直接使用OpenAI还是通过平台访问GPT-5.5?
团队应该直接从OpenAI访问GPT-5.5,还是通过模型平台?比较推出速度、回退机制、路由和运营控制。

GPT-5.5 于4月23日在ChatGPT和Codex上线。API接入晚了一天,于4月24日开放。随后在5月5日,GPT-5.5 Instant成为ChatGPT的默认模型,并以chat-latest的形式推送到API。两周之内,三次不同的发布节点,每次的层级资格和适用场景各不相同。
我是Dora。我追踪这件事是因为不得不追踪。我有一个工作流涉及GPT-5系列模型,ChatGPT发布与API发布之间那24小时的窗口期对我来说并非纸上谈兵。这意味着要么等待,要么切换到已经可以访问的渠道。等待还是切换——这正是每个使用前沿模型的团队在每次发布时都要面对的决策。所以这篇文章就是关于这个问题的。
核心问题不是”OpenAI好不好”,而是:当GPT-5.5(或下一个版本)分阶段发布时,你是直接调用OpenAI,还是坐在某个平台后面,让它替你处理这些阶段性问题?两种答案对不同的团队都是正确的。以下是我诚实审视这个问题后的所见。
团队访问GPT-5.5的两种方式
直接接入服务商
你用OpenAI密钥直接调用 api.openai.com。一套SDK、一套文档、一张账单。当OpenAI发布新模型名称时,你修改配置里的一个字符串就能用上——前提是你的层级在第一天就有访问权限。
定价见OpenAI官方定价页面:GPT-5.5输入$5/M tokens、输出$30/M tokens,GPT-5.5 Pro输入$30/M tokens、输出$180/M tokens。大约是GPT-5.4的两倍。直接向OpenAI付费。
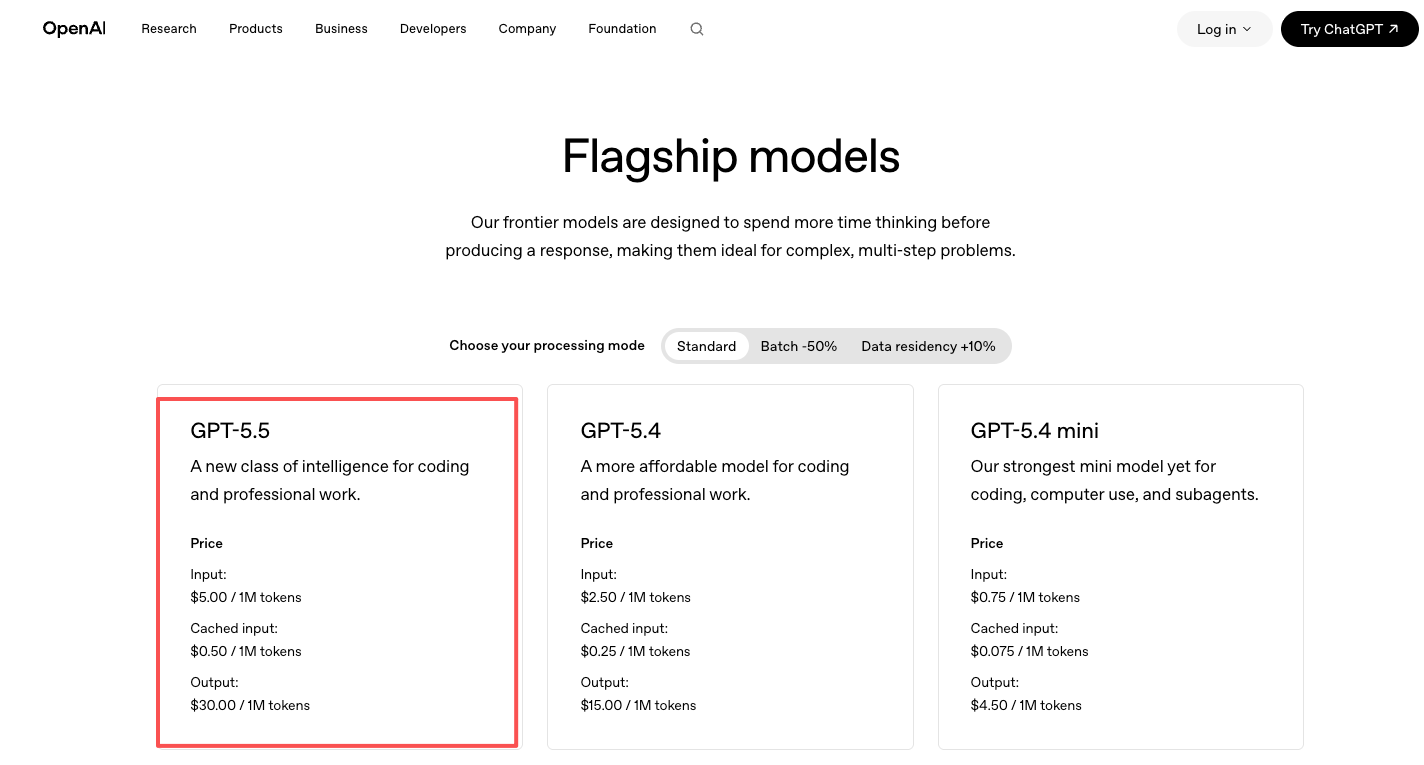
通过模型平台接入
你调用一个路由层——OpenRouter、LiteLLM、内部网关或多模型平台——该层代表你与OpenAI通信。接口形式与OpenAI SDK相同(大多数平台兼容OpenAI格式),但模型字符串可以指向GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro,或三者之间的备用链路。
你向平台付费,平台向OpenAI付费。会有少量加价,有时没有。作为回报,你获得跨服务商的统一账单、无需改代码即可切换模型,以及出现故障时的备用路径。
就是这样。没有哪种方式更好,它们优化的目标不同。
直接接入胜出的场景
简单性、更少的抽象层、服务商特定的优化
如果你只使用OpenAI模型,直接调用OpenAI是最简单的架构。一个供应商,一套错误码,一个状态页。出了问题,你知道找谁。
此外,OpenAI发布的一些功能并不总能立即通过抽象层使用:Responses API、推理强度控制、严格schema的结构化输出、Codex工具界面、服务商特定的工具调用格式。平台层最终会跟上,但”最终”可能意味着数周之后。如果你的产品第一天就依赖某个OpenAI特定功能,直接接入是唯一选择。
间接层也有真实成本,但没人谈论这一点。你的代码和模型之间每多一层,就多一个出错的地方、多一个需要监控的状态页、多一个月末的账单意外。对于在生产环境中运行单一模型的小团队来说,这些开销可能超过带来的好处。
一个模型就够用时
很多团队真的只需要一个模型。一年前选定了GPT-5,工作流运转良好,提示词调好了,评估也稳定了。他们不想和Claude做A/B测试,不想切换到Gemini做故障转移,他们只想让模型持续工作、账单持续可预期。
对这样的团队来说,路由层是在解决一个不存在的问题。直接接入是正确答案,在上面加一个平台反而是错的。别为你用不到的选项付出复杂性的代价。
模型平台胜出的场景
发布速度、故障转移与路由控制
这正是GPT-5.5时间线真正重要的地方。4月23日至24日之间,GPT-5.5已在ChatGPT上线,但API尚未开放。CNBC当时报道,OpenAI表示API发布需要”不同的安全措施”,且未承诺具体日期。对大多数团队来说,那24小时的窗口期无关紧要。但对少数团队——任何合同中规定”在X小时内上线最新模型”的团队——这就是个问题。
平台层不会让OpenAI变快,但它改变了”等待”的含义。当GPT-5.5还未进入OpenAI API时,Claude Opus 4.7已经可用,Gemini 3.1 Pro也已可用。路由方案可以在GPT-5.5上线后优先使用它,在此之前回退到当前可用的前沿模型,且无需在情况变化时部署代码。
同样的逻辑适用于故障。今年OpenAI已经发生过数次多小时的API中断,其他所有服务商也一样。如果你的产品硬性要求”现在就要有能用的LLM”,你要么自己构建备用逻辑,要么让平台处理。OpenRouter的故障转移文档和LiteLLM的路由文档都用具体配置描述了这一点:声明主模型,列出备选,主模型失败时获得可用的响应。
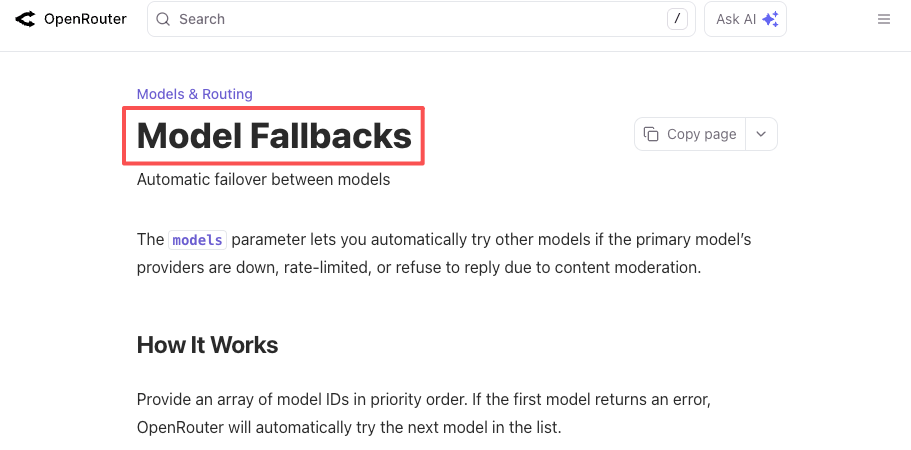
这不是假设场景,这是我本季度已经遇到过两次的情况。
多模型实验与采购弹性
平台发挥作用的另一个场景,是你还不知道哪个模型适合这项工作——或者你预感六个月后答案会变。
前沿模型的领先地位正在以3到6个月的周期轮换。GPT-5.5发布,然后Anthropic发布,然后Google发布,“最适合写代码的模型”或”最适合长文本分析的模型”的答案持续移动。如果你已经针对单一服务商的SDK做了集成,切换意味着真实的工程工作量。如果你在路由层后面,切换只需改一个模型字符串。
同样的逻辑适用于采购。平台将跨服务商的支出整合为一张发票、一套用量分析、一个预算控制。财务团队对此的重视程度远超工程团队的预期。“我们有一个AI供应商”比”我们有三个AI供应商,且每个供应商的月度支出都在变化”更容易管理。
还有一个更微妙的信号:5月5日GPT-5.5 Instant作为新的ChatGPT默认模型发布——OpenAI官方公告也有记录——在API中以chat-latest推送。固定使用该别名的团队自动获得了升级。固定使用特定版本日期的团队则没有。平台可以为你提供跨服务商统一的抽象,而不需要你分别追踪每个服务商的版本规则。
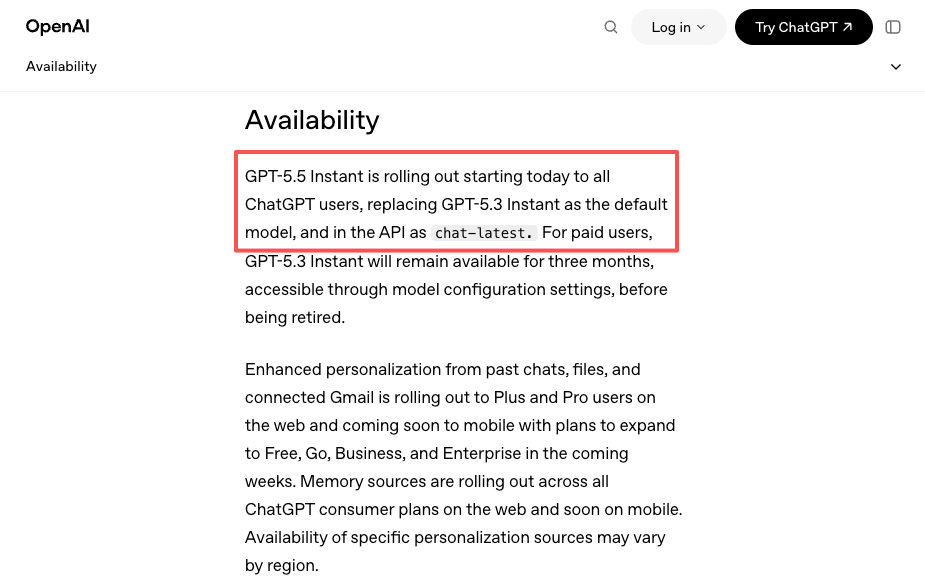
按团队类型划分的决策框架
我不喜欢博客文章里的框架表格,因为它们过于简化。但粗略的经验法则在这里有用,所以:
| 团队特征 | 可能更适合 | 原因 |
|---|---|---|
| 独立开发者,单一模型,单一产品 | 直接接入OpenAI | 路由层增加成本,但没有解决真实问题 |
| 生产团队,纯OpenAI技术栈,依赖服务商特定功能 | 直接接入OpenAI | 第一天即可访问Responses API、结构化输出等 |
| 生产团队,评估中使用多模型,计划持续多模型 | 平台 | 切换成本是主导变量 |
| 对LLM支撑功能有严格可用性SLA的团队 | 平台 | 备用链路是最低成本的保险 |
| 运行内部工具、非面向客户的团队 | 两者皆可 | 选择运维开销更小的那个 |
| 有采购流程和每个供应商安全审查的企业 | 平台 | 一份合同胜过N份合同 |
| 比较前沿模型的研究/实验团队 | 平台 | 模型切换就是整个工作流 |
| 依赖第一天访问全新模型版本的团队 | 有零日覆盖的平台,或高层级的直接服务商接入 | 两者都可行,但层级资格比人们想象的更重要 |
这张表不是定论,而是一个起始问题:哪一行最接近我的团队,这对我的默认架构意味着什么?
常见问题

什么时候直接接入OpenAI就够了?
当你已经选定OpenAI、使用量还不足以支撑单独协商平台合同,且没有明确的故障转移需求时。大多数运行OpenAI生产工作负载的中小型团队都属于这种情况。
为什么团队会在上面增加一个模型平台?
最常见的三个原因:无需改代码的多模型路由、中断或部分发布期间的故障转移、跨服务商的统一账单。如果这三点目前都不适用于你,你现在可能确实不需要它。
平台在部分发布期间有帮助吗?
有——但仅限于”我需要一个可用的前沿模型,而我首选的那个还不可用”这种故障模式。如果你明确需要GPT-5.5且只要GPT-5.5,平台帮不了你。平台可以从列表中路由到当前最佳可用模型,但无法凭空获得OpenAI还未发布的模型访问权。
多一个抽象层带来哪些权衡?
你在自己和模型之间增加了一个供应商。 这意味着多一个状态页、多一个账单来源、多一个潜在的故障点、有时要多付少量加价,偶尔还有服务商特定功能的延迟。这些都不是决定性因素,但它们是真实的成本,你应该将其纳入考量。
结论
诚实地说,直接接入OpenAI对很多团队来说是正确答案——可能比平台倡导者承认的更多。模型平台对很多其他团队来说是正确答案——可能比OpenAI独占派承认的更多。这种分化不是意识形态问题,而是关于你实际使用多少个模型、你的可用性方案对LLM的依赖程度,以及当下一个前沿模型发布时你能承受多大的切换成本。
GPT-5.5的发布是一次有用的压力测试,因为它在两周内有三个节点:ChatGPT先上线,API晚了一天,Instant变体在十二天后推出。每个使用前沿模型的团队都将反复经历这种模式。值得在今天,在风平浪静的时候,决定好下次面对这一切时你想持有的是哪种架构。
用你自己的情况算一算,那会比这篇文章告诉你更多。
往期文章:




