GPT-5.5はOpenAI直接アクセスとプラットフォーム経由、どちらが最適か?
GPT-5.5にOpenAI直接アクセスとモデルプラットフォーム経由のどちらでアクセスすべきか?展開速度、フォールバック、ルーティング、運用制御を比較します。

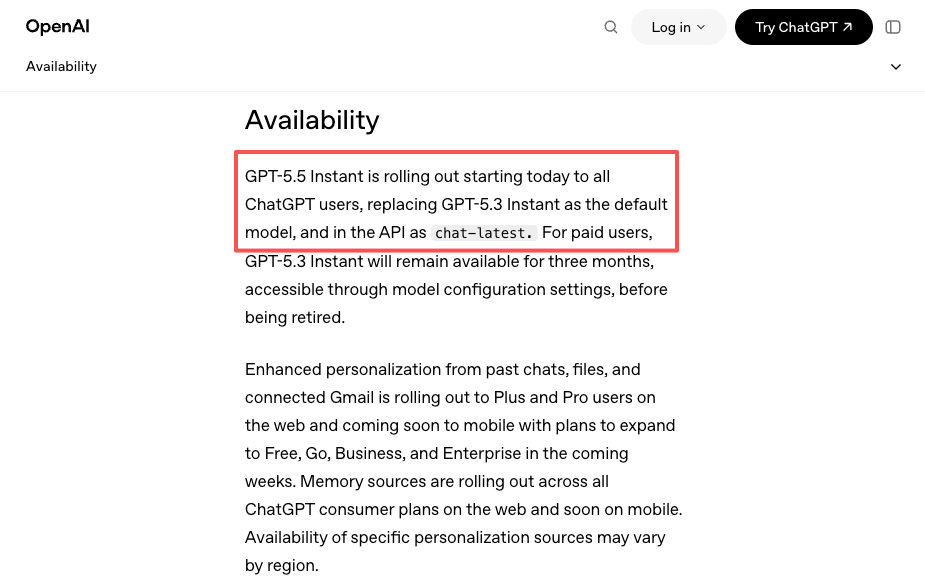
GPT-5.5は4月23日にChatGPTとCodexでローンチされた。APIはその翌日、4月24日に公開された。そして5月5日、GPT-5.5 InstantがデフォルトのChatGPTモデルとなり、chat-latestとしてAPIにも展開された。2週間以内に3つの異なるリリースタイミング、それぞれ異なるティア対象と異なるサービス。
Doraです。追わざるを得なかったから追った。私のワークフローはGPT-5系モデルに触れており、ChatGPTリリースとAPIリリースの間に生じた24時間のギャップは理論上の話ではなかった。待つか、すでにアクセス可能な別の手段を経由させるか――その選択だった。待つかルーティングするかという判断は、フロンティアモデルを使うすべてのチームが、あらゆるリリースのたびに迫られる判断だ。だからこの記事はその話をする。
問いは「OpenAIは良いか」ではない。GPT-5.5(あるいは次に来るもの)が段階的にリリースされるとき、OpenAIに直接呼ぶのか、段階的展開を肩代わりしてくれるプラットフォームの背後に座るのか、どちらを選ぶか、だ。どちらの答えも、チームによっては正しい。以下は、正直に見たときに見えてくるものだ。
GPT-5.5へのアクセス方法は2つある
プロバイダー直接アクセス
OpenAIキーを使ってapi.openai.comを叩く。1つのSDK、1セットのドキュメント、1枚の請求書。OpenAIが新しいモデル名を出したとき、設定の文字列を変えるだけで使える――自分のティアがday oneからアクセスできる場合は。
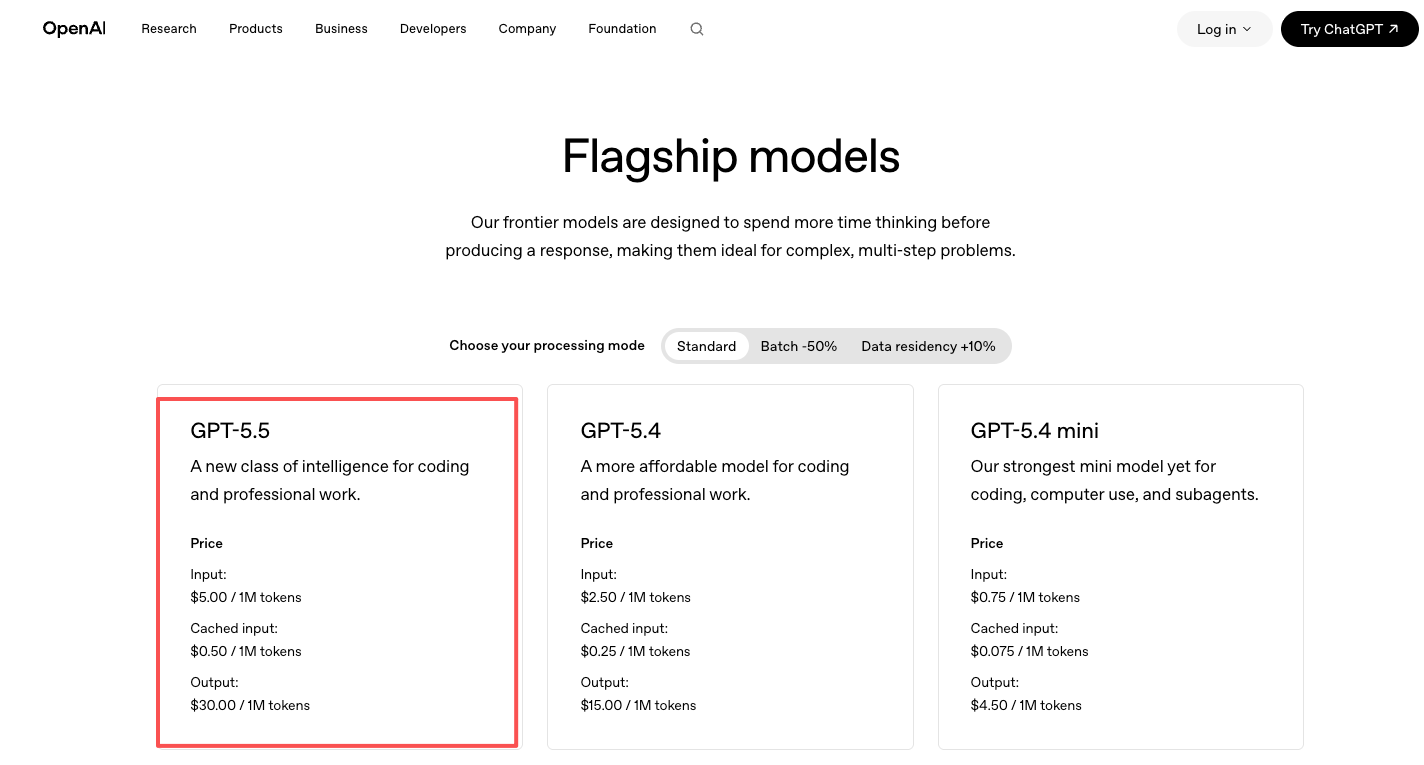
料金はOpenAI公式料金ページに記載されている:GPT-5.5は入力$5/M・出力$30/M、GPT-5.5 Proは入力$30/M・出力$180/M。GPT-5.4のほぼ2倍。支払いはOpenAIに直接行う。
モデルプラットフォーム経由のアクセス
ルーティングレイヤーを叩く――OpenRouter、LiteLLM、社内ゲートウェイ、またはマルチモデルプラットフォーム――そのレイヤーがOpenAIと通信する。SDKの形状は同じ(ほとんどのプラットフォームはOpenAI互換)だが、モデル文字列はGPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro、あるいは3つ全体にまたがるフォールバックチェーンを指せる。
支払いはプラットフォームに。プラットフォームがOpenAIに払う。わずかなマークアップがある場合も、ない場合もある。その代わりに、プロバイダーをまたいだ一本化された請求書、コード変更なしのモデル切り替え、何かが壊れたときのフォールバックパスが手に入る。
全体像はこれだけだ。どちらが「優れている」わけでもない。それぞれ異なるものを最適化している。
直接アクセスが勝る場面
シンプルさ、低い抽象化、プロバイダー固有の最適化
OpenAIモデルしか使わないなら、OpenAIに直接呼ぶのが最もシンプルなアーキテクチャだ。ベンダー1社。エラーコード1セット。監視するステータスページ1つ。何かが壊れたとき、誰に聞けばいいかわかる。
OpenAIが出荷する機能が抽象化レイヤーを経由するとすぐには使えないことも重要だ。Responses API。推論エフォートの制御。厳格なスキーマによる構造化出力。Codexのツールサーフェス。プロバイダー固有のツール呼び出し形式。プラットフォームレイヤーはいずれ追いつくが、「いずれ」は数週間を意味することもある。製品が特定のOpenAI機能にday oneから依存しているなら、直接パスが唯一の選択肢だ。
間接参照のコストについて誰も語らないが、これは現実のコストだ。コードとモデルの間に入る層は1つ増えるごとに、何かが起きる可能性がある場所が1つ、監視すべきチームのステータスページが1つ、月末の請求の驚きが1つ増える。1つのモデルをプロダクションで動かす小さなチームにとっては、そのオーバーヘッドがメリットを上回ることがある。
モデルが1つで十分なとき
多くのチームは本当に1つのモデルしか必要としていない。1年前にGPT-5を選んだ、ワークフローは機能している、プロンプトはチューニング済み、評価は安定している。Claudeとのオルタネーションは不要。Geminiへのフェイルオーバーも不要。モデルが動き続け、請求が予測可能であれば十分、というチームだ。
そのチームにとって、ルーティングレイヤーは存在しない問題を解こうとしている。直接アクセスが正解であり、その上にプラットフォームを追加するのは誤りだ。使わないオプショナリティのために複雑性のコストを払うな。
モデルプラットフォームが勝る場面
ロールアウト速度、フォールバック、ルーティング制御
ここがGPT-5.5のタイムラインが実際に重要だった部分だ。4月23日から24日の間、GPT-5.5はChatGPTでライブだったがAPIではなかった。CNBCが当時報じたところによると、OpenAIはAPIロールアウトに「異なるセーフガード」があると示しながら、具体的な日程を示さなかった。ほとんどのチームにとってその24時間のギャップは何でもなかった。しかし一部のチーム――「最新モデルをX時間以内に展開する」という契約条項を持つチーム――にとっては問題だった。
プラットフォームレイヤーはOpenAIを速くしない。しかし「待つ」ことの意味を変える。GPT-5.5がOpenAI APIにまだない間、Claude Opus 4.7はあった。Gemini 3.1 Proもあった。ルーティング設定はGPT-5.5が利用可能になったら優先し、現在利用可能なフロンティアモデルにフォールバックし、状況が変わってもコードデプロイを必要としない。
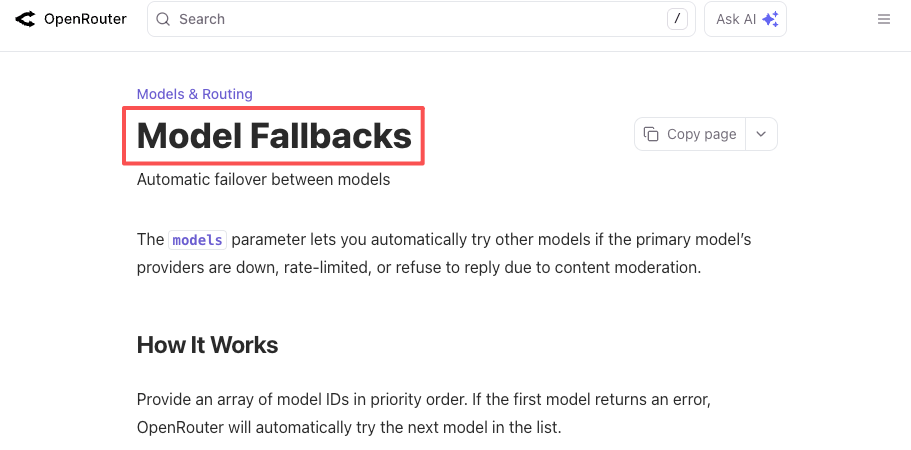
同じ論理は障害にも適用される。OpenAIは今年、数時間にわたるAPIインシデントを経験している。他のすべてのプロバイダーも同様だ。製品が「今すぐ動くLLM」を硬く要求しているなら、フォールバックを自分で構築するか、プラットフォームに任せるかだ。OpenRouterのフォールバックドキュメントとLiteLLMのルータードキュメントはどちらも具体的な設定で説明している:プライマリモデルを宣言し、フォールバックをリストし、プライマリが失敗したとき動くレスポンスを得る。
これは仮定のシナリオではない。今四半期に2回経験したシナリオだ。
マルチモデル実験と調達の耐障害性
プラットフォームがその価値を発揮するもう一つの場面は、どのモデルが仕事に最適かまだわからないとき――あるいはその答えが6ヶ月後に変わると予想されるときだ。
フロンティアモデルのリーダーシップは3〜6ヶ月サイクルで交代している。GPT-5.5が出る、次にAnthropicが出す、次にGoogleが出す、そして「コードに最適なモデル」や「長文脈分析に最適なモデル」という答えは動き続ける。単一プロバイダーのSDKに対して統合していれば、切り替えは実際のエンジニアリング作業を意味する。ルーティングレイヤーの後ろにいれば、切り替えはモデル文字列を変えることを意味する。
同じ論理は調達にも適用される。プラットフォームはプロバイダーをまたいだ支出を1枚の請求書、1セットの使用状況分析、1つの予算管理に集約する。財務チームはエンジニアリングチームが気づく以上にこれを重視している。「AIベンダーは1社」という管理は「AIベンダーが3社あり、ベンダーごとの支出が毎月変わる」より簡単だ。
そしてもう少し柔らかいシグナルがある:5月5日の新ChatGPTデフォルトとしてのGPT-5.5 Instantのリリース――OpenAI自身のアナウンスで触れられた――はAPIでchat-latestとして展開された。そのエイリアスを固定していたチームは自動的にアップグレードされた。特定バージョン日付を固定していたチームはされなかった。プラットフォームは、各プロバイダーのバージョニングルールを個別に追う代わりに、プロバイダーをまたいだ両方の動作に対して統一された抽象化を提供できる。
チームタイプ別の意思決定フレームワーク
ブログ記事のフレームワーク表は過度に単純化されるから好きではない。しかしここでは大まかなヒューリスティックが役立つので:
| チームのプロフィール | おそらく合う選択 | 理由 |
|---|---|---|
| 個人開発者、モデル1つ、プロダクト1つ | OpenAI直接 | ルーティングレイヤーは実際の問題を解かずにコストを追加するだけ |
| プロダクションチーム、OpenAI専用スタック、プロバイダー固有機能に依存 | OpenAI直接 | Responses API、構造化出力などへのday oneアクセス |
| プロダクションチーム、評価でマルチモデル使用、マルチモデル継続予定 | プラットフォーム | 切り替えコストが支配的な変数 |
| LLM依存機能に厳格な稼働率SLAを持つチーム | プラットフォーム | フォールバックチェーンが最も安い保険 |
| 社内ツール運用、顧客向けでないチーム | どちらでも | 運用オーバーヘッドが少ない方を選ぶ |
| 調達・ベンダーごとのセキュリティレビューがある企業 | プラットフォーム | 1契約がN契約より優れる |
| フロンティアモデルを比較する研究・実験チーム | プラットフォーム | モデル切り替えがワークフローの全体 |
| 新しいモデルバージョンへのday oneアクセスに依存するチーム | day zeroカバレッジのあるプラットフォーム、または高ティアの直接プロバイダー | どちらも機能するが、ティア対象は思われている以上に重要 |
この表は判決ではない。 出発点となる問いだ:自分のチームに最も近い行はどこか、それは自分のデフォルトアーキテクチャについて何を示唆しているか。
FAQ

OpenAI直接統合で十分なのはいつか?
OpenAIをすでに選んでおり、使用量が別のプラットフォーム契約交渉を正当化するほど大きくなく、別プロバイダーへのフォールバックに明示的なニーズがないとき。プロダクションでOpenAIワークロードを動かしている小〜中規模チームの多くはここに当てはまる。
なぜチームがモデルプラットフォームを上乗せするのか?
最も多く出てくる3つの理由:コード変更なしのマルチモデルルーティング、障害や部分ロールアウト時のフォールバック、プロバイダーをまたいだ一括請求。今のあなたにこれらのいずれも当てはまらないなら、今は必要ないだろう。
部分ローンチ時にプラットフォームは役立つか?
役立つ ――ただし「動くフロンティアモデルが必要だが、優先するものがまだ利用できない」という失敗モードに限る。GPT-5.5が必要でGPT-5.5だけが必要な場合は役立たない。プラットフォームはリストから利用可能な最良のモデルにルーティングできる。OpenAIがまだ出荷していないモデルへのアクセスを作り出すことはできない。
別のレイヤーを加えることのトレードオフは?
モデルとの間にベンダーを追加することになる。 それは別のステータスページ、別の請求サーフェス、別の潜在的な障害点、場合によっては小さなマークアップ、そしてプロバイダー固有機能への遅延を意味する。これらはいずれも致命的ではない。しかし価格に含めるべき現実のコストだ。
まとめ
正直なところはこうだ。OpenAI直接は多くのチームにとって正解――おそらくプラットフォーム推進派が認める以上に多い。モデルプラットフォームは多くの他のチームにとって正解――おそらくOpenAI専一派が認める以上に多い。分岐はイデオロギー的なものではない。実際に何種類のモデルを使っているか、稼働率の話がLLMにどれだけ依存しているか、次のフロンティアモデルが出たときにどれだけの切り替えコストに耐えられるか、の話だ。
GPT-5.5のロールアウトは有用なストレステストだった。2週間の中に3つのタイミングがあったから:まずChatGPT、1日後にAPI、その12日後にInstantバリアント。フロンティアモデルを使うすべてのチームは、このパターンの繰り返しを何度も経験することになる。穏やかな今日、次のときにどのアーキテクチャを持っていたいかを決めておく価値がある。
自分のセットアップに対して計算してみろ。それがこの記事よりも多くを教えてくれる。
関連記事:




