Claude Opus 4.7 : Pourquoi les équipes IA ont besoin d'une couche API de modèle unifiée
Claude Opus 4.7 est presque là. Voici pourquoi les déploiements fréquents de modèles révèlent le vrai coût des intégrations API directes — et ce que font les équipes IA pour y remédier.

La conclusion d’abord : la partie la plus difficile de Claude Opus 4.7, ce n’est pas le modèle. C’est la migration.
Je m’appelle Dora — je gère des pipelines de génération par IA pour du contenu en production. Images, vidéo, orchestration multi-modèles. Quand Anthropic a lancé Opus 4.6 en février, mon équipe a passé quatre jours à revalider les prompts, ajuster les budgets de tokens, et corriger une anomalie de facturation qui n’est apparue qu’au troisième jour. Maintenant, à peine deux mois plus tard, Anthropic a publié Opus 4.7 avec un nouveau tokeniseur, des changements d’API incompatibles, et un nouveau niveau d’effort. Si vous êtes la personne dans votre équipe qui maintient la couche d’intégration du modèle, vous ressentez déjà le poids de cette phrase.
Cet article documente ce qui est confirmé sur Opus 4.7 jusqu’à présent, ce que le tapis roulant des mises à niveau coûte réellement aux équipes d’ingénierie, et à partir de quand le calcul favorise une couche d’agrégation plutôt que des API de fournisseur direct.

Ce que nous savons de Claude Opus 4.7 (et ce qui reste non confirmé)
L’information : confirmée vs. rumeurs
Opus 4.7 est disponible en disponibilité générale depuis le 16 avril 2026. L’identifiant du modèle est claude-opus-4-7. Le tarif reste à 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie — identique à Opus 4.6. La fenêtre de contexte d’1M de tokens est inchangée. La sortie maximale reste à 128k tokens.
Ce qui a changé : la prise en charge de la vision haute résolution jusqu’à 3,75 mégapixels (plus du triple de la limite de 1,15 MP sur la version 4.6), un nouveau niveau d’effort xhigh entre high et max, et des budgets de tâches pour les boucles agentiques — une fonctionnalité bêta qui donne au modèle un compte à rebours de tokens sur l’ensemble d’un flux de travail multi-tours.
Les changements incompatibles comptent plus que les fonctionnalités. Les budgets de pensée étendue sont supprimés. Les paramètres d’échantillonnage ont disparu. Le nouveau tokeniseur traite le même texte en environ 1,0 à 1,35x plus de tokens selon le type de contenu. Le prix par token est fixe, mais votre facture réelle peut augmenter jusqu’à 35 % sans que vous modifiiez un seul prompt.
Ce qui a changé d’Opus 4.6 à 4.7 — pourquoi c’est important pour les développeurs
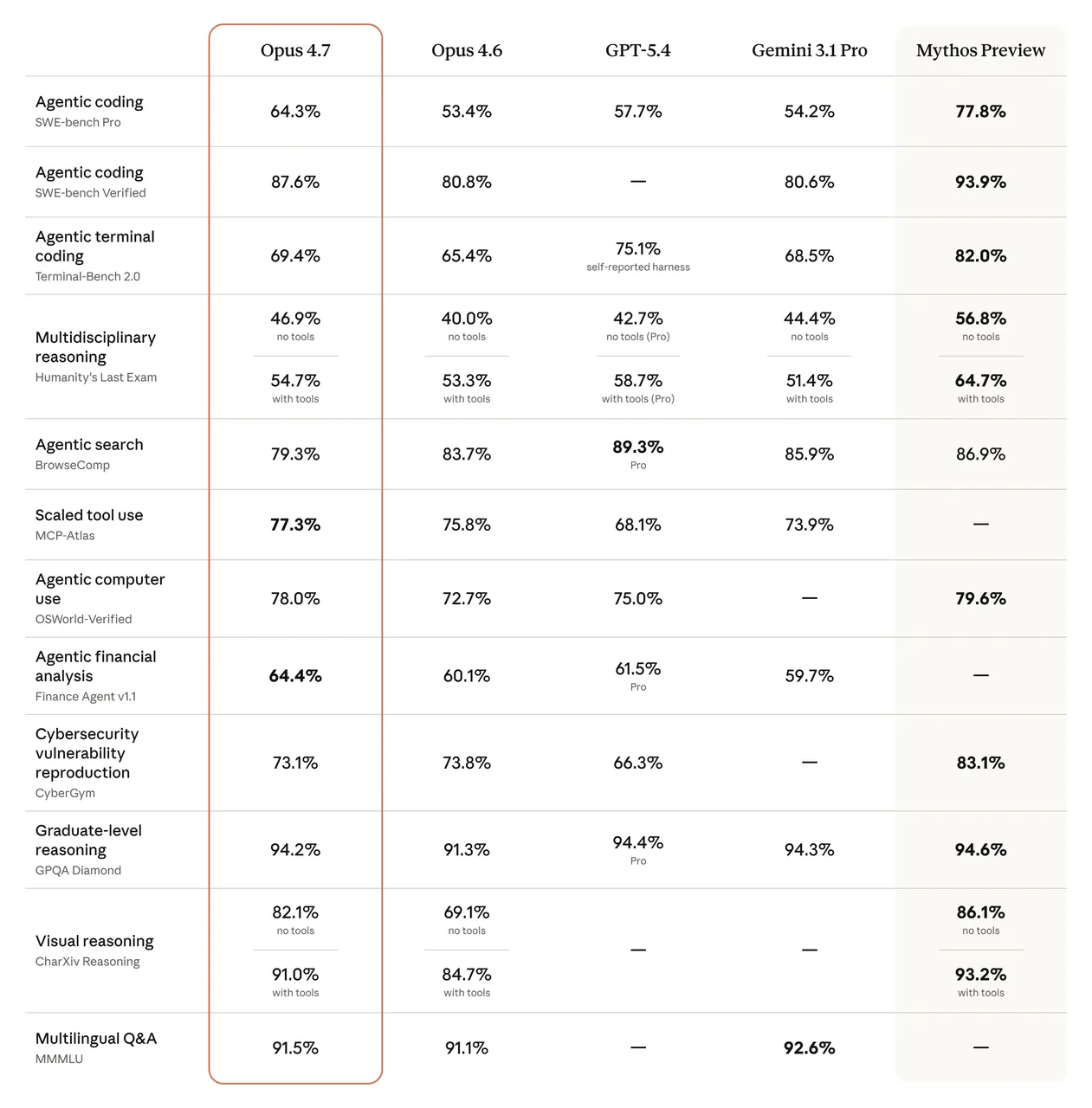
Les chiffres de référence sont réels. SWE-bench Verified est passé de 80,8 % à 87,6 %. CursorBench a bondi de 58 % à 70 %. Sur SWE-bench Pro, Opus 4.7 obtient 64,3 % — en hausse par rapport à 53,4 % sur la version 4.6 et devant GPT-5.4 à 57,7 %.
Mais voici la partie qui affecte réellement les équipes en production : Opus 4.7 suit les instructions plus littéralement. Les prompts qui étaient « souples » ou conversationnels avec la version 4.6 peuvent produire des résultats rigides ou inattendus. Si vous avez passé des semaines à affiner des bibliothèques de prompts, ce changement de comportement implique de tout re-tester — pas seulement de remplacer une chaîne de modèle.
Le vrai problème n’est pas le nouveau modèle — c’est le tapis roulant des mises à niveau
Ce que « un nouveau Claude chaque mois » coûte réellement à une équipe d’ingénierie
Anthropic a livré Opus 4.5 en novembre 2025. Opus 4.6 en février 2026. Opus 4.7 en avril 2026. C’est trois versions majeures du modèle en cinq mois. Chacune a apporté des changements de paramètres, des évolutions comportementales ou des mises à jour d’API incompatibles.
Le coût d’ingénierie de chaque mise à niveau n’est pas le remplacement du modèle. C’est la boucle de validation. Tests de régression des prompts. Recalibrage des budgets de tokens. Mise à jour des projections de facturation. Tests de fumée d’intégration entre staging et production. Pour mes flux de travail, chaque migration consomme trois à cinq jours-ingénieurs — et c’est pour une équipe qui l’a déjà fait.
Risque de versionnage : quand vos prompts cessent de fonctionner après une mise à jour du modèle
Le guide de migration pour Opus 4.7 est transparent à ce sujet. Le tokeniseur mis à jour signifie que /v1/messages/count_tokens retourne des chiffres différents pour la même entrée. Si votre système a des limites max_tokens codées en dur, elles peuvent désormais tronquer la sortie prématurément. Si vous vous appuyiez sur le pré-remplissage ou les paramètres d’échantillonnage, ceux-ci ont disparu.
J’ai vu des équipes traiter les mises à niveau de modèles comme des mises à jour de dépendances — changer la chaîne de version, lancer les tests, déployer. Cette approche a cessé de fonctionner autour d’Opus 4.5.
Qui subit le plus de douleur : API directe vs. équipes avec couche d’agrégation
Les équipes qui appellent l’API d’Anthropic directement absorbent elles-mêmes chaque changement incompatible. Les équipes derrière une couche d’agrégation — un middleware qui normalise les API des fournisseurs en une interface unique — l’absorbent une fois, de manière centralisée. La différence se cumule. Trois mises à niveau de fournisseurs par an pour deux ou trois fournisseurs représentent six à neuf événements de migration. Les couches d’agrégation transforment cela en une mise à jour de configuration.
Ce n’est pas hypothétique. Je maintiens des intégrations avec plusieurs fournisseurs de modèles. Celles acheminées via une couche unifiée ont pris des heures à mettre à jour. Les directes ont pris des jours.
Comment les équipes de produits IA structurent l’accès aux modèles en 2026
API de fournisseur direct : quand ça a encore du sens
L’API directe l’emporte quand vous avez besoin d’un accès immédiat aux nouvelles fonctionnalités, quand votre charge de travail exploite des capacités spécifiques au fournisseur (comme les budgets de tâches d’Opus 4.7), ou quand vous êtes suffisamment ancré chez un fournisseur que le coût de changement est effectivement nul car vous ne changez pas.
Si l’ensemble de votre produit est construit sur Claude et uniquement Claude, et que vous avez la bande passante d’ingénierie pour absorber les changements incompatibles trimestriels, l’API directe reste le chemin le plus simple.
Couche d’agrégation : quand le calcul du coût de changement s’inverse
Le point d’inflexion est l’utilisation multi-modèles combinée à des mises à jour fréquentes de fournisseurs. Une fois que vous appelez Claude pour le raisonnement, un modèle différent pour la classification, et un troisième pour les embeddings — et que chaque fournisseur livre des changements incompatibles selon son propre calendrier — la surcharge de coordination commence à consommer du temps d’ingénierie réel.
Selon les prévisions de Gartner, environ 40 % des applications d’entreprise intégreront des agents IA spécifiques à des tâches d’ici fin 2026. Chaque agent peut appeler un modèle différent. Gérer cela via des API de fournisseurs directs n’est pas faux — c’est juste coûteux d’une façon qui se manifeste en heures-ingénieurs, pas sur une facture.
La liste de vérification avant de migrer vers n’importe quelle nouvelle version de Claude
Avant de remplacer claude-opus-4-6 par claude-opus-4-7 en production, il y a une courte liste que j’applique : test d’impact du tokeniseur (faites passer vos prompts réels par count_tokens sur les deux versions et comparez), régression du comportement des prompts (le changement d’instruction littérale apparaîtra ici), mise à jour de la projection de facturation (l’augmentation de 1,0 à 1,35x des tokens dépend du contenu — mesurez-la sur vos données, pas sur les moyennes d’Anthropic), et audit des dépendances aux fonctionnalités (vérifiez si vous utilisez quelque chose qui a été supprimé ou modifié).
Si votre équipe ne peut pas faire cela en moins d’une journée, c’est un signal sur votre architecture, pas sur le modèle.
Quoi surveiller après le lancement officiel d’Opus 4.7
Calendrier de disponibilité de l’API et niveaux d’accès
Opus 4.7 est déjà disponible sur l’API de Claude, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry. Les plans Claude Pro, Max, Team et Enterprise ont tous accès. Les limites de débit sont mutualisées entre les versions d’Opus, vous pouvez donc exécuter le trafic 4.6 et 4.7 en parallèle pendant la migration.
Tarification vs. 4.6 — confirmée vs. spéculative
La grille tarifaire est identique. 5 $/25 $ par million de tokens. La mise en cache des prompts offre toujours jusqu’à 90 % d’économies ; le traitement par lots donne toujours 50 % de réduction. Mais le changement de tokeniseur signifie que le coût effectif par prompt est plus élevé — de combien dépend de votre mix de contenu. Du code dense ? Attendez-vous à environ 1,35x. Des prompts conversationnels courts ? Plus proche de 1,0x.
Une chose que je surveille encore : le nouveau tokeniseur d’Opus 4.7 traite apparemment le contenu multilingue différemment. Pour les équipes qui traitent du texte non anglais à grande échelle, l’inflation des tokens pourrait être encore supérieure à 35 %. Je n’ai pas encore assez de données à ce sujet.
Signaux de compatibilité : fenêtre de contexte, utilisation d’outils, sortie structurée
Fenêtre de contexte : 1M de tokens, inchangée. Utilisation d’outils : même ensemble que la version 4.6 — bash, exécution de code, utilisation de l’ordinateur, éditeur de texte, recherche web, connecteur MCP. Sortie structurée : prise en charge. La fiche système d’Opus 4.7 note que le modèle est plus minutieux dans l’auto-vérification des sorties, ce qui signifie que certains échafaudages de prompts existants (« vérifiez la mise en page de la diapositive avant de retourner ») peuvent être supprimés.
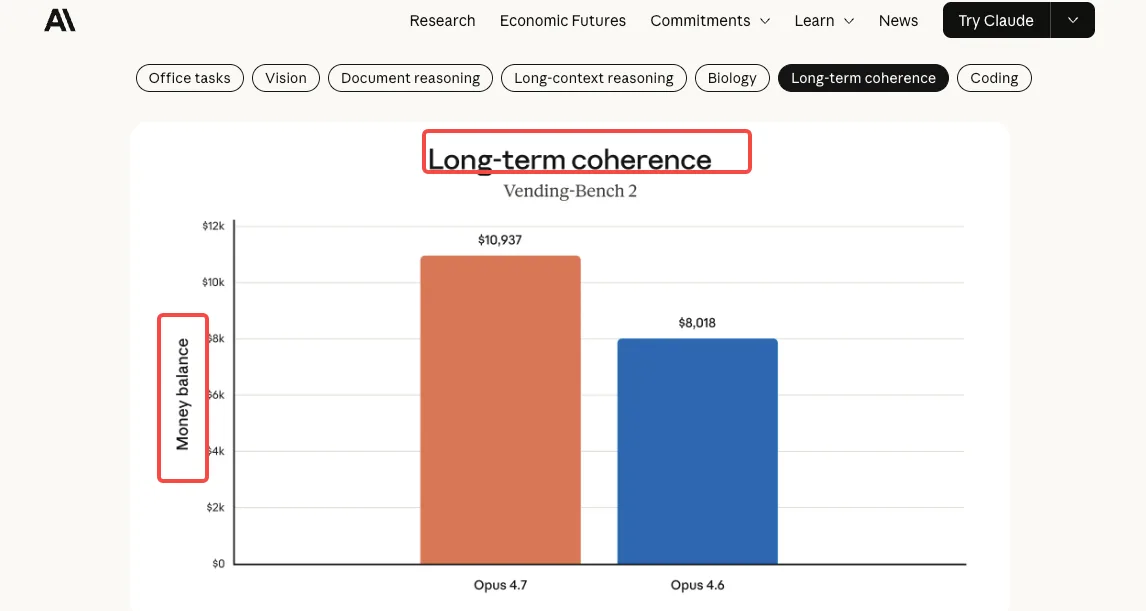
La relation à Claude Mythos mérite d’être notée : Opus 4.7 est explicitement positionné comme le banc d’essai pour les garde-fous qu’Anthropic souhaite éventuellement déployer sur les modèles de classe Mythos. Opus 4.7 dispose d’une détection automatisée de l’utilisation informatique que Mythos Preview n’a pas sous la même forme. Ce n’est pas directement pertinent pour l’intégration API — mais cela indique la direction de la feuille de route des modèles d’Anthropic.
FAQ
Claude Opus 4.7 est-il déjà disponible via l’API ?
Oui. Il est disponible en disponibilité générale depuis le 16 avril 2026. L’identifiant du modèle est claude-opus-4-7. Disponible sur l’API directe d’Anthropic, Amazon Bedrock, Google Vertex AI et Microsoft Foundry.
Comment le tarif d’Opus 4.7 se compare-t-il à celui d’Opus 4.6 ?
La grille tarifaire est identique : 5 $ par million de tokens en entrée, 25 $ par million de tokens en sortie. Mais le tokeniseur mis à jour peut gonfler le nombre réel de tokens jusqu’à 35 %, ce qui signifie que le même prompt peut coûter plus cher à exécuter sur la version 4.7 que sur la version 4.6.
Puis-je exécuter Claude Opus 4.7 via une API d’inférence tierce ?
Oui. Plusieurs plateformes d’agrégation et couches de routage prennent en charge Opus 4.7. La question clé est de savoir si la couche tierce expose les fonctionnalités spécifiques à la version 4.7 comme les budgets de tâches et le niveau d’effort xhigh, ou ne transmet que les complétions standard.
Quelle est la différence entre Claude Opus 4.7 et Claude Mythos ?
Mythos Preview est le modèle le plus puissant d’Anthropic, réservé à des partenaires sélectionnés dans le cadre du Projet Glasswing pour les travaux de cybersécurité défensive. Opus 4.7 est disponible en disponibilité générale et intègre des garde-fous automatisés qu’Anthropic teste avant d’élargir éventuellement l’accès de classe Mythos. Ce sont des niveaux de capacité différents avec des modèles d’accès différents.
Mon équipe devrait-elle attendre Opus 4.7 ou rester sur la version 4.6 pour la production ?
Si vos prompts sont éprouvés sur la version 4.6 et que votre système fonctionne bien, ne vous précipitez pas. Pilotez la version 4.7 sur une petite tranche de trafic, mesurez l’impact du tokeniseur et les changements de comportement des prompts, puis migrez par étapes. Le modèle est meilleur — mais la migration n’est pas sans effort.
Je fais encore tourner les versions 4.6 et 4.7 en parallèle sur mes propres pipelines. Les gains de référence sont réels, mais le ré-ajustement des prompts l’est aussi. J’aurai plus de données dans une semaine ou deux pour savoir si la surcharge du tokeniseur est compensée par les gains d’efficacité liés à moins d’appels d’outils. Ce point n’est pas encore résolu.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir