OpenAI Direto ou uma Plataforma para o GPT-5.5?
As equipes devem acessar o GPT-5.5 diretamente pela OpenAI ou por meio de uma plataforma de modelos? Compare velocidade de lançamento, fallback, roteamento e controle operacional.

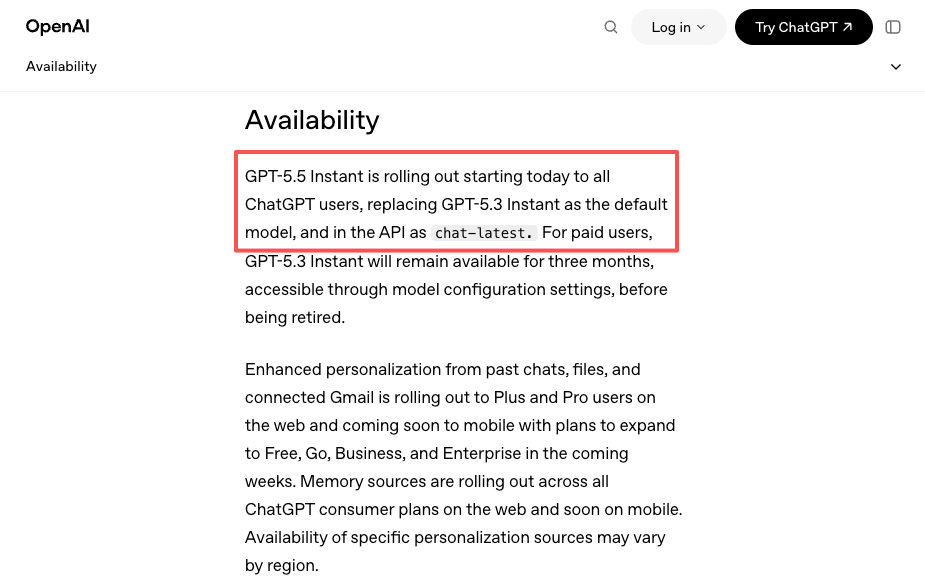
GPT-5.5 foi lançado no ChatGPT e no Codex em 23 de abril. A API chegou um dia depois, em 24 de abril. Depois, em 5 de maio, o GPT-5.5 Instant tornou-se o modelo padrão do ChatGPT e foi disponibilizado na API como chat-latest. Três momentos de lançamento diferentes em duas semanas, cada um com diferentes critérios de elegibilidade por nível e diferentes superfícies.
Aqui é a Dora. Acompanhei isso porque precisava. Um dos meus fluxos de trabalho usa modelos GPT-5, e a lacuna de 24 horas na API entre o lançamento no ChatGPT e o lançamento na API não foi teórica para mim. Significou esperar, ou redirecionar para algo que já tinha acesso. Essa decisão — esperar ou redirecionar — é a mesma decisão que toda equipe usando um modelo de fronteira precisa tomar a cada lançamento. Por isso este artigo é sobre isso.
A questão não é “a OpenAI é boa”. É: quando o GPT-5.5 (ou o que vier a seguir) for lançado em etapas, você chama a OpenAI diretamente, ou fica atrás de uma plataforma que lida com o escalonamento por você? As duas respostas estão corretas para equipes diferentes. Abaixo está o que vejo quando analiso isso honestamente.
As Duas Formas de as Equipes Acessarem o GPT-5.5
Acesso direto ao provedor
Você acessa api.openai.com com uma chave da OpenAI. Um SDK, um conjunto de documentação, uma fatura. Quando a OpenAI lança um novo nome de modelo, você muda uma string na sua configuração e está usando — assumindo que seu nível tem acesso no primeiro dia.
Os preços estão na página oficial de preços da OpenAI: GPT-5.5 a $5/M de entrada e $30/M de saída, GPT-5.5 Pro a $30/M de entrada e $180/M de saída. Aproximadamente o dobro do GPT-5.4. Você paga diretamente à OpenAI.
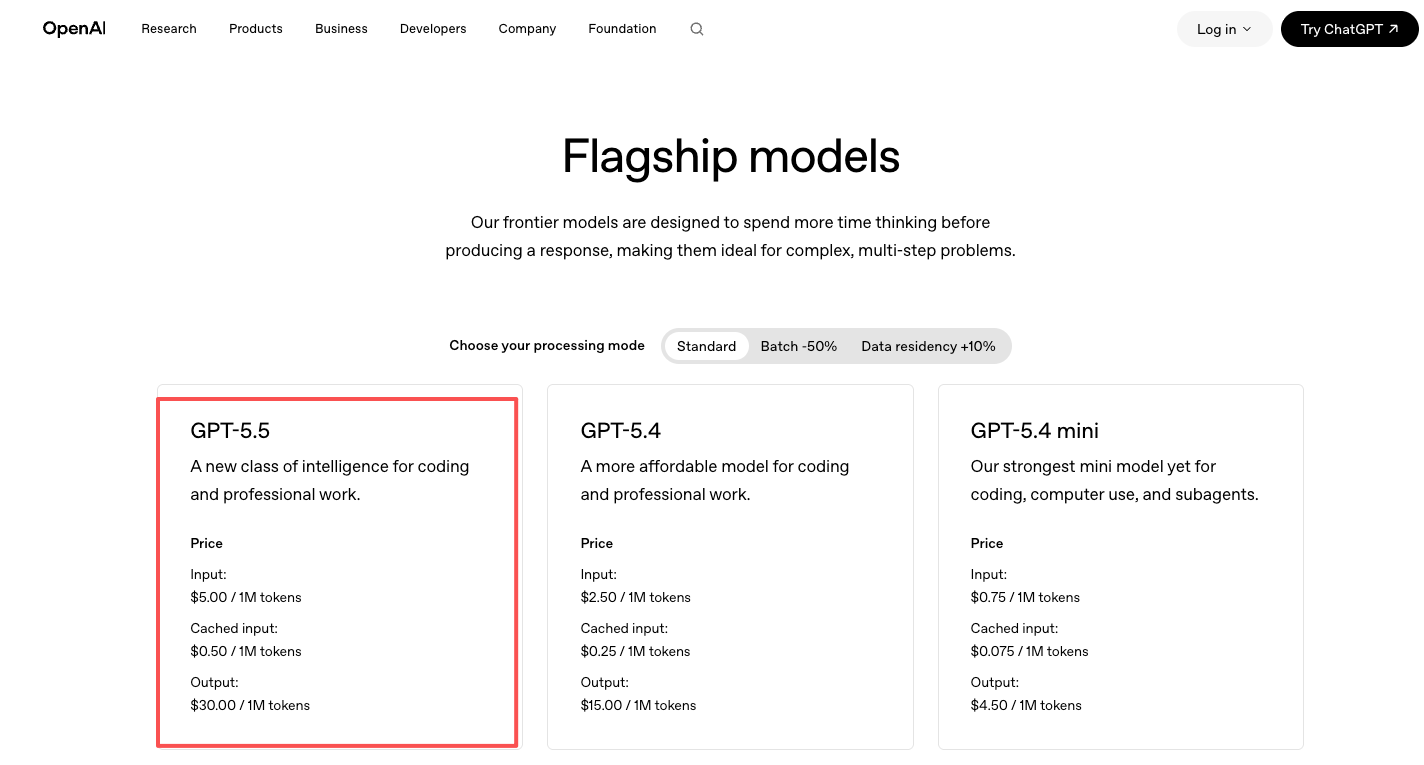
Acesso por meio de uma plataforma de modelos
Você acessa uma camada de roteamento — OpenRouter, LiteLLM, um gateway interno ou uma plataforma multi-modelo — e essa camada fala com a OpenAI em seu nome. Mesmo formato do SDK da OpenAI (a maioria das plataformas é compatível com OpenAI), mas a string do modelo pode apontar para GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro ou uma cadeia de fallback entre os três.
Você paga à plataforma. A plataforma paga à OpenAI. Há uma pequena margem, às vezes nenhuma. Em troca, você recebe uma fatura única entre provedores, troca de modelos sem alterações de código e um caminho de fallback quando algo quebra.
Esse é o quadro completo. Nenhum é “melhor”. Eles otimizam para coisas diferentes.
Onde o Acesso Direto Vence
Simplicidade, menor abstração e otimização específica do provedor
Se você usa apenas modelos OpenAI, chamar a OpenAI diretamente é a arquitetura mais simples possível. Um fornecedor. Um conjunto de códigos de erro. Uma página de status para monitorar. Quando algo quebra, você sabe a quem perguntar.
Também importa que a OpenAI lança recursos que nem sempre estão disponíveis imediatamente por camadas de abstração. API de Respostas. Controles de esforço de raciocínio. Saídas estruturadas com schemas rígidos. A superfície da ferramenta Codex. Formatos de chamada de ferramentas específicos do provedor. Uma camada de plataforma eventualmente alcança, mas “eventualmente” pode significar semanas. Se seu produto depende de um recurso específico da OpenAI no primeiro dia, o caminho direto é o único caminho.
Há também um custo real na indireção que ninguém menciona. Cada camada entre seu código e o modelo é mais um lugar onde algo pode dar errado, mais uma página de status de outra equipe para monitorar, mais uma surpresa na fatura no final do mês. Para uma equipe pequena rodando um modelo em produção, esse overhead pode superar o benefício.
Quando um único modelo é suficiente
Muitas equipes genuinamente precisam de apenas um modelo. Escolheram o GPT-5 há um ano, o fluxo de trabalho funciona, os prompts estão ajustados, as avaliações estão estáveis. Eles não querem fazer A/B contra o Claude. Não querem fazer fallback para o Gemini. Querem que o modelo continue funcionando e a fatura continue sendo previsível.
Para essa equipe, uma camada de roteamento está resolvendo um problema que eles não têm. O acesso direto é a resposta certa, e adicionar uma plataforma por cima é a resposta errada. Não pague o imposto de complexidade por opcionalidade que você não vai usar.
Onde uma Plataforma de Modelos Vence
Velocidade de lançamento, fallback e controle de roteamento
É aqui que a linha do tempo do GPT-5.5 realmente importou. Entre 23 e 24 de abril, o GPT-5.5 estava ativo no ChatGPT, mas não na API. A CNBC noticiou na época que a OpenAI sinalizou “diferentes salvaguardas” para o lançamento na API, sem data comprometida. Para a maioria das equipes, essa lacuna de 24 horas era irrelevante. Para algumas — qualquer equipe com um contratual “lançamos o modelo mais recente em X horas” — era um problema.
Uma camada de plataforma não acelera a OpenAI. Mas muda como “esperar” parece. Enquanto o GPT-5.5 ainda não estava na API da OpenAI, o Claude Opus 4.7 estava. O Gemini 3.1 Pro estava. Uma configuração roteada pode preferir o GPT-5.5 assim que ele chegar, fazer fallback para qualquer modelo de fronteira disponível no momento e não exigir um deploy de código quando a situação mudar.
A mesma lógica se aplica a interrupções. A OpenAI teve incidentes de API de várias horas este ano. Todos os outros provedores também. Se seu produto requer estritamente “um LLM que funcione agora”, você constrói o fallback você mesmo ou deixa uma plataforma gerenciar isso. Tanto a documentação de fallback do OpenRouter quanto a documentação do roteador do LiteLLM descrevem isso em configuração concreta: declare um modelo primário, liste fallbacks, obtenha uma resposta funcional quando o primário falhar.
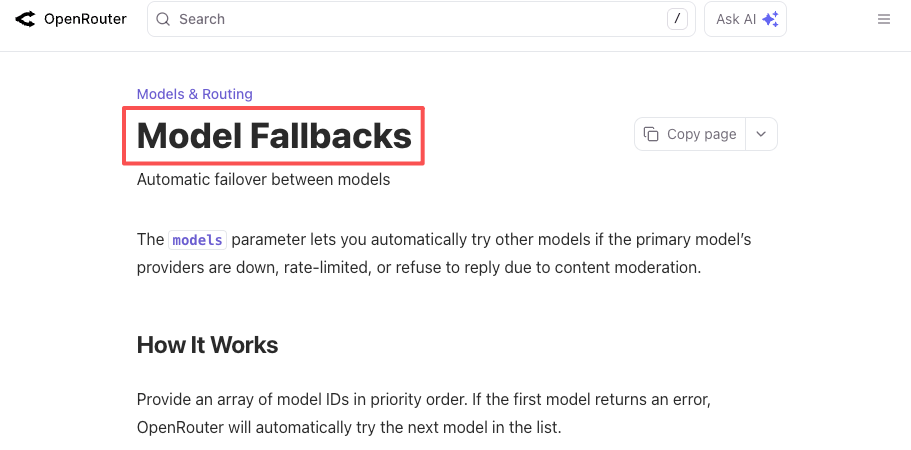
Isso não é um cenário hipotético. É um cenário que já enfrentei duas vezes neste trimestre.
Experimentação multi-modelo e resiliência de aquisição
O outro lugar onde uma plataforma mostra seu valor é quando você ainda não sabe qual modelo é o certo para o trabalho — ou quando suspeita que essa resposta mudará em seis meses.
A liderança de modelos de fronteira está girando em algo como um ciclo de 3 a 6 meses. O GPT-5.5 é lançado, depois a Anthropic lança, depois o Google lança, e a resposta para “melhor modelo para código” ou “melhor modelo para análise de longo contexto” continua mudando. Se você integrou contra o SDK de um único provedor, mudar significa trabalho real de engenharia. Se estiver atrás de uma camada de roteamento, mudar significa alterar uma string de modelo.
A mesma lógica se aplica à aquisição. Uma plataforma consolida os gastos entre provedores em uma única fatura, um conjunto de análises de uso, um controle de orçamento. As equipes financeiras se importam com isso mais do que as equipes de engenharia percebem. “Temos um fornecedor de IA” é mais fácil de governar do que “temos três fornecedores de IA e os gastos por fornecedor mudam mensalmente.”
E há um sinal mais suave: o lançamento em 5 de maio do GPT-5.5 Instant como o novo padrão do ChatGPT — coberto no próprio anúncio da OpenAI — saiu como chat-latest na API. Equipes fixadas nesse alias receberam a atualização automaticamente. Equipes fixadas em uma data de versão específica não receberam. Uma plataforma pode fornecer uma abstração unificada sobre ambos os comportamentos entre provedores, em vez de você rastrear as regras de versionamento de cada provedor separadamente.
Um Framework de Decisão por Tipo de Equipe
Não gosto de tabelas de framework em posts de blog porque simplificam demais. Mas uma heurística aproximada ajuda aqui:
| Perfil da equipe | Melhor opção provável | Razão |
|---|---|---|
| Dev solo, um modelo, um produto | OpenAI direto | Camada de roteamento adiciona custo sem resolver um problema real |
| Equipe de produção, stack apenas OpenAI, depende de recursos específicos do provedor | OpenAI direto | Acesso no primeiro dia à API de Respostas, saídas estruturadas, etc. |
| Equipe de produção, multi-modelo em avaliações, planeja continuar multi-modelo | Plataforma | Custo de troca é a variável dominante |
| Equipe com SLA rigoroso de uptime em um recurso baseado em LLM | Plataforma | Cadeias de fallback são o seguro mais barato |
| Equipe rodando ferramentas internas, não voltadas ao cliente | Qualquer um | Escolha o que tiver menos overhead de ops para você |
| Empresa com aquisição, revisão de segurança por fornecedor | Plataforma | Um contrato supera N contratos |
| Equipe de pesquisa/experimentação comparando modelos de fronteira | Plataforma | Troca de modelo é o fluxo de trabalho inteiro |
| Equipe que depende de acesso no primeiro dia a novas versões de modelos | Plataforma com cobertura zero-day, ou provedor direto com nível alto | Ambos funcionam, mas elegibilidade de nível importa mais do que as pessoas pensam |
A tabela não é um veredicto. É uma pergunta inicial: qual linha está mais próxima da minha equipe, e o que isso implica sobre minha arquitetura padrão?
FAQ

Quando a integração direta com a OpenAI é suficiente?
Quando você já escolheu a OpenAI, seu volume de uso não é grande o suficiente para justificar a negociação de um contrato de plataforma separado, e você não tem uma necessidade explícita de fallback para outro provedor. A maioria das equipes pequenas e médias rodando cargas de trabalho OpenAI em produção se encaixa aqui.
Por que equipes adicionariam uma plataforma de modelos?
As três razões que aparecem com mais frequência: roteamento multi-modelo sem alterações de código, fallback durante interrupções ou lançamentos parciais e faturamento consolidado entre provedores. Se nenhuma delas se aplica a você agora, provavelmente você não precisa disso agora.
Uma plataforma ajuda durante lançamentos parciais?
Sim — mas apenas para a falha de “preciso de um modelo de fronteira funcionando e o que prefiro ainda não está disponível.” Não ajuda se você especificamente precisa do GPT-5.5 e apenas do GPT-5.5. Uma plataforma pode rotear para o melhor modelo disponível de uma lista. Não pode criar acesso a um modelo que a OpenAI ainda não lançou.
Quais trade-offs vêm com mais uma camada?
Você adiciona um fornecedor entre você e o modelo. Isso significa mais uma página de status, mais uma superfície de faturamento, mais um ponto potencial de falha, às vezes uma pequena margem e ocasionalmente um atraso em recursos específicos do provedor. Nenhum desses é um impedimento absoluto. São custos reais que você deve considerar.
Conclusão
A versão honesta é esta. OpenAI direto é a resposta certa para muitas equipes — provavelmente mais do que a turma evangelizadora de plataformas admite. Uma plataforma de modelos é a resposta certa para muitas outras equipes — provavelmente mais do que a turma OpenAI-only admite. A divisão não é ideológica. É sobre quantos modelos você realmente usa, o quanto a sua história de uptime depende do LLM e quanto custo de troca você pode suportar quando o próximo modelo de fronteira for lançado.
O lançamento do GPT-5.5 foi um teste de estresse útil porque teve três momentos em duas semanas: ChatGPT primeiro, API um dia depois, variante Instant doze dias após isso. Toda equipe usando um modelo de fronteira vai viver versões desse padrão repetidamente. Vale a pena decidir agora, em um dia tranquilo, qual arquitetura você quer ter na próxima vez.
Faça as contas para o seu próprio setup. Isso vai lhe dizer mais do que este post.
Posts Anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
