Langsung dari OpenAI atau Platform untuk GPT-5.5?
Haruskah tim mengakses GPT-5.5 langsung dari OpenAI atau melalui platform model? Bandingkan kecepatan peluncuran, fallback, routing, dan kontrol operasional.

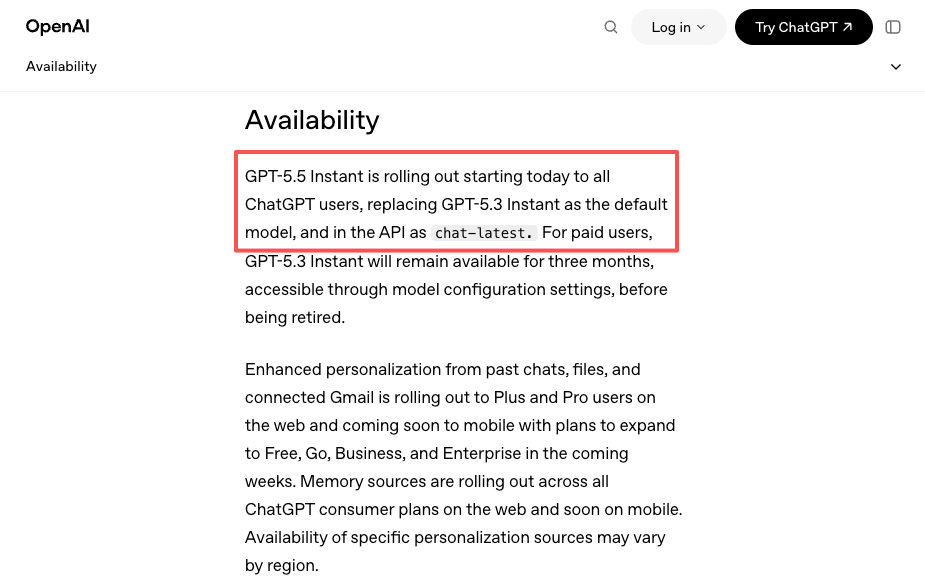
GPT-5.5 diluncurkan di ChatGPT dan Codex pada 23 April. API-nya hadir sehari kemudian, pada 24 April. Kemudian pada 5 Mei, GPT-5.5 Instant menjadi model ChatGPT default dan dikirimkan ke API sebagai chat-latest. Tiga momen peluncuran berbeda dalam dua minggu, masing-masing dengan kelayakan tier yang berbeda dan permukaan yang berbeda.
Saya Dora. Saya memantau ini karena saya harus melakukannya. Salah satu alur kerja saya menyentuh model GPT-5, dan kesenjangan API 24 jam antara rilis ChatGPT dan rilis API bukan hal teoritis bagi saya. Artinya harus menunggu, atau merutekan melalui sesuatu yang sudah memiliki akses. Keputusan itu — tunggu atau rute — adalah keputusan yang sama yang harus dibuat setiap tim yang menggunakan model frontier pada setiap rilis. Jadi tulisan ini membahas hal tersebut.
Pertanyaannya bukan “apakah OpenAI bagus.” Pertanyaannya adalah: ketika GPT-5.5 (atau apa pun yang berikutnya) dikirimkan secara bertahap, apakah Anda memanggil OpenAI secara langsung, atau apakah Anda berada di balik platform yang menangani pentahapan untuk Anda? Kedua jawaban benar untuk tim yang berbeda. Berikut adalah apa yang saya lihat ketika saya memandangnya secara jujur.
Dua Cara Tim Mengakses GPT-5.5
Akses langsung ke penyedia
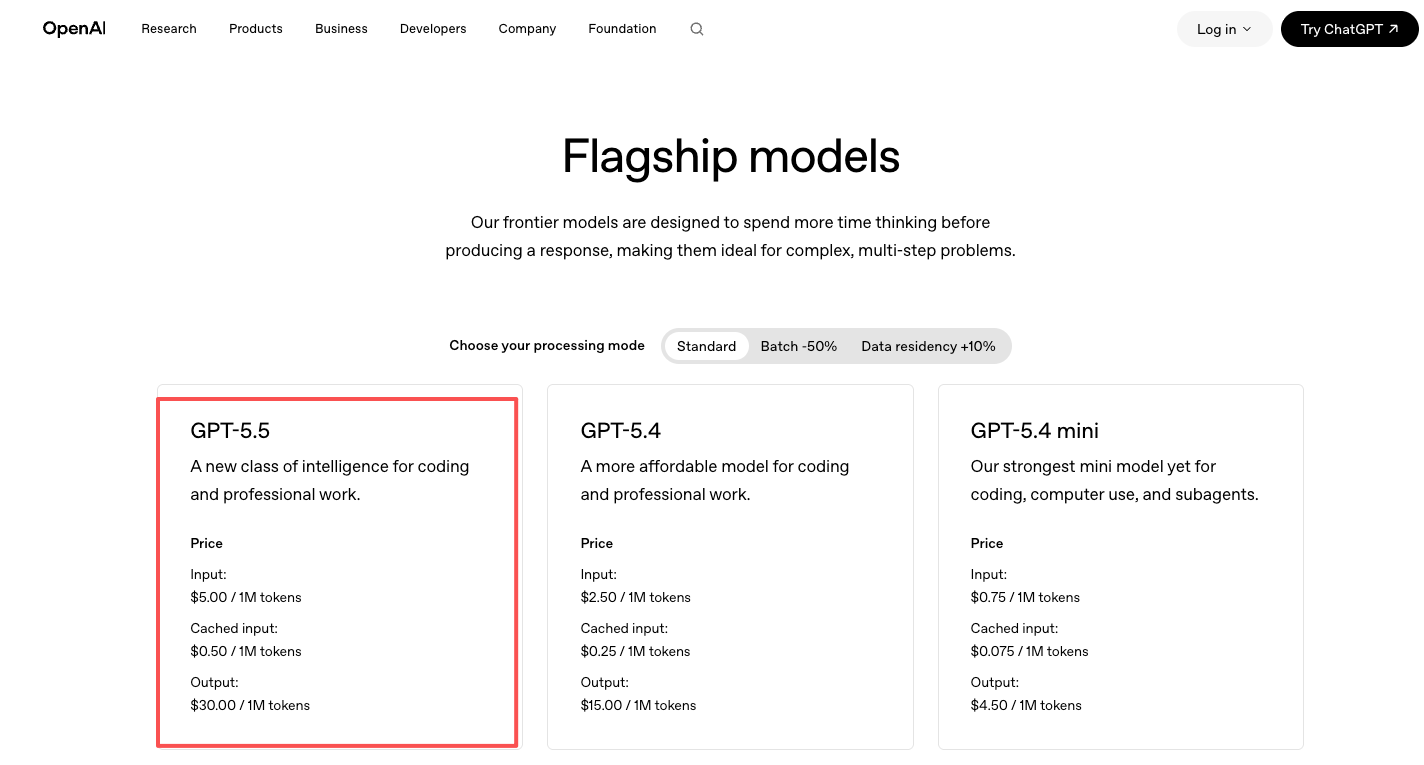
Anda menghubungi api.openai.com dengan kunci OpenAI. Satu SDK, satu set dokumentasi, satu tagihan. Ketika OpenAI mengirimkan nama model baru, Anda mengubah sebuah string di konfigurasi Anda dan Anda menggunakannya — dengan asumsi tier Anda memiliki akses di hari pertama.
Harga ada di halaman harga resmi OpenAI: GPT-5.5 seharga $5/juta input dan $30/juta output, GPT-5.5 Pro seharga $30/juta input dan $180/juta output. Kira-kira dua kali lipat GPT-5.4. Anda membayar OpenAI secara langsung.
Akses melalui platform model
Anda menghubungi lapisan perutean — OpenRouter, LiteLLM, gateway internal, atau platform multi-model — dan lapisan tersebut berbicara ke OpenAI atas nama Anda. Bentuk SDK OpenAI yang sama (sebagian besar platform kompatibel dengan OpenAI), tetapi string model dapat menunjuk ke GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, atau rantai fallback di ketiganya.
Anda membayar platform. Platform membayar OpenAI. Ada markup kecil, terkadang tidak ada. Sebagai imbalannya, Anda mendapatkan satu tagihan di semua penyedia, pergantian model tanpa perubahan kode, dan jalur fallback ketika sesuatu rusak.
Itulah gambaran lengkapnya. Tidak ada yang “lebih baik.” Mereka mengoptimalkan hal yang berbeda.
Di Mana Akses Langsung Menang
Kesederhanaan, abstraksi lebih rendah, dan optimasi khusus penyedia
Jika Anda hanya menggunakan model OpenAI, memanggil OpenAI secara langsung adalah arsitektur paling sederhana yang mungkin. Satu vendor. Satu set kode kesalahan. Satu halaman status untuk dipantau. Ketika sesuatu rusak, Anda tahu kepada siapa harus bertanya.
Penting juga bahwa OpenAI mengirimkan fitur yang tidak selalu tersedia segera melalui lapisan abstraksi. Responses API. Kontrol upaya penalaran. Output terstruktur dengan skema ketat. Permukaan alat Codex. Format pemanggilan alat khusus penyedia. Lapisan platform pada akhirnya akan menyusul, tetapi “pada akhirnya” bisa berarti berminggu-minggu. Jika produk Anda bergantung pada fitur OpenAI tertentu di hari pertama, jalur langsung adalah satu-satunya jalur.
Ada juga biaya nyata dari indirection yang tidak pernah dibicarakan siapa pun. Setiap lapisan antara kode Anda dan model adalah satu tempat lagi di mana sesuatu bisa salah, satu halaman status tim lain lagi untuk dipantau, satu lagi kejutan tagihan di akhir bulan. Untuk tim kecil yang menjalankan satu model dalam produksi, overhead tersebut bisa melebihi manfaatnya.
Ketika satu model sudah cukup
Banyak tim yang memang hanya membutuhkan satu model. Mereka memilih GPT-5 setahun yang lalu, alur kerjanya berjalan, prompt-nya sudah disetel, evaluasinya stabil. Mereka tidak ingin melakukan A/B terhadap Claude. Mereka tidak ingin beralih ke Gemini. Mereka ingin model terus bekerja dan tagihan terus dapat diprediksi.
Untuk tim tersebut, lapisan perutean memecahkan masalah yang tidak mereka miliki. Akses langsung adalah jawaban yang tepat dan menambahkan platform di atasnya adalah jawaban yang salah. Jangan membayar pajak kompleksitas untuk opsi yang tidak akan Anda gunakan.
Di Mana Platform Model Menang
Kecepatan peluncuran, fallback, dan kontrol perutean
Di sinilah timeline GPT-5.5 benar-benar penting. Antara 23 April dan 24 April, GPT-5.5 aktif di ChatGPT tetapi tidak di API. CNBC melaporkan saat itu bahwa OpenAI menandai “pengamanan berbeda” untuk peluncuran API, tanpa tanggal yang pasti. Bagi sebagian besar tim, kesenjangan 24 jam itu tidak ada artinya. Bagi beberapa tim — siapa pun dengan kontrak “kami mengirimkan model terbaru dalam X jam” — itu adalah masalah.
Lapisan platform tidak membuat OpenAI lebih cepat. Tetapi lapisan ini mengubah tampilan “menunggu.” Sementara GPT-5.5 belum ada di API OpenAI, Claude Opus 4.7 sudah ada. Gemini 3.1 Pro sudah ada. Pengaturan yang diroute dapat memprioritaskan GPT-5.5 begitu tersedia, beralih ke model frontier mana pun yang saat ini tersedia, dan tidak memerlukan deploy kode ketika situasi berubah.
Logika yang sama berlaku untuk pemadaman. OpenAI mengalami insiden API multi-jam tahun ini. Begitu pula setiap penyedia lain. Jika produk Anda sangat membutuhkan “LLM yang bekerja sekarang,” Anda bisa membangun fallback sendiri atau membiarkan platform menanganinya. Baik dokumen fallback OpenRouter maupun dokumen router LiteLLM menjelaskan ini dalam konfigurasi konkret: deklarasikan model primer, daftarkan fallback, dapatkan respons yang berfungsi ketika primer gagal.
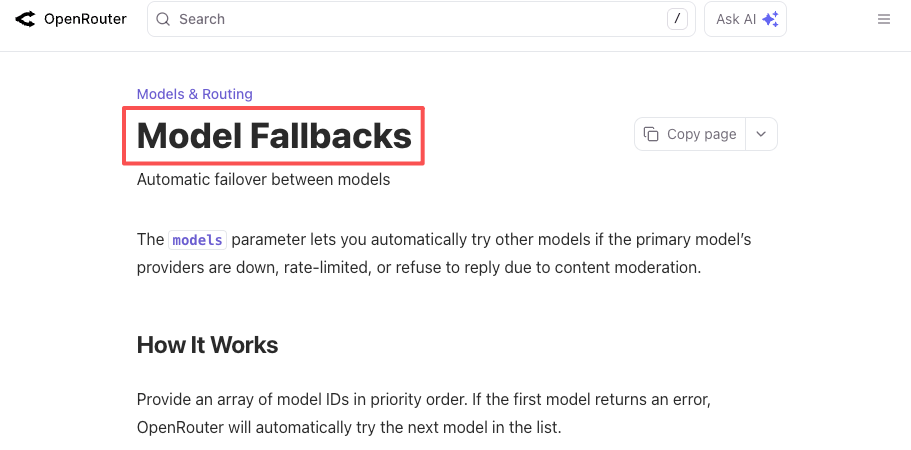
Ini bukan skenario hipotetis. Ini adalah skenario yang sudah saya hadapi dua kali kuartal ini.
Eksperimen multi-model dan ketahanan pengadaan
Tempat lain di mana platform membuktikan nilainya adalah ketika Anda belum tahu model mana yang tepat untuk pekerjaan — atau ketika Anda menduga jawaban itu akan berubah dalam enam bulan.
Kepemimpinan model frontier berputar dalam siklus sekitar 3 hingga 6 bulan. GPT-5.5 dikirimkan, lalu Anthropic mengirimkan, lalu Google mengirimkan, dan jawaban “model terbaik untuk kode” atau “model terbaik untuk analisis konteks panjang” terus bergerak. Jika Anda telah mengintegrasikan terhadap SDK satu penyedia, beralih berarti pekerjaan rekayasa yang nyata. Jika Anda berada di balik lapisan perutean, beralih berarti mengubah string model.
Logika yang sama berlaku untuk pengadaan. Platform mengkonsolidasikan pengeluaran di semua penyedia menjadi satu faktur, satu set analitik penggunaan, satu kontrol anggaran. Tim keuangan lebih peduli tentang ini daripada yang disadari tim rekayasa. “Kami memiliki satu vendor AI” lebih mudah dikelola daripada “kami memiliki tiga vendor AI dan pengeluaran per vendor berubah setiap bulan.”
Dan kemudian ada sinyal yang lebih halus: rilis GPT-5.5 Instant pada 5 Mei sebagai default ChatGPT baru — yang dibahas dalam pengumuman resmi OpenAI — dikirimkan sebagai chat-latest di API. Tim yang terpaku pada alias tersebut mendapatkan upgrade secara otomatis. Tim yang terpaku pada tanggal versi tertentu tidak mendapatkannya. Platform dapat memberikan Anda abstraksi terpadu atas kedua perilaku tersebut di seluruh penyedia, alih-alih Anda melacak aturan versi setiap penyedia secara terpisah.
Kerangka Keputusan Berdasarkan Tipe Tim
Saya tidak menyukai tabel kerangka dalam postingan blog karena terlalu menyederhanakan. Tetapi heuristik kasar membantu di sini, jadi:
| Profil tim | Kemungkinan lebih cocok | Alasan |
|---|---|---|
| Dev solo, satu model, satu produk | OpenAI langsung | Lapisan perutean menambah biaya tanpa memecahkan masalah nyata |
| Tim produksi, stack OpenAI saja, bergantung pada fitur khusus penyedia | OpenAI langsung | Akses hari pertama ke Responses API, output terstruktur, dll. |
| Tim produksi, multi-model dalam evaluasi, berencana tetap multi-model | Platform | Biaya peralihan adalah variabel dominan |
| Tim dengan SLA uptime ketat pada fitur berbasis LLM | Platform | Rantai fallback adalah asuransi termurah |
| Tim yang menjalankan alat internal, bukan menghadap pelanggan | Keduanya | Pilih yang memiliki overhead operasional lebih sedikit untuk Anda |
| Enterprise dengan pengadaan, tinjauan keamanan per vendor | Platform | Satu kontrak lebih baik dari N kontrak |
| Tim riset/eksperimen yang membandingkan model frontier | Platform | Pergantian model adalah seluruh alur kerja |
| Tim yang bergantung pada akses hari pertama ke versi model baru | Platform dengan cakupan hari-nol, atau penyedia langsung dengan tier tinggi | Keduanya berfungsi, tetapi kelayakan tier lebih penting dari yang dipikirkan orang |
Tabel ini bukan vonis. Ini adalah pertanyaan awal: baris mana yang paling dekat dengan tim saya, dan apa implikasinya terhadap arsitektur default saya?
FAQ

Kapan integrasi OpenAI langsung sudah cukup?
Ketika Anda sudah memilih OpenAI, volume penggunaan Anda tidak cukup besar untuk membenarkan negosiasi kontrak platform terpisah, dan Anda tidak memiliki kebutuhan eksplisit untuk fallback ke penyedia lain. Sebagian besar tim kecil dan menengah yang menjalankan beban kerja OpenAI produksi masuk dalam kategori ini.
Mengapa tim akan menambahkan platform model di atasnya?
Tiga alasan yang paling sering muncul: perutean multi-model tanpa perubahan kode, fallback selama pemadaman atau peluncuran parsial, dan penagihan terpadu di semua penyedia. Jika tidak ada yang berlaku untuk Anda sekarang, Anda mungkin tidak membutuhkannya sekarang.
Apakah platform membantu selama peluncuran parsial?
Ya — tetapi hanya untuk mode kegagalan “saya membutuhkan model frontier yang bekerja dan yang saya sukai belum tersedia.” Ini tidak membantu jika Anda secara khusus membutuhkan GPT-5.5 dan hanya GPT-5.5. Platform dapat merutekan ke model terbaik yang tersedia dari sebuah daftar. Platform tidak dapat menghadirkan akses ke model yang belum dikirimkan OpenAI.
Apa trade-off yang datang dengan lapisan tambahan?
Anda menambahkan vendor antara Anda dan model. Itu berarti halaman status lain, permukaan penagihan lain, titik kegagalan potensial lain, terkadang markup kecil, dan sesekali keterlambatan pada fitur khusus penyedia. Tidak ada yang merupakan penghambat mutlak. Ini adalah biaya nyata yang harus Anda perhitungkan.
Kesimpulan
Versi jujurnya adalah ini. OpenAI langsung adalah jawaban yang tepat untuk banyak tim — mungkin lebih dari yang diakui kalangan penganut platform. Platform model adalah jawaban yang tepat untuk banyak tim lain — mungkin lebih dari yang diakui kalangan pengguna OpenAI saja. Pembagiannya bukan ideologis. Ini tentang berapa banyak model yang benar-benar Anda gunakan, seberapa besar cerita uptime Anda bergantung pada LLM, dan seberapa besar biaya peralihan yang dapat Anda toleransi ketika model frontier berikutnya dikirimkan.
Peluncuran GPT-5.5 adalah uji stres yang berguna karena memiliki tiga momen dalam dua minggu: ChatGPT dulu, API sehari kemudian, varian Instant dua belas hari setelah itu. Setiap tim yang menggunakan model frontier akan menjalani versi pola tersebut berulang kali. Layak untuk memutuskan sekarang, pada hari yang tenang, arsitektur mana yang ingin Anda pegang lain kali.
Jalankan perhitungan terhadap pengaturan Anda sendiri. Itu akan memberi tahu Anda lebih banyak daripada postingan ini.
Postingan Sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
