort modes — non-thinking, thinking (high), and Think Max. Same API flag, same behavior surface.
- OpenAI-compatible Chat Completions API and Anthropic-protocol support. Same
base_url, just swap the model ID. - MIT license on weights for both, per the official repos.
If you’re migrating between them, the integration surface doesn’t change. Only the model ID and the bill.
Capability Differences
Where they diverge is on specific eval categories — and the pattern is consistent enough to build a routing rule from.
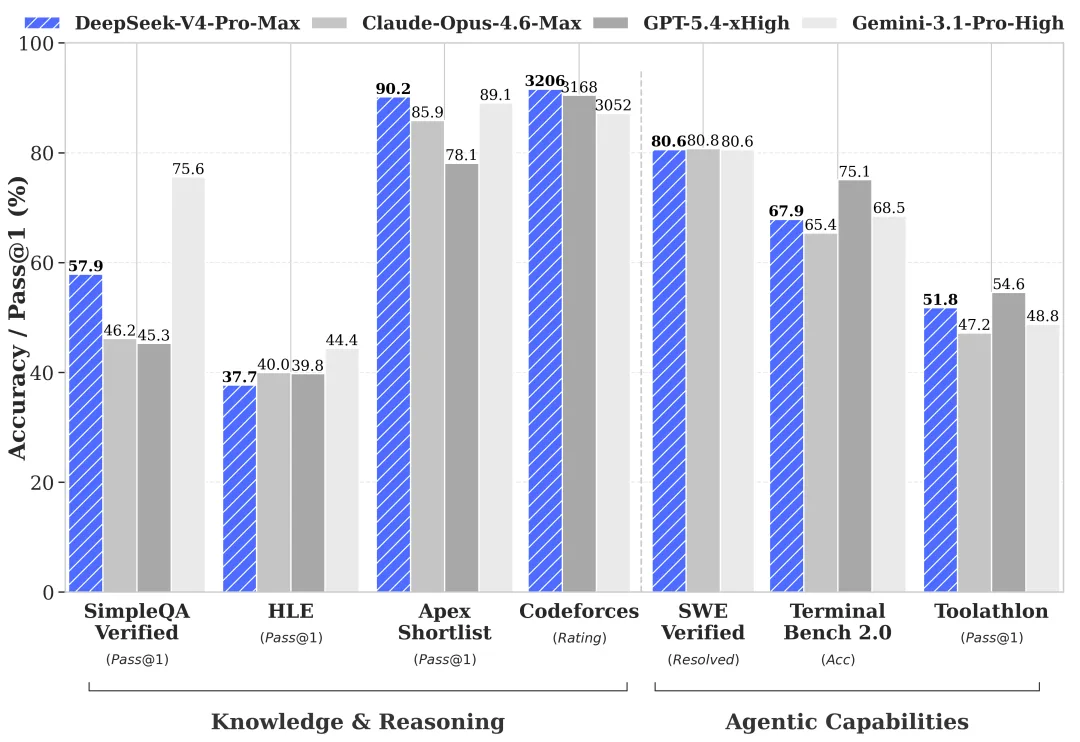
World knowledge: Pro leads, Flash trails (per official benchmarks — needs verification)
DeepSeek’s own preview benchmarks, summarized across their HF card and technical report, show the Pro/Flash gap is narrow on most eval categories — but wide in a few specific places:
| Benchmark | V4-Pro | V4-Flash | Gap |
|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 1.3 |
| LiveCodeBench | 93.5 | 91.6 | 1.9 |
| SWE-Verified | 80.6 | 79 | 1.6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57.9 | 34.1 | 23.8 |
| Terminal Bench 2.0 | 67.9 | 56.9 | 11 |
Numbers reported by DeepSeek. No third-party replication exists at this time — needs verification before production adoption. But the shape of the gap is the signal, not the exact digits.
SimpleQA-Verified is factual recall. Terminal Bench 2.0 is multi-step tool use. Flash takes a real hit on both. That’s consistent with what DeepSeek said in plain language: simple tasks fine, complex agent workloads weaker.
Reasoning parity on simple tasks
On coding, math, and bounded reasoning, the gap closes to 1-3 points. LiveCodeBench and MMLU-Pro put Flash within striking distance of Pro. For most inference calls in a typical product — chat turn, one-shot generation, a code completion, a summarization — Flash is not a downgrade in any way users will notice.
That’s the core of the Flash value proposition: it’s not a stripped-down Pro. It’s a separately trained model that happens to land close to Pro on the middle of the benchmark distribution.
Agent task divergence on high-complexity workloads
The long-horizon, multi-tool, multi-hop category is where the two separate. Terminal Bench 2.0 and Toolathlon are the relevant evals here. The 11-point gap on Terminal Bench is not a margin you can write off as eval noise.
If your product is a coding agent running a 30-step loop with filesystem and shell access, or a research agent orchestrating 5+ tool calls per query, Flash will fail more often in places that are expensive to debug. Not because Flash is bad — because this is exactly the workload DeepSeek built Pro for.
Production Decision Framework
Selection isn’t “which is better.” It’s “which matches this workload shape.” Three defaults work well.
When to choose Pro (agentic coding, long-horizon reasoning, enterprise eval)
Pro is the right call when any of the following is true:
- You’re running a multi-step agent loop (Claude Code-style, OpenCode, anything with tool use + planning + verification per turn).
- Your task requires accurate factual recall on a long tail of entities — the 23-point SimpleQA gap predicts real hallucination differences here.
- You’re doing enterprise eval where the business cost of a wrong answer exceeds the per-token cost by orders of magnitude.
- You need long-horizon reasoning across a genuinely full 1M-token context — Pro’s efficiency numbers at 1M context are the architecture story here.
When to choose Flash (high-QPS classification, summarization, chat UX)
Flash is not the budget option. It’s the correct option when:
- You’re running high-QPS classification, tagging, or extraction — latency and cost per call dominate quality margin.
- Summarization and translation — bounded, single-pass tasks where Flash’s 1-2 point benchmark delta is invisible to users.
- Interactive chat UX — first-token latency matters more than the 99th percentile of answer quality, and Flash is meaningfully faster.
- Embedding-adjacent work: query rewriting, intent classification, relevance scoring.
Picking Pro here wastes 10× on output tokens for no perceivable gain. That’s a worse decision than using Flash for an agent loop.
Hybrid routing: Flash default, Pro fallback
For most products, the right architecture is neither/nor — it’s both, with a router:
- Default every request to Flash.
- Escalate to Pro on one or more explicit triggers: tool-call failure, confidence threshold missed, multi-turn agent entering a known-hard phase, user flags an answer as wrong.
- Log the escalation rate. If <5% of requests escalate, Flash is covering your workload. If >30%, you’re in Pro territory and the router is overhead.
This only works because Pro and Flash share the API surface and the reasoning-mode flag. Swapping between them mid-session is a one-line change in most clients. The official DeepSeek pricing docs confirm the model IDs are siblings, not siloed endpoints.
Cost and Latency Trade-offs (as of publication date)
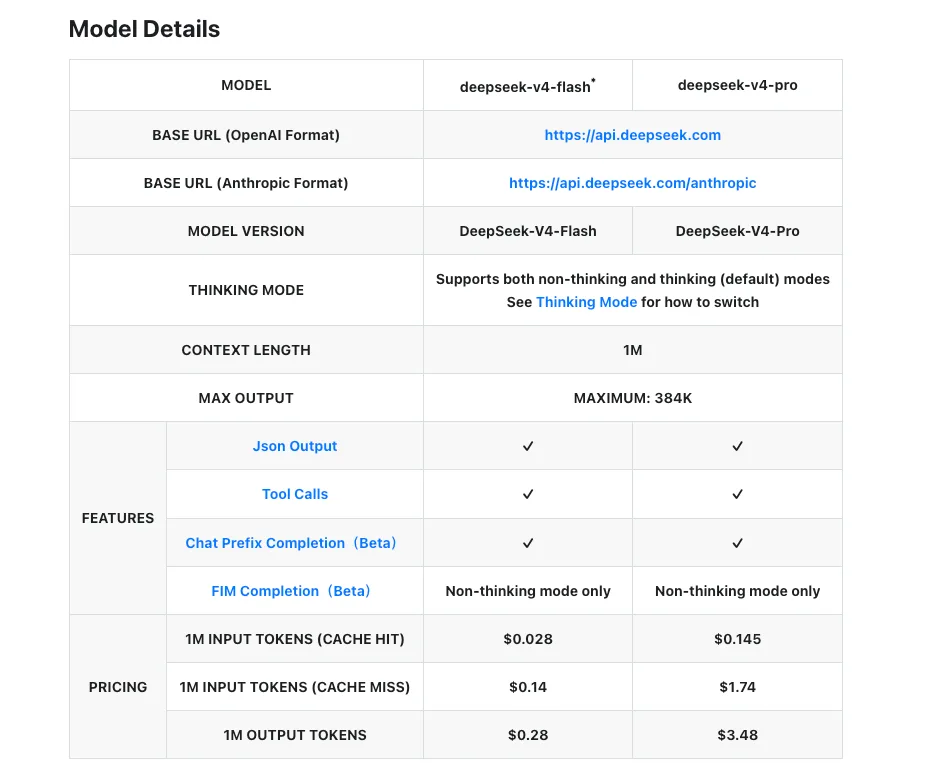
Numbers below are from DeepSeek’s official pricing page as of April 24, 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Input (cache miss) | $0.14 / M tok | $1.74 / M tok |
| Input (cache hit) | $0.028 / M tok | $0.145 / M tok |
| Output | $0.28 / M tok | $3.48 / M tok |
| Context window | 1M tokens | 1M tokens |
| Max output | 384K tokens | 384K tokens |
Latency disclosure: DeepSeek has not published official per-tier latency numbers for V4 at the time of writing. Third-party reports suggest Flash serves noticeably faster than Pro, but I can’t point to an official benchmark — needs verification once the preview stabilizes.
Limitations and What Still Needs Verification
This is a preview release. Things to flag before you commit production traffic:
- Benchmark replication. All numbers above come from DeepSeek’s own technical report. Arena-style leaderboards are just starting to log V4 results. No independent SWE-Bench Pro or Terminal Bench runs yet.
- Multimodal: not yet. Both V4 variants are text-only. DeepSeek has said multimodal is in progress; no timeline on record.
- Commercial context. Bloomberg’s coverage of the release notes V4 lands amid ongoing geopolitical scrutiny of DeepSeek, and some non-Chinese deployments have restrictions. Check your compliance posture before routing user data through the official API; self-hosting the open weights is the clean path if that’s a concern.
- Preview stability. The “preview” label is explicit on the V4-Flash model card too. Expect API behavior and pricing to move.
- Deprecation window.
deepseek-chatanddeepseek-reasonerIDs retire July 24, 2026. They currently route to V4-Flash. If you’re on those IDs, you’re already on Flash quality without knowing it — migrate explicitly.
That’s where my data ends. Still watching. I’ll update once third-party evals catch up.
FAQ

Can I switch between Pro and Flash mid-conversation?
Yes. Both share the same API surface and the same OpenAI-compatible format. Switching is a model-ID change in the request body. Conversation history (as you pass it in each call) is portable between the two.
Do both support reasoning_effort?
Yes. Both V4-Pro and V4-Flash support the same three reasoning effort modes — non-thinking, thinking, and Think Max — per the official model cards. Pricing doesn’t change between modes; you’re billed on tokens generated, and Think Max just generates more.
Which version is better for Claude Code–style agent loops?
Pro. The Terminal Bench 2.0 gap (67.9 vs 56.9) is the most direct proxy for multi-step shell/tool loops, and that’s an 11-point difference. Flash will work for simple agent tasks, but a loop that chains 10+ tool calls hits exactly the category where Flash regresses most. DeepSeek’s own positioning language says this explicitly — “on par with Pro for simple Agent tasks,” not all agent tasks.
Commercial use terms for both?
Both are released under the MIT License per the official Hugging Face repos, which permits commercial use, modification, and redistribution. Weights are self-hostable. For hosted API use, DeepSeek’s own terms of service apply on top — verify them for your deployment geography.
Are pricing structures identical or different?
Same structure, different rates. Both have input, cache-hit input, and output tiers. Both support cache discounts on repeated prefixes. The ratio between Pro and Flash rates is consistent — Pro is roughly 12× more expensive on output per token. No plan-tier or commit-based pricing on the official docs at the time of writing.
Previous Posts: