Claude Opus 4.7: Por que equipes de IA precisam de uma camada de API de modelo unificada
O Claude Opus 4.7 está chegando. Veja por que lançamentos frequentes de modelos expõem o custo real das integrações diretas com API — e o que as equipes de IA estão fazendo a respeito.

A conclusão primeiro: a parte mais difícil do Claude Opus 4.7 não é o modelo. É a migração.
Eu — Dora — gerencio pipelines de geração de IA para conteúdo em produção. Imagens, vídeo, orquestração multi-modelo. Quando a Anthropic lançou o Opus 4.6 em fevereiro, minha equipe passou quatro dias revalidando prompts, ajustando orçamentos de tokens e corrigindo uma discrepância de cobrança que só apareceu no terceiro dia. Agora, menos de dois meses depois, a Anthropic lançou o Opus 4.7 com um novo tokenizador, mudanças de API incompatíveis e um novo nível de esforço. Se você é a pessoa da sua equipe que mantém a camada de integração de modelos, você já sente o peso dessa frase.
Este artigo documenta o que foi confirmado sobre o Opus 4.7 até agora, o que a esteira de atualizações realmente custa às equipes de engenharia, e quando a matemática começa a favorecer uma camada de agregação em vez de APIs diretas do provedor.

O Que Sabemos Sobre o Claude Opus 4.7 (E O Que Ainda Não Foi Confirmado)
As informações: confirmadas vs. rumores
O Opus 4.7 ficou disponível ao público em 16 de abril de 2026. O ID do modelo é claude-opus-4-7. O preço permanece em $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída — igual ao Opus 4.6. A janela de contexto de 1M de tokens não mudou. A saída máxima continua sendo 128k tokens.
O que mudou: suporte a visão em alta resolução de até 3,75 megapixels (mais do que o triplo do limite de 1,15 MP do 4.6), um novo nível de esforço xhigh entre alto e máximo, e orçamentos de tarefas para loops agênticos — um recurso beta que fornece ao modelo uma contagem regressiva de tokens ao longo de todo um fluxo de trabalho multi-turno.
As mudanças incompatíveis importam mais do que os recursos. Os orçamentos de pensamento estendido foram removidos. Os parâmetros de amostragem foram eliminados. O novo tokenizador processa o mesmo texto em aproximadamente 1,0–1,35x mais tokens dependendo do tipo de conteúdo. O preço por token é fixo, mas sua fatura real pode aumentar até 35% sem você alterar um único prompt.
O que mudou do Opus 4.6 para o 4.7 — por que isso importa para desenvolvedores
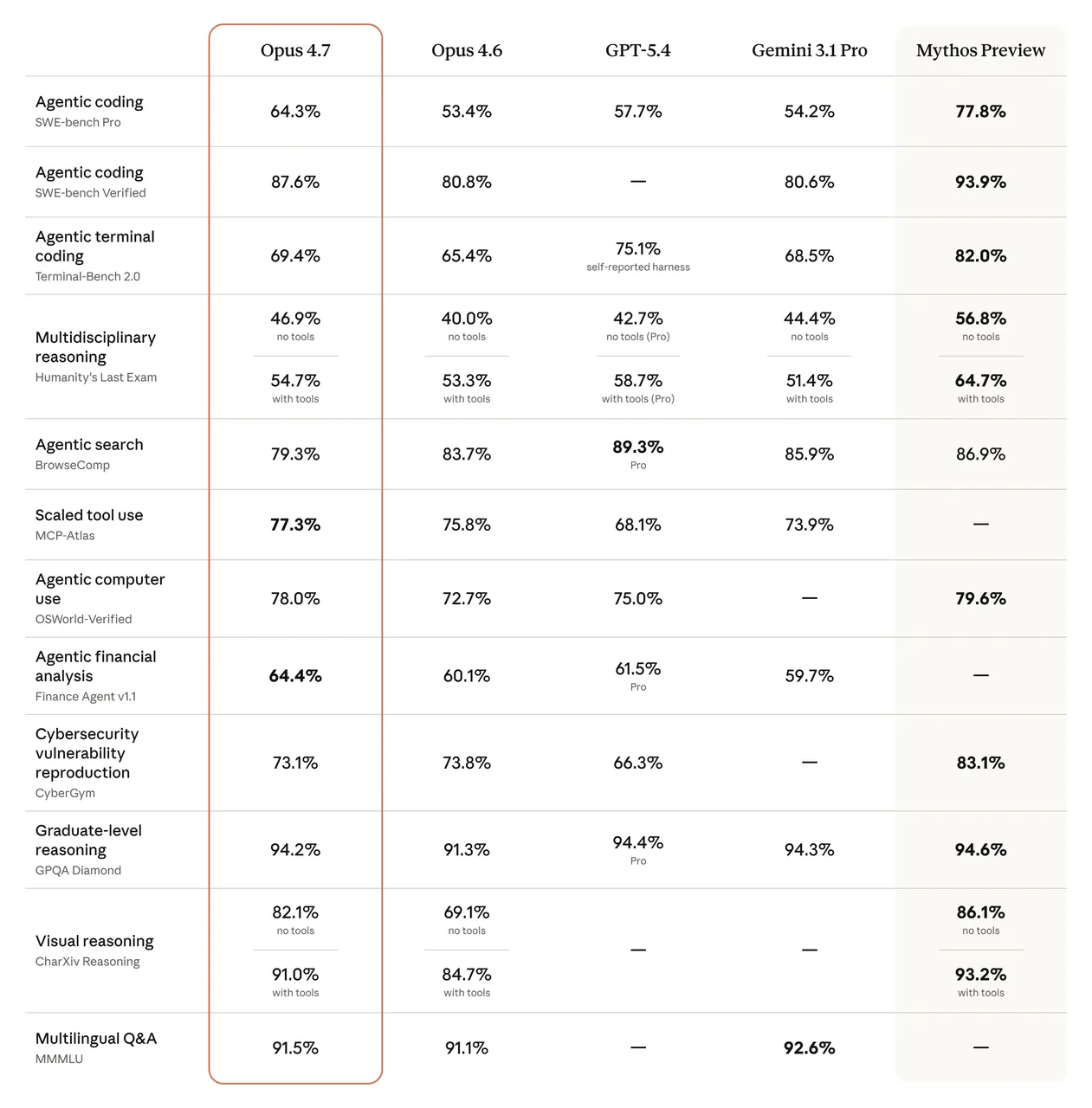
Os números de benchmark são reais. O SWE-bench Verified passou de 80,8% para 87,6%. O CursorBench saltou de 58% para 70%. No SWE-bench Pro, o Opus 4.7 pontua 64,3% — acima dos 53,4% do 4.6 e à frente do GPT-5.4 com 57,7%.
Mas aqui está a parte que realmente afeta as equipes de produção: o Opus 4.7 segue instruções de forma mais literal. Prompts que eram “soltos” ou conversacionais com o 4.6 podem produzir resultados rígidos ou inesperados. Se você passou semanas ajustando bibliotecas de prompts, essa mudança comportamental significa re-testar — não apenas trocar uma string de modelo.
O Problema Real Não é o Novo Modelo — É a Esteira de Atualizações
O que “um novo Claude todo mês” realmente custa a uma equipe de engenharia
A Anthropic lançou o Opus 4.5 em novembro de 2025. O Opus 4.6 em fevereiro de 2026. O Opus 4.7 em abril de 2026. São três versões principais do modelo em cinco meses. Cada uma trouxe mudanças de parâmetros, mudanças comportamentais ou atualizações de API incompatíveis.
O custo de engenharia de cada atualização não é a troca do modelo. É o loop de validação. Testes de regressão de prompts. Recalibração do orçamento de tokens. Atualizações de projeção de cobrança. Testes de fumaça de integração em staging e produção. Para meus fluxos de trabalho, cada migração consome de três a cinco dias de engenharia — e isso para uma equipe que já fez isso antes.
Risco de versionamento: quando seus prompts quebram após uma atualização de modelo
O guia de migração para o Opus 4.7 é transparente sobre isso. O tokenizador atualizado significa que /v1/messages/count_tokens retorna números diferentes para a mesma entrada. Se seu sistema tem limites max_tokens codificados diretamente, eles agora podem cortar a saída prematuramente. Se você dependia de prefill ou parâmetros de amostragem, esses foram removidos.
Já vi equipes tratarem atualizações de modelos como atualizações de dependências — trocar a string de versão, executar os testes, enviar para produção. Essa abordagem parou de funcionar em torno do Opus 4.5.
Quem sofre mais: equipes de API direta vs. camada de agregação
Equipes que chamam a API da Anthropic diretamente absorvem cada mudança incompatível por conta própria. Equipes por trás de uma camada de agregação — um middleware que normaliza APIs de provedores em uma única interface — absorvem de uma vez, centralmente. A diferença se multiplica. Três atualizações de provedor por ano em dois ou três provedores significa seis a nove eventos de migração. As camadas de agregação transformam isso em uma atualização de configuração.
Isso não é hipotético. Eu mantenho integrações com múltiplos provedores de modelos. As roteadas por uma camada unificada levaram horas para atualizar. As diretas levaram dias.
Como as Equipes de Produtos de IA Estão Estruturando o Acesso a Modelos em 2026
API direta do provedor: quando ainda faz sentido
A API direta vence quando você precisa de acesso no dia zero a novos recursos, quando sua carga de trabalho explora capacidades específicas do provedor (como os orçamentos de tarefas do Opus 4.7), ou quando você está tão profundamente inserido em um provedor que o custo de troca é efetivamente zero porque você não está trocando.
Se todo o seu produto é construído no Claude e apenas no Claude, e você tem a capacidade de engenharia para absorver mudanças incompatíveis trimestrais, a API direta ainda é o caminho direto.
Camada de agregação: quando a matemática do custo de troca se inverte
O ponto de inflexão é o uso multi-modelo combinado com atualizações frequentes do provedor. Uma vez que você está chamando o Claude para raciocínio, um modelo diferente para classificação e um terceiro para embeddings — e cada provedor lança mudanças incompatíveis em seu próprio cronograma — a sobrecarga de coordenação começa a consumir tempo real de engenharia.
De acordo com a previsão do Gartner, cerca de 40% das aplicações empresariais incorporarão agentes de IA específicos para tarefas até o final de 2026. Cada agente pode chamar um modelo diferente. Gerenciar isso por meio de APIs diretas do provedor não é errado — é simplesmente caro de uma forma que aparece como horas de engenheiro, não em uma fatura.
A lista de verificação de avaliação antes de migrar para qualquer nova versão do Claude
Antes de trocar claude-opus-4-6 por claude-opus-4-7 em produção, existe uma lista curta que eu percorro: testes de impacto do tokenizador (execute seus prompts reais pelo count_tokens em ambas as versões e compare), regressão de comportamento de prompts (a mudança de instrução literal vai aparecer aqui), atualização de projeção de cobrança (o aumento de tokens de 1,0–1,35x depende do conteúdo — meça nos seus dados, não nas médias da Anthropic), e auditoria de dependência de recursos (verifique se você está usando algo que foi removido ou alterado).
Se sua equipe não consegue fazer isso em menos de um dia, isso é um sinal sobre sua arquitetura, não sobre o modelo.
O Que Observar Após o Lançamento Oficial do Opus 4.7
Cronograma de disponibilidade da API e níveis de acesso
O Opus 4.7 já está disponível na API do Claude, Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry. Os planos Claude Pro, Max, Team e Enterprise têm acesso. Os limites de taxa são agrupados entre as versões do Opus, para que você possa executar tráfego do 4.6 e do 4.7 lado a lado durante a migração.
Preços vs. 4.6 — confirmado vs. especulativo
A tabela de preços é idêntica. $5/$25 por milhão de tokens. O cache de prompts ainda oferece até 90% de economia; o processamento em lote ainda dá 50% de desconto. Mas a mudança no tokenizador significa que o custo efetivo por prompt é maior — o quanto maior depende da sua combinação de conteúdo. Código denso? Espere algo mais próximo de 1,35x. Prompts conversacionais curtos? Mais próximo de 1,0x.
Uma coisa que ainda estou observando: o novo tokenizador do Opus 4.7 supostamente lida com conteúdo multilíngue de forma diferente. Para equipes que processam texto em outros idiomas além do inglês em escala, a inflação de tokens pode ser ainda maior que 35%. Ainda não tenho dados suficientes sobre isso.
Sinais de compatibilidade: janela de contexto, uso de ferramentas, saída estruturada
Janela de contexto: 1M tokens, inalterada. Uso de ferramentas: mesmo conjunto do 4.6 — bash, execução de código, uso de computador, editor de texto, pesquisa na web, conector MCP. Saída estruturada: suportada. O cartão de sistema do Opus 4.7 observa que o modelo é mais minucioso na auto-verificação de saídas, o que significa que parte do scaffolding de prompts existente (“verifique novamente o layout do slide antes de retornar”) pode ser removido.
Vale notar a relação com o Claude Mythos: o Opus 4.7 está explicitamente posicionado como o campo de testes para salvaguardas que a Anthropic eventualmente quer implantar em modelos da classe Mythos. O Opus 4.7 carrega detecção automatizada de uso cibernético que o Mythos Preview não tem na mesma forma. Isso não é diretamente relevante para a integração de API — mas sinaliza para onde o roadmap de modelos da Anthropic está indo.
Perguntas Frequentes
O Claude Opus 4.7 está disponível via API?
Sim. Ficou disponível ao público em 16 de abril de 2026. O ID do modelo é claude-opus-4-7. Disponível na API direta da Anthropic, Amazon Bedrock, Google Vertex AI e Microsoft Foundry.
Como os preços do Opus 4.7 se comparam ao Opus 4.6?
A tabela de preços é idêntica: $5 por milhão de tokens de entrada, $25 por milhão de tokens de saída. Mas o tokenizador atualizado pode inflar as contagens reais de tokens em até 35%, o que significa que o mesmo prompt pode custar mais para executar no 4.7 do que no 4.6.
Posso executar o Claude Opus 4.7 por meio de uma API de inferência de terceiros?
Sim. Múltiplas plataformas de agregação e camadas de roteamento suportam o Opus 4.7. A questão principal é se a camada de terceiros expõe recursos específicos do 4.7 como orçamentos de tarefas e o nível de esforço xhigh, ou apenas passa as conclusões padrão.
Qual é a diferença entre o Claude Opus 4.7 e o Claude Mythos?
O Mythos Preview é o modelo mais poderoso da Anthropic, restrito a parceiros selecionados sob o Projeto Glasswing para trabalho defensivo de segurança cibernética. O Opus 4.7 está disponível ao público e carrega salvaguardas automatizadas que a Anthropic está testando antes de eventualmente ampliar o acesso da classe Mythos. São diferentes níveis de capacidade com diferentes modelos de acesso.
Minha equipe deve esperar pelo Opus 4.7 ou continuar no 4.6 para produção?
Se seus prompts estão bem testados no 4.6 e seu sistema está funcionando bem, não se apresse. Pilote o 4.7 em uma pequena fatia de tráfego, meça o impacto do tokenizador e as mudanças de comportamento dos prompts, depois migre em etapas. O modelo é melhor — mas a migração não tem custo zero.
Ainda estou executando o 4.6 e o 4.7 em paralelo nos meus próprios pipelines. Os ganhos de benchmark são reais, mas o re-ajuste de prompts também é. Terei mais dados em uma ou duas semanas sobre se a sobrecarga do tokenizador se compensa com os ganhos de eficiência de menos chamadas de ferramentas. Essa parte ainda não está resolvida.
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber