GPT-5.5 directement via OpenAI ou via une plateforme ?
Les équipes devraient-elles accéder à GPT-5.5 directement depuis OpenAI ou via une plateforme de modèles ? Comparez la vitesse de déploiement, les options de repli, le routage et le contrôle opérationnel.

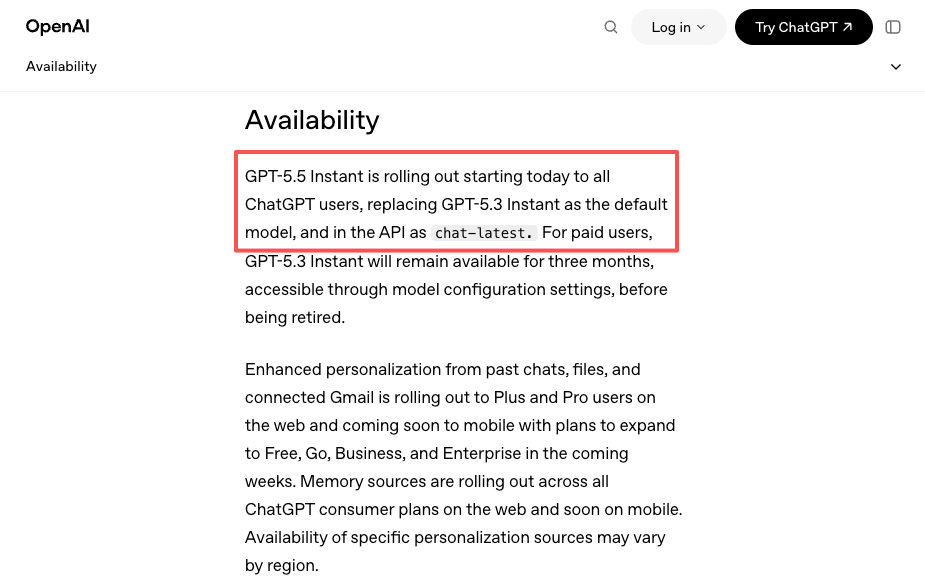
GPT-5.5 a été lancé dans ChatGPT et Codex le 23 avril. L’API est arrivée un jour plus tard, le 24 avril. Puis le 5 mai, GPT-5.5 Instant est devenu le modèle ChatGPT par défaut et a été déployé dans l’API sous le nom chat-latest. Trois moments de déploiement distincts en deux semaines, chacun avec des conditions d’éligibilité différentes et des surfaces différentes.
Je m’appelle Dora. J’ai suivi cela parce que j’y étais obligée. L’un de mes workflows touche aux modèles GPT-5, et l’écart de 24 heures entre la sortie ChatGPT et la sortie API n’était pas théorique pour moi. Cela signifiait soit attendre, soit router vers quelque chose qui avait déjà accès. Cette décision — attendre ou router — est la même décision que chaque équipe utilisant un modèle frontier doit désormais prendre à chaque nouvelle version. Cet article y est donc consacré.
La question n’est pas “est-ce qu’OpenAI est bien”. Elle est : quand GPT-5.5 (ou ce qui vient ensuite) arrive par étapes, appelez-vous OpenAI directement, ou vous placez-vous derrière une plateforme qui gère le déploiement pour vous ? Les deux réponses sont correctes pour des équipes différentes. Voici ce que j’observe quand j’examine la question honnêtement.
Les Deux Façons d’Accéder à GPT-5.5
Accès direct au fournisseur
Vous appelez api.openai.com avec une clé OpenAI. Un seul SDK, un seul ensemble de docs, une seule facture. Quand OpenAI publie un nouveau nom de modèle, vous changez une chaîne dans votre configuration et vous l’utilisez — en supposant que votre niveau d’accès vous y donne droit dès le premier jour.
Les tarifs sont disponibles sur la page de tarification officielle d’OpenAI : GPT-5.5 à 5 $/M tokens en entrée et 30 $/M tokens en sortie, GPT-5.5 Pro à 30 $/M tokens en entrée et 180 $/M tokens en sortie. Environ le double de GPT-5.4. Vous payez OpenAI directement.
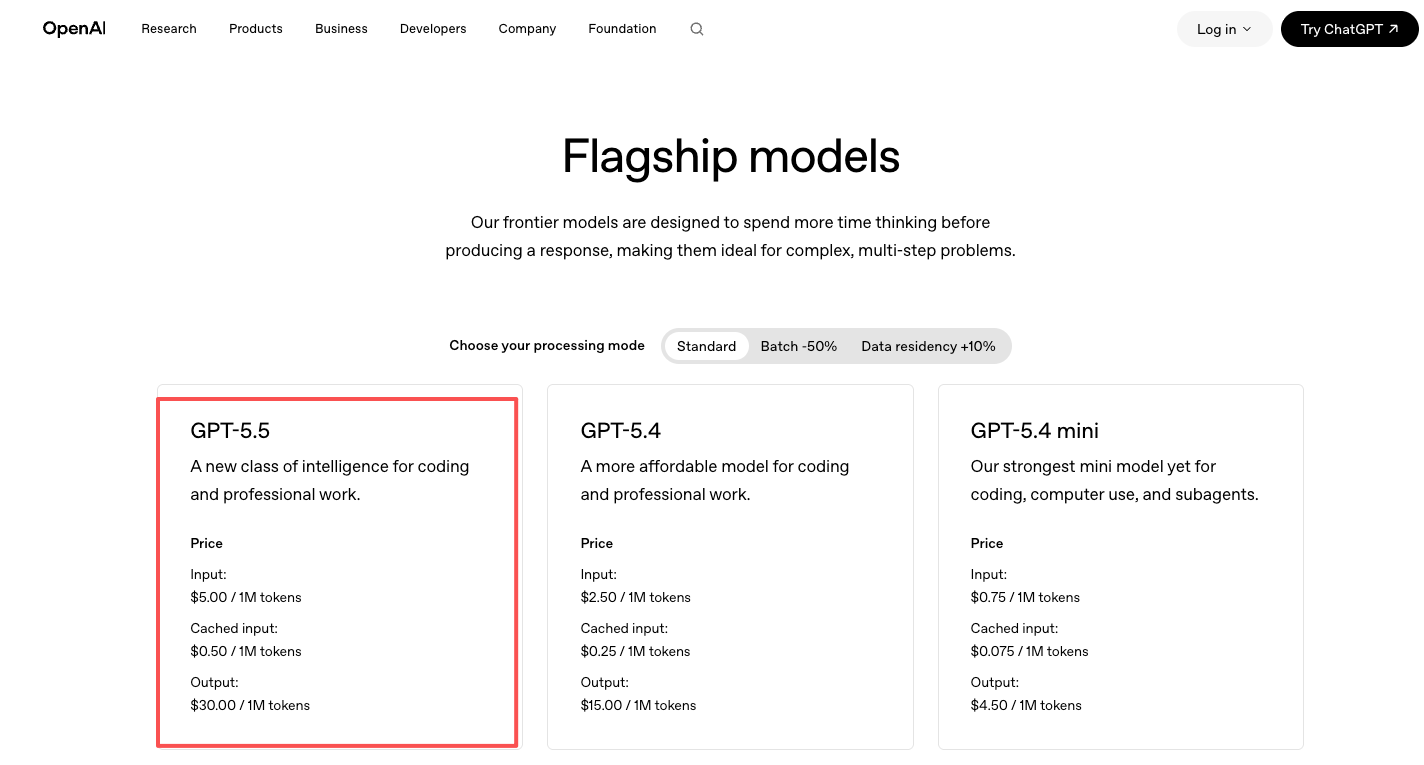
Accès via une plateforme de modèles
Vous appelez une couche de routage — OpenRouter, LiteLLM, une passerelle interne, ou une plateforme multi-modèles — et cette couche parle à OpenAI en votre nom. Même forme de SDK OpenAI (la plupart des plateformes sont compatibles OpenAI), mais la chaîne de modèle peut pointer vers GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, ou une chaîne de fallback sur les trois.
Vous payez la plateforme. La plateforme paie OpenAI. Il y a une légère majoration, parfois aucune. En échange, vous obtenez une seule facture pour tous les fournisseurs, la possibilité de changer de modèle sans modifier le code, et un chemin de secours quand quelque chose tombe en panne.
C’est l’ensemble du tableau. Aucune option n’est “meilleure”. Elles optimisent pour des choses différentes.
Là où l’Accès Direct l’Emporte
Simplicité, moins d’abstraction, et optimisation spécifique au fournisseur
Si vous n’utilisez que des modèles OpenAI, appeler OpenAI directement est l’architecture la plus simple possible. Un seul fournisseur. Un seul ensemble de codes d’erreur. Une seule page de statut à surveiller. Quand quelque chose tombe en panne, vous savez à qui vous adresser.
Il importe aussi qu’OpenAI publie des fonctionnalités qui ne sont pas toujours immédiatement disponibles via les couches d’abstraction. Responses API. Contrôles d’effort de raisonnement. Sorties structurées avec des schémas stricts. La surface d’outils Codex. Les formats d’appel d’outils spécifiques au fournisseur. Une couche de plateforme finit par rattraper son retard, mais “finalement” peut signifier des semaines. Si votre produit dépend d’une fonctionnalité OpenAI spécifique dès le premier jour, la voie directe est la seule voie.
Il y a aussi un coût réel à l’indirection dont personne ne parle. Chaque couche entre votre code et le modèle est un endroit de plus où quelque chose peut mal tourner, une page de statut d’équipe supplémentaire à surveiller, une surprise de facturation de plus en fin de mois. Pour une petite équipe exploitant un seul modèle en production, cette surcharge peut outrepasser les avantages.
Quand un seul modèle suffit
Beaucoup d’équipes n’ont réellement besoin que d’un seul modèle. Elles ont choisi GPT-5 il y a un an, le workflow fonctionne, les prompts sont réglés, les évaluations sont stables. Elles ne veulent pas faire des A/B tests contre Claude. Elles ne veulent pas basculer sur Gemini. Elles veulent que le modèle continue de fonctionner et que la facture reste prévisible.
Pour cette équipe, une couche de routage résout un problème qu’elle n’a pas. L’accès direct est la bonne réponse et ajouter une plateforme par-dessus est la mauvaise. Ne payez pas une taxe de complexité pour une optionalité que vous n’utiliserez pas.
Là où une Plateforme de Modèles l’Emporte
Vitesse de déploiement, fallback et contrôle du routage
C’est là que le calendrier de GPT-5.5 a vraiment eu de l’importance. Entre le 23 et le 24 avril, GPT-5.5 était actif dans ChatGPT mais pas dans l’API. CNBC a rapporté à l’époque qu’OpenAI avait signalé “des garanties différentes” pour le déploiement de l’API, sans date d’engagement. Pour la plupart des équipes, cet écart de 24 heures n’était rien. Pour quelques-unes — celles ayant un contrat stipulant “nous déployons le dernier modèle dans un délai X” — c’était un problème.
Une couche de plateforme ne rend pas OpenAI plus rapide. Mais elle change l’apparence de “l’attente”. Pendant que GPT-5.5 n’était pas encore dans l’API OpenAI, Claude Opus 4.7 l’était. Gemini 3.1 Pro l’était. Une configuration routée peut préférer GPT-5.5 dès qu’il arrive, se rabattre sur le modèle frontier actuellement disponible, et ne nécessite pas de déploiement de code quand la situation change.
La même logique s’applique aux pannes. OpenAI a connu des incidents d’API de plusieurs heures cette année. Tout comme tous les autres fournisseurs. Si votre produit exige strictement “un LLM qui fonctionne maintenant”, vous construisez soit le fallback vous-même, soit vous laissez une plateforme s’en charger. Tant la documentation de fallback d’OpenRouter que la documentation du routeur LiteLLM décrivent cela concrètement : déclarez un modèle principal, listez les fallbacks, obtenez une réponse fonctionnelle quand le principal échoue.
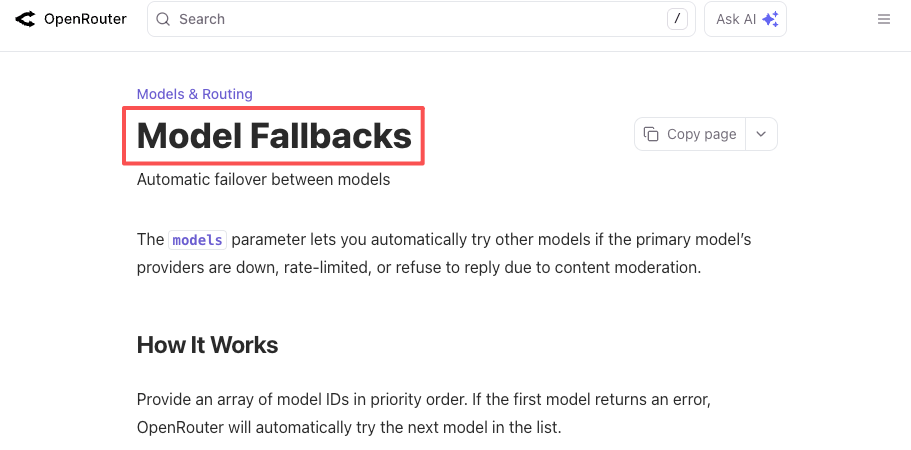
Ce n’est pas un scénario hypothétique. C’est un scénario que j’ai vécu deux fois ce trimestre.
Expérimentation multi-modèles et résilience des approvisionnements
L’autre endroit où une plateforme justifie son existence, c’est quand vous ne savez pas encore quel modèle convient le mieux à la tâche — ou quand vous suspectez que la réponse changera dans six mois.
Le leadership des modèles frontier tourne sur un cycle d’environ 3 à 6 mois. GPT-5.5 arrive, puis Anthropic publie, puis Google publie, et la réponse à “le meilleur modèle pour le code” ou “le meilleur modèle pour l’analyse longue durée” continue de bouger. Si vous vous êtes intégré au SDK d’un seul fournisseur, changer représente un vrai travail d’ingénierie. Si vous êtes derrière une couche de routage, changer signifie modifier une chaîne de modèle.
La même logique s’applique à l’approvisionnement. Une plateforme consolide les dépenses chez plusieurs fournisseurs en une seule facture, un seul ensemble d’analyses d’utilisation, un seul contrôle budgétaire. Les équipes financières s’en préoccupent davantage que les équipes d’ingénierie ne le réalisent. “Nous avons un seul fournisseur d’IA” est plus facile à gérer que “nous avons trois fournisseurs d’IA et les dépenses par fournisseur changent chaque mois.”
Et puis il y a un signal plus subtil : la sortie le 5 mai de GPT-5.5 Instant comme nouveau défaut ChatGPT — couverte dans l’annonce officielle d’OpenAI — a été déployée en tant que chat-latest dans l’API. Les équipes épinglées à cet alias ont obtenu la mise à niveau automatiquement. Celles épinglées à une date de version spécifique ne l’ont pas eue. Une plateforme peut vous offrir une abstraction unifiée sur ces deux comportements pour tous les fournisseurs, plutôt que de vous obliger à suivre les règles de versionnage de chaque fournisseur séparément.
Un Cadre de Décision par Type d’Équipe
Je n’aime pas les tableaux de frameworks dans les articles de blog parce qu’ils simplifient à l’excès. Mais une heuristique approximative est utile ici :
| Profil d’équipe | Probablement le meilleur choix | Raison |
|---|---|---|
| Développeur solo, un modèle, un produit | OpenAI direct | La couche de routage ajoute du coût sans résoudre un vrai problème |
| Équipe de production, stack OpenAI uniquement, dépend de fonctionnalités spécifiques au fournisseur | OpenAI direct | Accès dès le premier jour à Responses API, sorties structurées, etc. |
| Équipe de production, multi-modèles dans les évaluations, prévoit de rester multi-modèles | Plateforme | Le coût de changement est la variable dominante |
| Équipe avec un SLA de disponibilité strict sur une fonctionnalité basée sur LLM | Plateforme | Les chaînes de fallback sont l’assurance la moins chère |
| Équipe gérant des outils internes, pas orientés client | L’un ou l’autre | Choisissez celui avec moins de surcharge opérationnelle pour vous |
| Entreprise avec approvisionnement, révision de sécurité par fournisseur | Plateforme | Un contrat vaut mieux que N contrats |
| Équipe de recherche / expérimentation comparant des modèles frontier | Plateforme | La commutation de modèles est le workflow entier |
| Équipe qui dépend d’un accès dès le premier jour aux nouvelles versions de modèles | Plateforme avec couverture dès le premier jour, ou fournisseur direct avec niveau élevé | Les deux fonctionnent, mais l’éligibilité au niveau importe plus que les gens ne le pensent |
Le tableau n’est pas un verdict. C’est une question de départ : quelle ligne est la plus proche de mon équipe, et qu’est-ce que cela implique pour mon architecture par défaut ?
FAQ

Quand l’intégration OpenAI directe est-elle suffisante ?
Quand vous avez déjà choisi OpenAI, que votre volume d’utilisation ne justifie pas la négociation d’un contrat de plateforme séparé, et que vous n’avez pas un besoin explicite de fallback vers un autre fournisseur. La plupart des petites et moyennes équipes exécutant des charges de travail OpenAI en production entrent dans cette catégorie.
Pourquoi les équipes ajouteraient-elles une plateforme de modèles par-dessus ?
Les trois raisons qui reviennent le plus souvent : routage multi-modèles sans changements de code, fallback lors de pannes ou de déploiements partiels, et facturation consolidée entre fournisseurs. Si aucune de ces raisons ne s’applique à vous en ce moment, vous n’en avez probablement pas besoin en ce moment.
Une plateforme aide-t-elle lors de lancements partiels ?
Oui — mais uniquement pour le mode de défaillance “j’ai besoin d’un modèle frontier fonctionnel et celui que je préfère n’est pas encore disponible.” Cela n’aide pas si vous avez spécifiquement besoin de GPT-5.5 et uniquement GPT-5.5. Une plateforme peut router vers le meilleur modèle disponible dans une liste. Elle ne peut pas conjurer l’accès à un modèle qu’OpenAI n’a pas encore déployé.
Quels compromis une couche supplémentaire implique-t-elle ?
Vous ajoutez un fournisseur entre vous et le modèle. Cela signifie une autre page de statut, une autre surface de facturation, un autre point de défaillance potentiel, parfois une légère majoration, et occasionnellement un délai sur les fonctionnalités spécifiques au fournisseur. Aucun de ces éléments n’est rédhibitoire. Ce sont des coûts réels que vous devez prendre en compte.
Conclusion
La version honnête est la suivante. OpenAI direct est la bonne réponse pour beaucoup d’équipes — probablement plus que le camp des évangélistes de plateformes ne l’admet. Une plateforme de modèles est la bonne réponse pour beaucoup d’autres équipes — probablement plus que le camp OpenAI-exclusif ne l’admet. La division n’est pas idéologique. Elle porte sur le nombre de modèles que vous utilisez réellement, sur la dépendance de votre histoire de disponibilité au LLM, et sur le coût de changement que vous pouvez supporter quand le prochain modèle frontier sera disponible.
Le déploiement de GPT-5.5 a été un test de résistance utile parce qu’il a comporté trois moments en deux semaines : ChatGPT en premier, l’API un jour plus tard, la variante Instant douze jours après. Chaque équipe utilisant un modèle frontier vivra des versions de ce schéma à répétition. Cela vaut la peine de décider maintenant, un jour calme, quelle architecture vous voulez avoir en main la prochaine fois.
Faites le calcul avec votre propre configuration. Cela vous en dira plus que cet article.
Articles précédents :
- Disponibilité de l’API GPT-5.5 : Ce que les Développeurs Doivent Savoir
- GPT-5.5 vs GPT-5.4 : Les Équipes Devraient-elles Migrer ?
- GPT-5.5 pour les Développeurs : Premiers Enseignements en Production
- Claude Opus 4.7 et l’Essor des Couches d’API de Modèles Unifiées
- Comment Configurer g0dm0d3 sur OpenRouter (2026)
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
