Claude Opus 4.7: Mengapa Tim AI Membutuhkan Lapisan API Model yang Terpadu
Claude Opus 4.7 hampir hadir. Inilah mengapa peluncuran model yang sering mengungkap biaya nyata dari integrasi API langsung—dan apa yang dilakukan tim AI untuk mengatasinya.

Kesimpulan terlebih dahulu: bagian tersulit dari Claude Opus 4.7 bukan modelnya. Melainkan migrasinya.
Saya — Dora — menjalankan pipeline generasi AI untuk konten produksi. Gambar, video, orkestrasi multi-model. Ketika Anthropic merilis Opus 4.6 pada Februari, tim saya menghabiskan empat hari untuk memvalidasi ulang prompt, menyesuaikan anggaran token, dan memperbaiki satu ketidaksesuaian penagihan yang baru muncul pada hari ketiga. Sekarang, baru dua bulan kemudian, Anthropic telah merilis Opus 4.7 dengan tokenizer baru, perubahan API yang merusak, dan level effort baru. Jika Anda adalah orang di tim yang memelihara lapisan integrasi model, Anda sudah merasakan beban dari kalimat tersebut.
Artikel ini mendokumentasikan apa yang sudah dikonfirmasi tentang Opus 4.7 sejauh ini, apa yang sebenarnya dikorbankan oleh treadmill upgrade terhadap tim rekayasa, dan kapan perhitungannya mulai menguntungkan lapisan agregasi dibandingkan API provider langsung.

Apa yang Kita Ketahui Tentang Claude Opus 4.7 (Dan Apa yang Masih Belum Dikonfirmasi)
Informasi: dikonfirmasi vs. rumor
Opus 4.7 tersedia secara umum pada 16 April 2026. ID model adalah claude-opus-4-7. Harga tetap di $5 per juta token input dan $25 per juta token output — sama seperti Opus 4.6. Jendela konteks 1 juta token tidak berubah. Output maksimum tetap 128 ribu token.
Yang berubah: dukungan visi resolusi tinggi hingga 3,75 megapiksel (lebih dari tiga kali lipat batas 1,15 MP pada 4.6), level effort baru xhigh antara high dan max, dan anggaran tugas untuk agentic loop — fitur beta yang memberi model penghitung token di seluruh alur kerja multi-giliran.
Perubahan yang merusak lebih penting daripada fitur-fiturnya. Anggaran extended thinking dihapus. Parameter sampling hilang. Tokenizer baru memproses teks yang sama menjadi sekitar 1,0–1,35 kali lebih banyak token tergantung jenis konten. Harga per token tetap, tetapi tagihan aktual Anda bisa naik hingga 35% tanpa Anda mengubah satu prompt pun.
Apa yang berubah dari Opus 4.6 ke 4.7 — mengapa penting bagi para pembangun
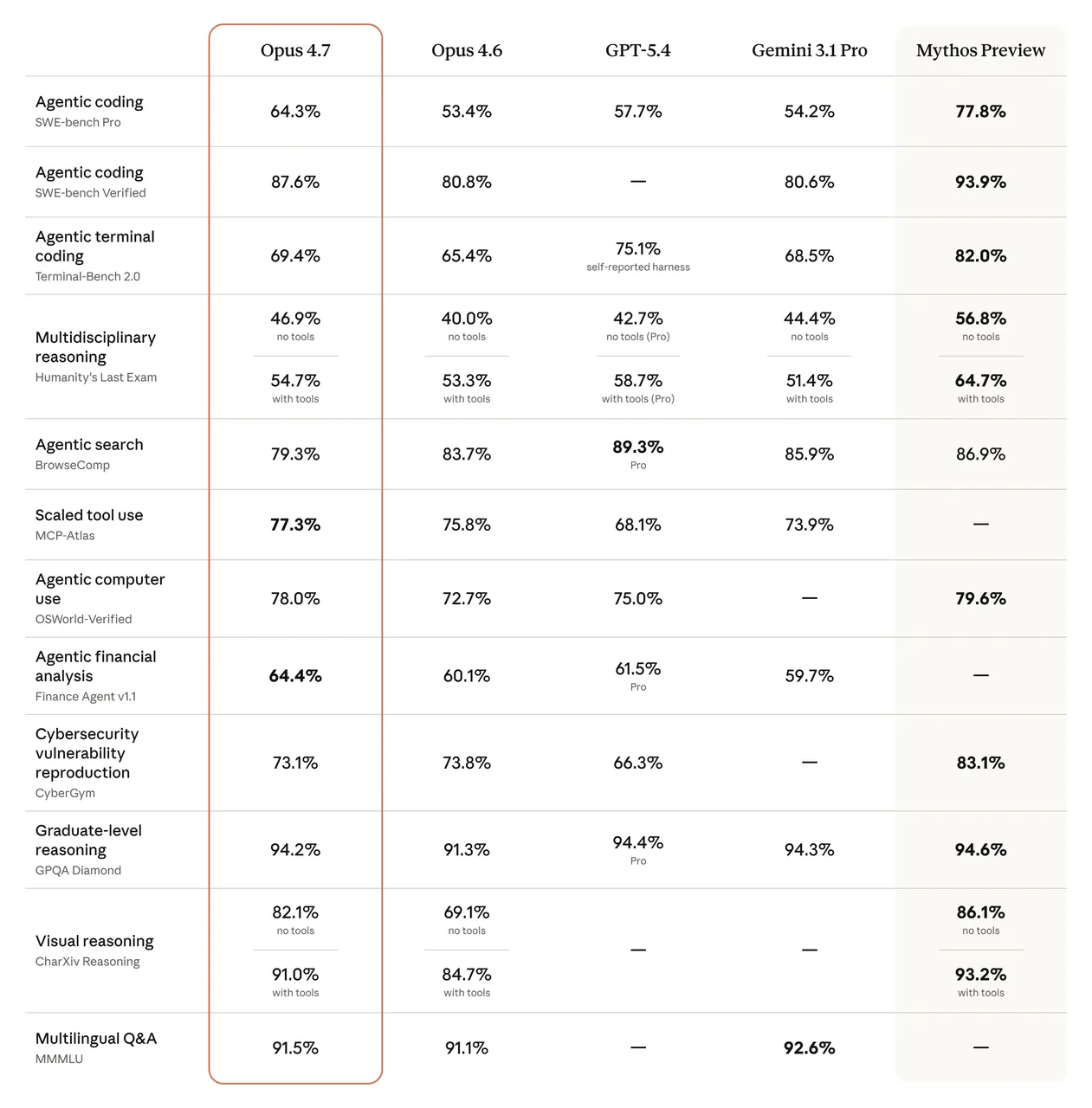
Angka benchmark-nya nyata. SWE-bench Verified naik dari 80,8% menjadi 87,6%. CursorBench melompat dari 58% menjadi 70%. Pada SWE-bench Pro, Opus 4.7 mendapat skor 64,3% — naik dari 53,4% pada 4.6 dan melampaui GPT-5.4 di 57,7%.
Namun inilah bagian yang benar-benar mempengaruhi tim produksi: Opus 4.7 mengikuti instruksi secara lebih harfiah. Prompt yang “longgar” atau bersifat percakapan dengan 4.6 mungkin menghasilkan hasil yang kaku atau tidak terduga. Jika Anda telah menghabiskan berminggu-minggu menyetel perpustakaan prompt, pergeseran perilaku tersebut berarti pengujian ulang — bukan hanya mengganti string model.
Masalah Sesungguhnya Bukan Model Baru — Melainkan Treadmill Upgrade
Apa yang dimaksud “model Claude baru setiap bulan” bagi tim rekayasa
Anthropic merilis Opus 4.5 pada November 2025. Opus 4.6 pada Februari 2026. Opus 4.7 pada April 2026. Itu tiga versi model utama dalam lima bulan. Masing-masing membawa perubahan parameter, pergeseran perilaku, atau pembaruan API yang merusak.
Biaya rekayasa dari setiap upgrade bukan pada penggantian model. Melainkan pada siklus validasi. Pengujian regresi prompt. Rekalibrasi anggaran token. Pembaruan proyeksi penagihan. Uji asap integrasi di staging dan produksi. Untuk alur kerja saya, setiap migrasi menghabiskan tiga hingga lima hari rekayasa — dan itu untuk tim yang sudah pernah melakukannya sebelumnya.
Risiko versioning: ketika prompt Anda rusak setelah pembaruan model
Panduan migrasi untuk Opus 4.7 transparan tentang hal ini. Tokenizer yang diperbarui berarti /v1/messages/count_tokens mengembalikan angka yang berbeda untuk input yang sama. Jika sistem Anda memiliki batas max_tokens yang dikodekan keras, batas tersebut mungkin kini memotong output sebelum waktunya. Jika Anda mengandalkan prefill atau parameter sampling, keduanya sudah hilang.
Saya pernah melihat tim memperlakukan upgrade model seperti pembaruan dependensi — ubah string versi, jalankan tes, rilis. Pendekatan itu berhenti berhasil sekitar Opus 4.5.
Siapa yang paling merasakan: tim API langsung vs. lapisan agregasi
Tim yang memanggil API Anthropic secara langsung menyerap setiap perubahan yang merusak sendiri. Tim di balik lapisan agregasi — middleware yang menormalkan API provider ke dalam satu antarmuka — menyerapnya sekali, secara terpusat. Perbedaannya berlipat ganda. Tiga upgrade provider per tahun di dua atau tiga provider berarti enam hingga sembilan kejadian migrasi. Lapisan agregasi mengubahnya menjadi pembaruan konfigurasi.
Ini bukan hipotesis. Saya memelihara integrasi dengan beberapa provider model. Yang dirutekan melalui lapisan terpadu butuh berjam-jam untuk diperbarui. Yang langsung butuh berhari-hari.
Bagaimana Tim Produk AI Menyusun Akses Model di 2026
API provider langsung: kapan masih masuk akal
API langsung unggul ketika Anda membutuhkan akses hari-nol ke fitur baru, ketika beban kerja Anda memanfaatkan kemampuan khusus provider (seperti anggaran tugas Opus 4.7), atau ketika Anda sudah cukup dalam pada satu provider sehingga biaya peralihan secara efektif nol karena Anda tidak beralih.
Jika seluruh produk Anda dibangun di atas Claude dan hanya Claude, dan Anda memiliki bandwidth rekayasa untuk menyerap perubahan yang merusak setiap kuartal, API langsung masih merupakan jalur yang lugas.
Lapisan agregasi: kapan perhitungan biaya peralihan berbalik
Titik infleksinya adalah penggunaan multi-model yang dikombinasikan dengan pembaruan provider yang sering. Begitu Anda memanggil Claude untuk penalaran, model berbeda untuk klasifikasi, dan model ketiga untuk embedding — dan setiap provider merilis perubahan yang merusak dengan jadwalnya sendiri — overhead koordinasi mulai memakan waktu rekayasa yang nyata.
Menurut perkiraan Gartner, sekitar 40% aplikasi enterprise akan menyematkan agen AI spesifik-tugas pada akhir 2026. Setiap agen mungkin memanggil model yang berbeda. Mengelola itu melalui API provider langsung tidak salah — hanya saja mahal dengan cara yang muncul sebagai jam-engineer, bukan pada faktur.
Daftar periksa evaluasi sebelum bermigrasi ke versi Claude baru apa pun
Sebelum mengganti claude-opus-4-6 dengan claude-opus-4-7 di produksi, ada daftar pendek yang saya lalui: pengujian dampak tokenizer (jalankan prompt aktual Anda melalui count_tokens pada kedua versi dan bandingkan), regresi perilaku prompt (perubahan instruksi harfiah akan muncul di sini), pembaruan proyeksi penagihan (peningkatan token 1,0–1,35 kali bergantung pada konten — ukur pada data Anda, bukan rata-rata Anthropic), dan audit ketergantungan fitur (periksa apakah Anda menggunakan sesuatu yang telah dihapus atau diubah).
Jika tim Anda tidak bisa melakukan ini dalam kurang dari sehari, itu adalah sinyal tentang arsitektur Anda, bukan tentang model.
Apa yang Perlu Dipantau Setelah Opus 4.7 Resmi Dirilis
Timeline ketersediaan API dan tingkatan akses
Opus 4.7 sudah live di API Claude, Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry. Paket Claude Pro, Max, Team, dan Enterprise semuanya memiliki akses. Batas rate digabungkan di seluruh versi Opus, sehingga Anda dapat menjalankan lalu lintas 4.6 dan 4.7 berdampingan selama migrasi.
Harga vs. 4.6 — dikonfirmasi vs. spekulatif
Kartu tarif identik. $5/$25 per juta token. Prompt caching masih menawarkan penghematan hingga 90%; pemrosesan batch masih memberikan diskon 50%. Namun perubahan tokenizer berarti biaya efektif per prompt lebih tinggi — seberapa tinggi bergantung pada campuran konten Anda. Kode padat? Ekspektasi mendekati 1,35 kali. Prompt percakapan singkat? Mendekati 1,0 kali.
Satu hal yang masih saya pantau: tokenizer baru Opus 4.7 dilaporkan menangani konten multibahasa secara berbeda. Untuk tim yang memproses teks non-Inggris dalam skala besar, inflasi token bisa bahkan lebih tinggi dari 35%. Saya belum memiliki cukup data tentang ini.
Sinyal kompatibilitas: jendela konteks, penggunaan alat, output terstruktur
Jendela konteks: 1 juta token, tidak berubah. Penggunaan alat: set yang sama seperti 4.6 — bash, eksekusi kode, penggunaan komputer, editor teks, pencarian web, konektor MCP. Output terstruktur: didukung. Kartu sistem Opus 4.7 mencatat bahwa model lebih teliti dalam memverifikasi output secara mandiri, yang berarti beberapa scaffolding prompt yang ada (“periksa ulang tata letak slide sebelum mengembalikan”) dapat dihapus.
Hubungan dengan Claude Mythos layak dicatat: Opus 4.7 secara eksplisit diposisikan sebagai testbed untuk perlindungan yang pada akhirnya ingin Anthropic terapkan pada model kelas Mythos. Opus 4.7 membawa deteksi penggunaan siber otomatis yang tidak dimiliki Mythos Preview dalam bentuk yang sama. Ini tidak langsung relevan dengan integrasi API — tetapi menandakan ke mana peta jalan model Anthropic menuju.
FAQ
Apakah Claude Opus 4.7 sudah tersedia melalui API?
Ya. Tersedia secara umum pada 16 April 2026. ID model adalah claude-opus-4-7. Tersedia di API langsung Anthropic, Amazon Bedrock, Google Vertex AI, dan Microsoft Foundry.
Bagaimana harga Opus 4.7 dibandingkan dengan Opus 4.6?
Kartu tarif identik: $5 per juta token input, $25 per juta token output. Namun tokenizer yang diperbarui dapat menggelembungkan jumlah token aktual hingga 35%, artinya prompt yang sama mungkin lebih mahal untuk dijalankan di 4.7 daripada di 4.6.
Bisakah saya menjalankan Claude Opus 4.7 melalui API inferensi pihak ketiga?
Ya. Beberapa platform agregasi dan lapisan routing mendukung Opus 4.7. Pertanyaan kuncinya adalah apakah lapisan pihak ketiga mengekspos fitur spesifik 4.7 seperti anggaran tugas dan level effort xhigh, atau hanya meneruskan completion standar.
Apa perbedaan antara Claude Opus 4.7 dan Claude Mythos?
Mythos Preview adalah model Anthropic yang paling powerful, dibatasi untuk mitra terpilih di bawah Project Glasswing untuk pekerjaan keamanan siber defensif. Opus 4.7 tersedia secara umum dan membawa perlindungan otomatis yang sedang diuji Anthropic sebelum akhirnya memperluas akses kelas Mythos. Keduanya adalah tingkatan kemampuan berbeda dengan model akses berbeda.
Haruskah tim saya menunggu Opus 4.7 atau tetap di 4.6 untuk produksi?
Jika prompt Anda sudah teruji pada 4.6 dan sistem Anda berjalan dengan baik, jangan terburu-buru. Uji coba 4.7 pada sebagian kecil lalu lintas, ukur dampak tokenizer dan perubahan perilaku prompt, lalu migrasi secara bertahap. Modelnya lebih baik — tetapi migrasinya tidak tanpa usaha.
Saya masih menjalankan 4.6 dan 4.7 secara paralel di pipeline saya sendiri. Keuntungan benchmark-nya nyata, begitu pula penyetelan ulang prompt. Saya akan memiliki lebih banyak data dalam satu atau dua minggu tentang apakah overhead tokenizer sebanding dengan keuntungan efisiensi dari lebih sedikit pemanggilan alat. Bagian itu belum terpecahkan.
Postingan sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer