Claude Opus 4.7: Warum KI-Teams eine einheitliche Modell-API-Schicht benötigen
Claude Opus 4.7 steht kurz bevor. Hier erfahren Sie, warum häufige Modellwechsel die wahren Kosten direkter API-Integrationen offenbaren – und was KI-Teams dagegen unternehmen.

Das Fazit zuerst: Das Schwierigste an Claude Opus 4.7 ist nicht das Modell. Es ist die Migration.
Ich — Dora — betreibe KI-Generierungspipelines für Produktionsinhalte. Bilder, Video, Multi-Modell-Orchestrierung. Als Anthropic im Februar Opus 4.6 veröffentlichte, verbrachte mein Team vier Tage damit, Prompts neu zu validieren, Token-Budgets anzupassen und eine Abrechnungsabweichung zu beheben, die erst am dritten Tag auftauchte. Jetzt, kaum zwei Monate später, hat Anthropic Opus 4.7 veröffentlicht — mit einem neuen Tokenizer, Breaking API-Änderungen und einem neuen Effort-Level. Wenn Sie die Person in Ihrem Team sind, die die Modell-Integrationsschicht pflegt, spüren Sie bereits das Gewicht dieses Satzes.
Dieser Artikel dokumentiert, was über Opus 4.7 bisher bestätigt ist, was das Upgrade-Laufband Engineering-Teams tatsächlich kostet und wann die Rechnung zugunsten einer Aggregationsschicht gegenüber direkten Provider-APIs kippt.

Was wir über Claude Opus 4.7 wissen (und was noch unbestätigt ist)
Die Informationen: bestätigt vs. Gerüchte
Opus 4.7 ist seit dem 16. April 2026 allgemein verfügbar. Die Modell-ID lautet claude-opus-4-7. Der Preis bleibt bei $5 pro Million Input-Token und $25 pro Million Output-Token — identisch mit Opus 4.6. Das Kontextfenster von 1M Token ist unverändert. Der maximale Output bleibt bei 128k Token.
Was sich geändert hat: Hochauflösende Vision-Unterstützung bis zu 3,75 Megapixel (mehr als dreimal so viel wie das 1,15-MP-Limit bei 4.6), ein neues xhigh-Effort-Level zwischen high und max, sowie Task-Budgets für agentische Schleifen — eine Beta-Funktion, die dem Modell einen Token-Countdown über einen gesamten mehrstufigen Workflow hinweg gibt.
Die Breaking Changes sind wichtiger als die neuen Funktionen. Extended Thinking Budgets wurden entfernt. Sampling-Parameter sind weg. Der neue Tokenizer verarbeitet denselben Text in ungefähr 1,0–1,35x mehr Token, abhängig vom Inhaltstyp. Der Preis pro Token ist gleich geblieben, aber Ihre tatsächliche Rechnung kann um bis zu 35% steigen, ohne dass Sie einen einzigen Prompt geändert haben.
Was sich von Opus 4.6 zu 4.7 geändert hat — warum das für Entwickler wichtig ist
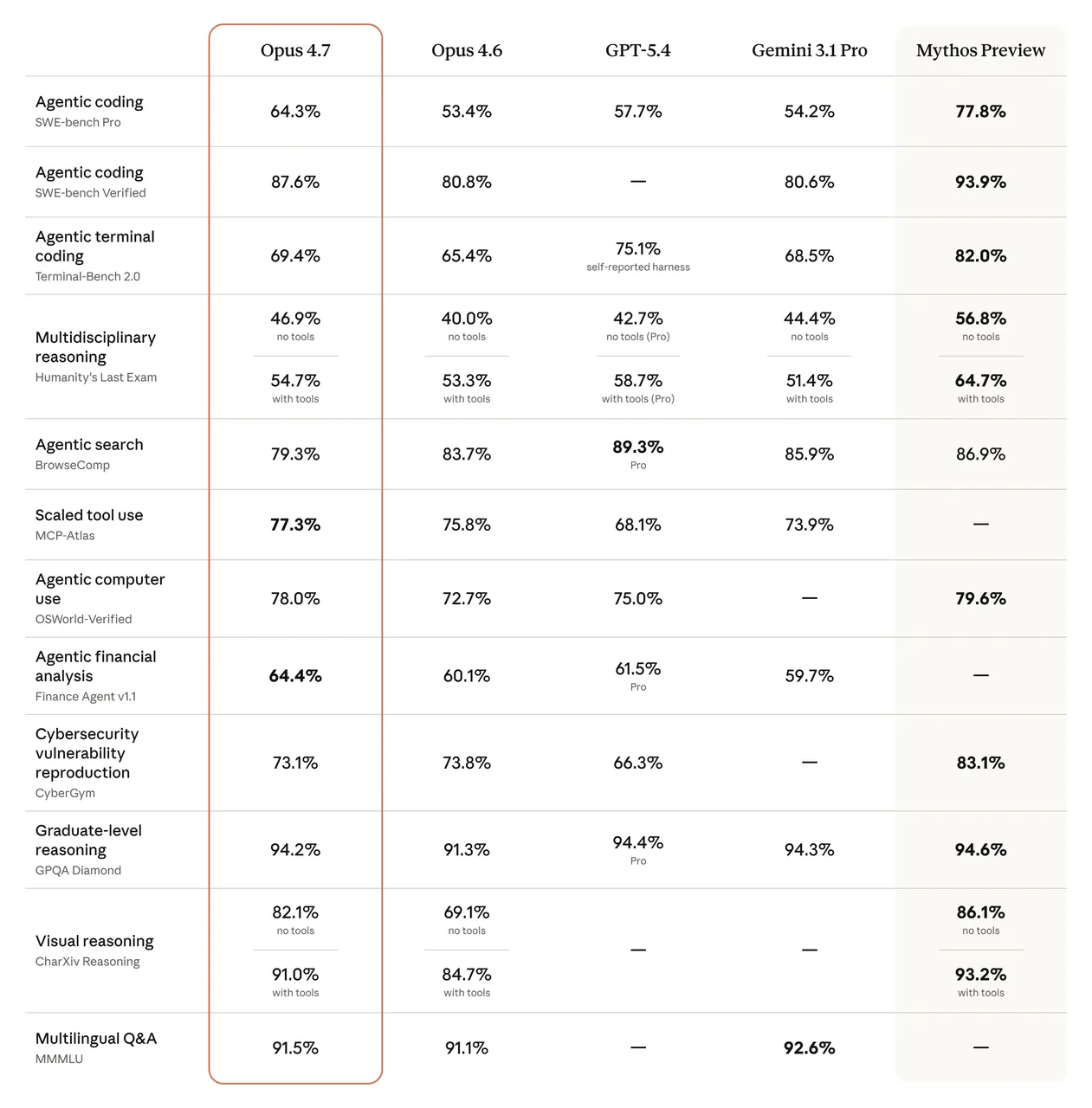
Die Benchmark-Zahlen sind real. SWE-bench Verified stieg von 80,8% auf 87,6%. CursorBench sprang von 58% auf 70%. Bei SWE-bench Pro erzielt Opus 4.7 64,3% — gegenüber 53,4% bei 4.6 und vor GPT-5.4 mit 57,7%.
Aber hier ist der Teil, der Produktionsteams tatsächlich betrifft: Opus 4.7 befolgt Anweisungen wörtlicher. Prompts, die mit 4.6 “locker” oder konversationell waren, können zu starren oder unerwarteten Ergebnissen führen. Wenn Sie wochenlang Prompt-Bibliotheken feinabgestimmt haben, bedeutet diese Verhaltensverschiebung erneutes Testen — nicht nur das Austauschen eines Modell-Strings.
Das eigentliche Problem ist nicht das neue Modell — es ist das Upgrade-Laufband
Was “ein neues Claude jeden Monat” ein Engineering-Team tatsächlich kostet
Anthropic lieferte Opus 4.5 im November 2025. Opus 4.6 im Februar 2026. Opus 4.7 im April 2026. Das sind drei große Modellversionen in fünf Monaten. Jede brachte Parameteränderungen, Verhaltensverschiebungen oder Breaking API-Updates mit sich.
Die Engineering-Kosten jedes Upgrades sind nicht der Modellwechsel. Es ist die Validierungsschleife. Prompt-Regressionstests. Neukalibrierung des Token-Budgets. Aktualisierung der Abrechnungsprognosen. Integrations-Smoke-Tests über Staging und Produktion. Für meine Workflows frisst jede Migration drei bis fünf Engineering-Tage — und das für ein Team, das es schon vorher gemacht hat.
Versionierungsrisiko: wenn Ihre Prompts nach einem Modell-Update brechen
Der Migrationsleitfaden für Opus 4.7 ist diesbezüglich transparent. Der aktualisierte Tokenizer bedeutet, dass /v1/messages/count_tokens für dieselbe Eingabe unterschiedliche Zahlen zurückgibt. Wenn Ihr System fest kodierte max_tokens-Limits hat, können diese nun den Output vorzeitig abschneiden. Wenn Sie sich auf Prefill oder Sampling-Parameter verlassen haben, sind diese weg.
Ich habe Teams gesehen, die Modell-Upgrades wie Abhängigkeits-Bumps behandeln — den Versions-String ändern, die Tests ausführen, ausliefern. Dieser Ansatz hat aufgehört zu funktionieren, ungefähr ab Opus 4.5.
Wer am meisten leidet: direkte API vs. Aggregationsschicht-Teams
Teams, die Anthropics API direkt aufrufen, absorbieren jede Breaking Change selbst. Teams hinter einer Aggregationsschicht — einer Middleware, die Provider-APIs in eine einzige Schnittstelle normalisiert — absorbieren sie einmal, zentral. Der Unterschied potenziert sich. Drei Provider-Upgrades pro Jahr über zwei oder drei Provider bedeuten sechs bis neun Migrationsereignisse. Aggregationsschichten verwandeln das in ein Konfigurations-Update.
Das ist nicht hypothetisch. Ich pflege Integrationen mit mehreren Modell-Providern. Die, die über eine einheitliche Schicht geleitet werden, brauchten Stunden zum Aktualisieren. Die direkten brauchten Tage.
Wie KI-Produktteams den Modellzugang 2026 strukturieren
Direkte Provider-API: wann sie noch sinnvoll ist
Die direkte API gewinnt, wenn Sie Day-Zero-Zugang zu neuen Funktionen benötigen, wenn Ihre Arbeitslast provider-spezifische Fähigkeiten ausnutzt (wie Opus 4.7’s Task-Budgets), oder wenn Sie tief genug in einem Provider sind, dass die Wechselkosten faktisch null sind, weil Sie nicht wechseln.
Wenn Ihr gesamtes Produkt auf Claude und nur Claude aufgebaut ist und Sie die Engineering-Bandbreite haben, um vierteljährliche Breaking Changes zu absorbieren, ist die direkte API immer noch der geradlinige Weg.
Aggregationsschicht: wann die Wechselkosten-Rechnung kippt
Der Wendepunkt ist Multi-Modell-Nutzung kombiniert mit häufigen Provider-Updates. Sobald Sie Claude für Reasoning aufrufen, ein anderes Modell für Klassifizierung und ein drittes für Embeddings — und jeder Provider Breaking Changes nach seinem eigenen Zeitplan liefert — beginnt der Koordinationsaufwand echte Engineering-Zeit zu fressen.
Laut Gartners Prognose werden bis Ende 2026 etwa 40% der Unternehmensanwendungen aufgabenspezifische KI-Agenten einbetten. Jeder Agent kann ein anderes Modell aufrufen. Das über direkte Provider-APIs zu verwalten ist nicht falsch — es ist einfach teuer auf eine Weise, die sich als Engineering-Stunden zeigt, nicht auf einer Rechnung.
Die Evaluierungs-Checkliste vor der Migration zu einer neuen Claude-Version
Bevor man claude-opus-4-6 durch claude-opus-4-7 in der Produktion ersetzt, gehe ich eine kurze Liste durch: Tokenizer-Impact-Testing (führen Sie Ihre tatsächlichen Prompts durch count_tokens auf beiden Versionen aus und vergleichen Sie), Prompt-Verhaltensregression (die wörtliche Anweisungsänderung wird sich hier zeigen), Abrechnungsprognose-Update (der 1,0–1,35x Token-Anstieg ist inhaltsabhängig — messen Sie ihn an Ihren Daten, nicht an Anthropics Durchschnittswerten), und Feature-Abhängigkeits-Audit (prüfen Sie, ob Sie etwas verwenden, das entfernt oder geändert wurde).
Wenn Ihr Team das nicht an einem Tag erledigen kann, ist das ein Signal über Ihre Architektur, nicht über das Modell.
Was nach dem offiziellen Drop von Opus 4.7 zu beobachten ist
API-Verfügbarkeitstimeline und Zugangsstufen
Opus 4.7 ist bereits live auf Claudes API, Amazon Bedrock, Google Cloud Vertex AI und Microsoft Foundry. Claude Pro-, Max-, Team- und Enterprise-Pläne haben alle Zugang. Rate-Limits werden über Opus-Versionen hinweg gepoolt, sodass Sie 4.6- und 4.7-Traffic während der Migration parallel betreiben können.
Preisgestaltung vs. 4.6 — bestätigt vs. spekulativ
Die Preisliste ist identisch. $5/$25 pro Million Token. Prompt-Caching bietet weiterhin bis zu 90% Einsparungen; Batch-Verarbeitung gibt weiterhin 50% Rabatt. Aber die Tokenizer-Änderung bedeutet, dass effektive Kosten pro Prompt höher sind — wie viel höher hängt von Ihrem Content-Mix ab. Dichter Code? Erwarten Sie eher 1,35x. Kurze konversationelle Prompts? Eher 1,0x.
Eine Sache, die ich noch beobachte: Opus 4.7’s neuer Tokenizer verarbeitet mehrsprachige Inhalte berichten zufolge anders. Für Teams, die nicht-englischen Text in großem Maßstab verarbeiten, könnte die Token-Inflation sogar höher als 35% sein. Ich habe dazu noch nicht genug Daten.
Kompatibilitätssignale: Kontextfenster, Tool-Nutzung, strukturierter Output
Kontextfenster: 1M Token, unverändert. Tool-Nutzung: gleicher Satz wie 4.6 — bash, Code-Ausführung, Computer-Use, Text-Editor, Web-Suche, MCP-Connector. Strukturierter Output: unterstützt. Die Opus 4.7 System Card stellt fest, dass das Modell bei der Selbstverifizierung von Outputs gründlicher ist, was bedeutet, dass einige bestehende Prompt-Scaffolding-Konstrukte (“Überprüfe das Folienlayout vor der Rückgabe nochmals”) entfernt werden können.
Die Beziehung zu Claude Mythos ist erwähnenswert: Opus 4.7 ist explizit als Testumgebung für Sicherheitsmechanismen positioniert, die Anthropic schließlich auf Mythos-Klasse-Modellen einsetzen möchte. Opus 4.7 verfügt über automatisierte Cyber-Use-Erkennung, die Mythos Preview in dieser Form nicht hat. Das ist für die API-Integration nicht direkt relevant — signalisiert aber, wohin Anthropics Modell-Roadmap führt.
FAQ
Ist Claude Opus 4.7 bereits über die API verfügbar?
Ja. Es ist seit dem 16. April 2026 allgemein verfügbar. Die Modell-ID lautet claude-opus-4-7. Verfügbar auf Anthropics direkter API, Amazon Bedrock, Google Vertex AI und Microsoft Foundry.
Wie vergleicht sich die Preisgestaltung von Opus 4.7 mit Opus 4.6?
Die Preisliste ist identisch: $5 pro Million Input-Token, $25 pro Million Output-Token. Aber der aktualisierte Tokenizer kann die tatsächlichen Token-Zahlen um bis zu 35% erhöhen, was bedeutet, dass derselbe Prompt auf 4.7 mehr kosten kann als auf 4.6.
Kann ich Claude Opus 4.7 über eine Drittanbieter-Inferenz-API betreiben?
Ja. Mehrere Aggregationsplattformen und Routing-Schichten unterstützen Opus 4.7. Die entscheidende Frage ist, ob die Drittanbieter-Schicht 4.7-spezifische Funktionen wie Task-Budgets und das xhigh-Effort-Level bereitstellt oder nur Standard-Completions durchleitet.
Was ist der Unterschied zwischen Claude Opus 4.7 und Claude Mythos?
Mythos Preview ist Anthropics leistungsstärkstes Modell, eingeschränkt auf ausgewählte Partner unter Project Glasswing für defensive Cybersecurity-Arbeit. Opus 4.7 ist allgemein verfügbar und trägt automatisierte Sicherheitsmechanismen, die Anthropic testet, bevor der Zugang zur Mythos-Klasse ausgeweitet wird. Es sind verschiedene Fähigkeitsstufen mit unterschiedlichen Zugangsmodellen.
Sollte mein Team auf Opus 4.7 warten oder bei 4.6 für die Produktion bleiben?
Wenn Ihre Prompts auf 4.6 kampferprobt sind und Ihr System gut funktioniert, haben Sie es nicht eilig. Pilotieren Sie 4.7 auf einem kleinen Teil des Traffics, messen Sie Tokenizer-Impact und Prompt-Verhaltensänderungen, dann migrieren Sie schrittweise. Das Modell ist besser — aber die Migration ist nicht ohne Aufwand.
Ich betreibe 4.6 und 4.7 noch parallel auf meinen eigenen Pipelines. Die Benchmark-Gewinne sind real, aber auch das Prompt-Nachtuning. In ein oder zwei Wochen werde ich mehr Daten darüber haben, ob der Tokenizer-Overhead gegen die Effizienzgewinne durch weniger Tool-Aufrufe aufgewogen wird. Dieser Teil ist noch nicht geklärt.
Frühere Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten