Напрямую через OpenAI или через платформу для GPT-5.5?
Стоит ли командам получать доступ к GPT-5.5 напрямую через OpenAI или через платформу моделей? Сравниваем скорость развёртывания, резервирование, маршрутизацию и операционный контроль.

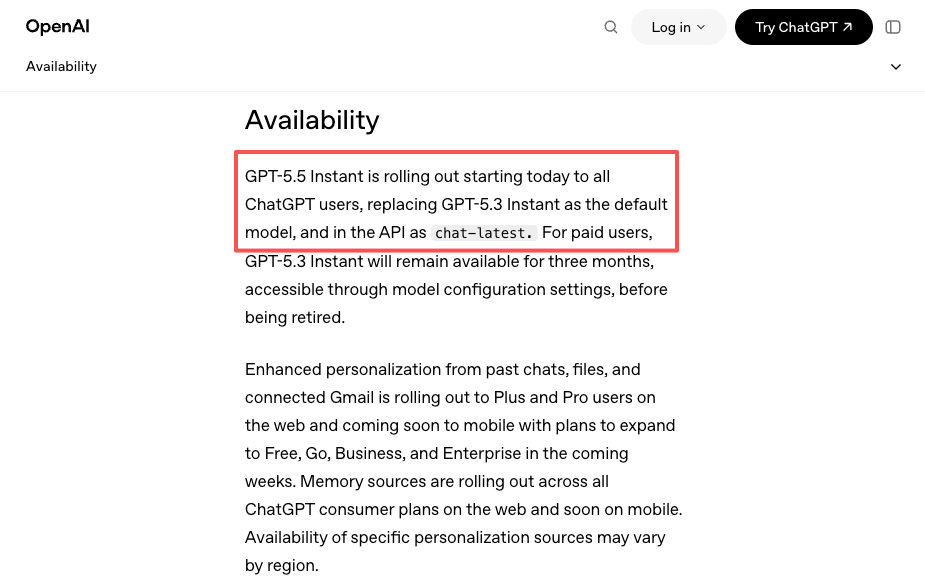
GPT-5.5 появился в ChatGPT и Codex 23 апреля. API вышел днём позже — 24 апреля. Затем 5 мая GPT-5.5 Instant стал моделью ChatGPT по умолчанию и появился в API как chat-latest. Три разных момента выхода за две недели, каждый с разными условиями доступа по уровням и разными поверхностями.
Меня зовут Дора. Я отслеживала это, потому что была вынуждена. Один из моих рабочих процессов задействует модели GPT-5, и 24-часовой разрыв между выходом ChatGPT и выходом API был для меня не теоретическим. Он означал либо ожидание, либо маршрутизацию через то, что уже имело доступ. Это решение — ждать или маршрутизировать — то же самое решение, которое каждая команда, использующая передовую модель, должна принимать при каждом выпуске. Поэтому эта статья именно об этом.
Вопрос не в том, «хороша ли OpenAI». Вопрос в следующем: когда GPT-5.5 (или следующая модель) выходит поэтапно, вы обращаетесь к OpenAI напрямую или стоите за платформой, которая управляет поэтапным выходом за вас? Оба ответа правильны для разных команд. Ниже — то, что я вижу, глядя на это честно.
Два способа получить доступ к GPT-5.5
Прямой доступ к провайдеру
Вы обращаетесь к api.openai.com с ключом OpenAI. Один SDK, один набор документации, один счёт. Когда OpenAI выпускает новое название модели, вы меняете строку в конфигурации и начинаете её использовать — при условии, что ваш уровень имеет доступ с первого дня.
Цены указаны на официальной странице цен OpenAI: GPT-5.5 — $5/млн входящих и $30/млн исходящих токенов, GPT-5.5 Pro — $30/млн входящих и $180/млн исходящих. Примерно вдвое дороже GPT-5.4. Вы платите напрямую OpenAI.
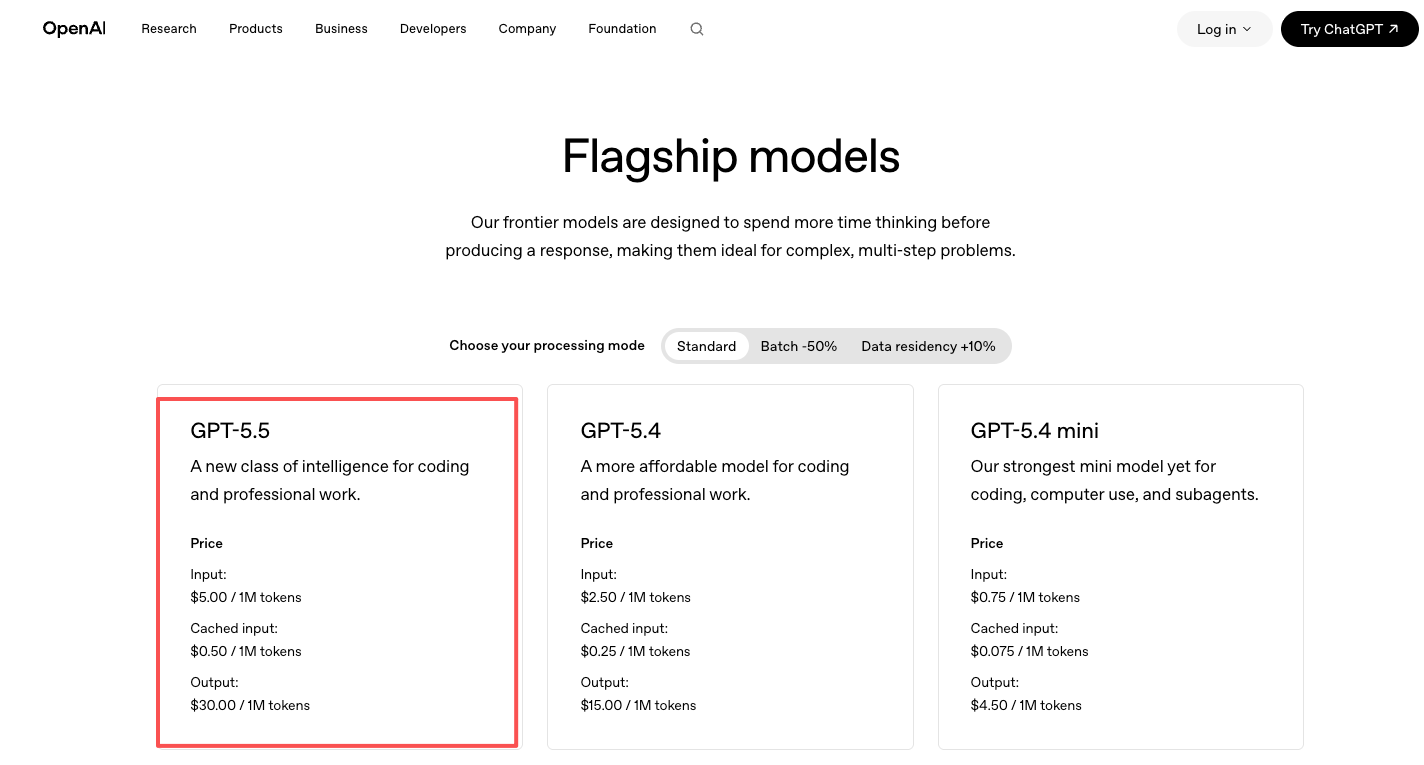
Доступ через платформу моделей
Вы обращаетесь к уровню маршрутизации — OpenRouter, LiteLLM, внутреннему шлюзу или мультимодельной платформе — и этот уровень общается с OpenAI от вашего имени. Такой же формат OpenAI SDK (большинство платформ совместимы с OpenAI), но строка модели может указывать на GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro или цепочку резервных вариантов по всем трём.
Вы платите платформе. Платформа платит OpenAI. Есть небольшая наценка, иногда нет. Взамен вы получаете один счёт по всем провайдерам, переключение моделей без изменений кода и резервный путь на случай сбоев.
Вот и вся картина. Ни один из вариантов не «лучше». Они оптимизированы под разные задачи.
Когда выигрывает прямой доступ
Простота, меньше абстракций и оптимизация под конкретного провайдера
Если вы используете только модели OpenAI, прямое обращение к OpenAI — это максимально простая архитектура. Один вендор. Один набор кодов ошибок. Одна страница статуса для мониторинга. Когда что-то ломается, вы знаете, к кому обращаться.
Важно также и то, что OpenAI выпускает функции, которые не всегда сразу доступны через уровни абстракции. Responses API. Управление усилиями при рассуждениях. Структурированные выходные данные со строгими схемами. Поверхность инструмента Codex. Форматы вызова инструментов, специфичные для провайдера. Платформенный уровень в конечном счёте наверстает отставание, но «в конечном счёте» может означать недели. Если ваш продукт зависит от конкретной функции OpenAI с первого дня, прямой путь — единственный путь.
Есть и реальная стоимость косвенности, о которой никто не говорит. Каждый уровень между вашим кодом и моделью — это ещё одно место, где что-то может пойти не так, ещё одна страница статуса чужой команды для мониторинга, ещё один неожиданный счёт в конце месяца. Для небольшой команды, запускающей одну модель в продакшне, эти накладные расходы могут перевесить преимущества.
Когда одной модели достаточно
Многим командам действительно нужна только одна модель. Они выбрали GPT-5 год назад, рабочий процесс работает, промпты настроены, оценки стабильны. Они не хотят проводить A/B-тесты с Claude. Они не хотят переключаться на Gemini при сбоях. Они хотят, чтобы модель продолжала работать, а счёт оставался предсказуемым.
Для такой команды уровень маршрутизации решает проблему, которой у них нет. Прямой доступ — правильный ответ, а добавление платформы поверх — неправильный. Не платите налог на сложность ради опциональности, которой вы не воспользуетесь.
Когда выигрывает платформа моделей
Скорость выхода, резервирование и управление маршрутизацией
Вот где хронология GPT-5.5 действительно имела значение. Между 23 и 24 апреля GPT-5.5 был доступен в ChatGPT, но не в API. CNBC сообщал в то время, что OpenAI указала на «разные меры безопасности» для выхода API без указания даты. Для большинства команд этот 24-часовой разрыв был ничем. Для некоторых — тех, у кого есть контрактное обязательство «мы выпускаем новейшую модель в течение X часов» — это была проблема.
Платформенный уровень не делает OpenAI быстрее. Но он меняет то, как выглядит «ожидание». Пока GPT-5.5 ещё не был в API OpenAI, Claude Opus 4.7 уже был. Gemini 3.1 Pro был. Настройка с маршрутизацией может предпочитать GPT-5.5 после его появления, переключаться на любую доступную в данный момент передовую модель и не требовать развёртывания кода при изменении ситуации.
Та же логика применима к простоям. У OpenAI были многочасовые инциденты с API в этом году. Как и у каждого другого провайдера. Если ваш продукт жёстко требует «работающего LLM прямо сейчас», вы либо создаёте резервный вариант самостоятельно, либо позволяете платформе справиться с этим. Как документация по резервным вариантам OpenRouter, так и документация по маршрутизатору LiteLLM описывают это в конкретной конфигурации: объявите основную модель, перечислите резервные варианты, получите рабочий ответ при сбое основной.
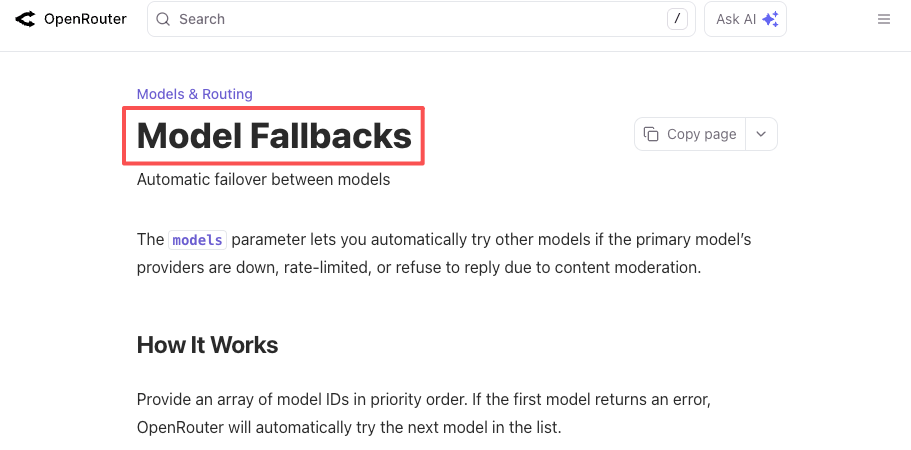
Это не гипотетический сценарий. Я дважды сталкивалась с ним в этом квартале.
Эксперименты с несколькими моделями и устойчивость закупок
Другое место, где платформа оправдывает себя, — когда вы ещё не знаете, какая модель подходит для задачи, или когда подозреваете, что ответ изменится через шесть месяцев.
Лидерство среди передовых моделей меняется примерно каждые 3–6 месяцев. Выходит GPT-5.5, затем Anthropic выпускает свою версию, затем Google, и ответ на вопрос «лучшая модель для кода» или «лучшая модель для анализа длинного контекста» продолжает меняться. Если вы интегрировались с SDK одного провайдера, переключение означает реальную инженерную работу. Если вы стоите за уровнем маршрутизации, переключение означает изменение строки модели.
Та же логика применима к закупкам. Платформа объединяет расходы по всем провайдерам в один счёт, один набор аналитики использования, один контроль бюджета. Финансовые команды заботятся об этом больше, чем инженерные команды осознают. «У нас один AI-вендор» легче администрировать, чем «у нас три AI-вендора, и расходы на каждого меняются ежемесячно».
И есть ещё один менее очевидный сигнал: выход GPT-5.5 Instant 5 мая в качестве нового умолчания ChatGPT — освещённый в собственном объявлении OpenAI — вышел как chat-latest в API. Команды, привязанные к этому псевдониму, получили обновление автоматически. Команды, привязанные к конкретной дате версии, — нет. Платформа может дать вам единую абстракцию над обоими вариантами поведения у всех провайдеров, вместо того чтобы вы отслеживали правила версионирования каждого провайдера отдельно.
Система принятия решений по типу команды
Я не люблю таблицы с фреймворками в блог-постах, потому что они упрощают. Но приблизительная эвристика здесь помогает:
| Профиль команды | Скорее всего лучший вариант | Причина |
|---|---|---|
| Разработчик-одиночка, одна модель, один продукт | Прямой OpenAI | Уровень маршрутизации добавляет затраты, не решая реальной проблемы |
| Продакшн-команда, только OpenAI, зависит от специфичных для провайдера функций | Прямой OpenAI | Доступ с первого дня к Responses API, структурированным выходным данным и т.д. |
| Продакшн-команда, несколько моделей в оценках, планирует оставаться мультимодельной | Платформа | Стоимость переключения — доминирующая переменная |
| Команда со строгим SLA по uptime для функции на основе LLM | Платформа | Цепочки резервирования — самая дешёвая страховка |
| Команда с внутренними инструментами, не для клиентов | Любой | Выберите тот, у которого меньше накладных расходов на эксплуатацию |
| Предприятие с закупками, проверкой безопасности на каждого вендора | Платформа | Один контракт лучше N контрактов |
| Исследовательская команда / команда экспериментирования, сравнивающая передовые модели | Платформа | Переключение моделей — весь рабочий процесс |
| Команда, зависящая от доступа с первого дня к совершенно новым версиям моделей | Платформа с охватом с нулевого дня или прямой провайдер с высоким уровнем | Оба варианта работают, но право на доступ по уровням важнее, чем люди думают |
Таблица не является вердиктом. Это отправная точка: какая строка наиболее близка к моей команде, и что это подразумевает о моей архитектуре по умолчанию?
Часто задаваемые вопросы

Когда прямой интеграции с OpenAI достаточно?
Когда вы уже выбрали OpenAI, объём использования недостаточно велик для обоснования заключения отдельного контракта с платформой, и у вас нет явной потребности в резервировании на другой провайдер. Большинство малых и средних команд, запускающих продакшн-нагрузки OpenAI, попадают сюда.
Зачем командам добавлять платформу моделей поверх?
Три причины, которые встречаются чаще всего: мультимодельная маршрутизация без изменений кода, резервирование при простоях или частичных выходах и консолидированный биллинг по провайдерам. Если ничто из этого к вам сейчас не относится, вам, вероятно, это сейчас не нужно.
Помогает ли платформа при частичных запусках?
Да — но только для сценария «мне нужна работающая передовая модель, а та, которую я предпочитаю, ещё недоступна». Это не помогает, если вам конкретно нужен GPT-5.5 и только GPT-5.5. Платформа может направить к лучшей доступной модели из списка. Она не может обеспечить доступ к модели, которую OpenAI ещё не выпустила.
Какие компромиссы несёт ещё один уровень?
Вы добавляете вендора между собой и моделью. Это означает ещё одну страницу статуса, ещё одну биллинговую поверхность, ещё одну потенциальную точку отказа, иногда небольшую наценку и иногда задержку с функциями, специфичными для провайдера. Ни одно из них не является критическим. Это реальные затраты, которые следует учитывать.
Заключение
Честная версия такова. Прямой OpenAI — правильный ответ для многих команд — вероятно, больше, чем признают сторонники платформ. Платформа моделей — правильный ответ для многих других команд — вероятно, больше, чем признают сторонники только OpenAI. Разделение не идеологическое. Оно связано с тем, сколько моделей вы фактически используете, насколько ваши обязательства по uptime зависят от LLM и какую стоимость переключения вы готовы терпеть, когда выйдет следующая передовая модель.
Выход GPT-5.5 был полезным стресс-тестом, потому что он имел три момента за две недели: сначала ChatGPT, API — днём позже, вариант Instant — двенадцать дней спустя. Каждая команда, использующая передовую модель, будет снова и снова переживать версии этой схемы. Стоит решить уже сейчас, в спокойный день, с какой архитектурой вы хотите встретить следующий раз.
Просчитайте математику применительно к вашей установке. Это скажет вам больше, чем этот пост.
Предыдущие публикации:
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение

GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене

Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов

MAI-Image-2.5 API: что нужно знать разработчикам
