¿OpenAI directamente o una plataforma para GPT-5.5?
¿Deberían los equipos acceder a GPT-5.5 directamente desde OpenAI o a través de una plataforma de modelos? Compara la velocidad de despliegue, el respaldo, el enrutamiento y el control operativo.

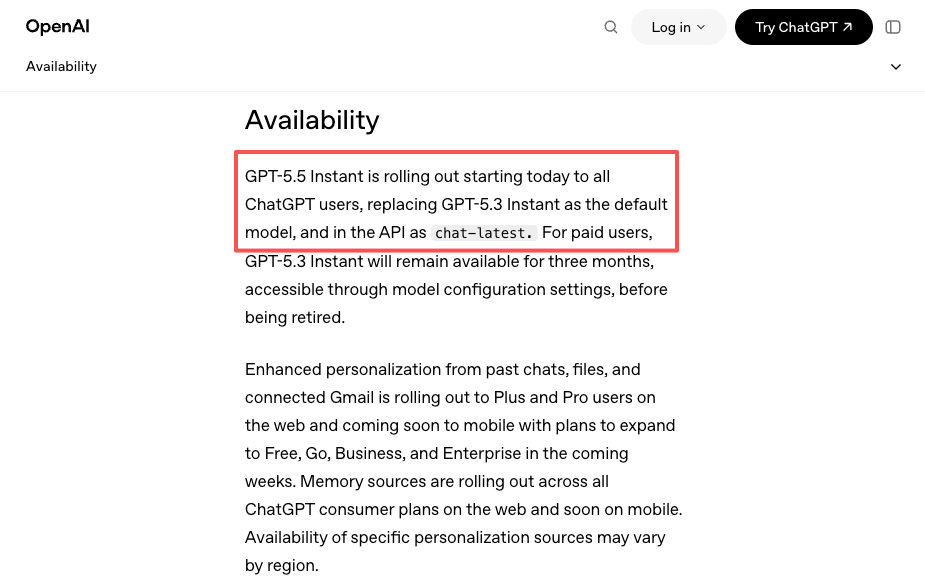
GPT-5.5 se lanzó en ChatGPT y Codex el 23 de abril. La API llegó un día después, el 24 de abril. Luego, el 5 de mayo, GPT-5.5 Instant se convirtió en el modelo predeterminado de ChatGPT y se distribuyó a la API como chat-latest. Tres momentos de lanzamiento diferentes en dos semanas, cada uno con distintos requisitos de nivel de acceso y diferentes superficies.
Soy Dora. Lo seguí de cerca porque tenía que hacerlo. Uno de mis flujos de trabajo utiliza modelos GPT-5, y la brecha de 24 horas en la API entre el lanzamiento de ChatGPT y el de la API no fue teórica para mí. Significaba esperar o enrutar a través de algo que ya tenía acceso. Esa decisión — esperar o enrutar — es la misma que cada equipo que usa un modelo de frontera tiene que tomar en cada lanzamiento. Por eso este artículo trata sobre eso.
La pregunta no es “¿es bueno OpenAI?”. Es: cuando GPT-5.5 (o lo que venga después) se distribuye en etapas, ¿llamas a OpenAI directamente o te colocas detrás de una plataforma que gestione el escalonamiento por ti? Ambas respuestas son correctas para equipos diferentes. A continuación está lo que veo cuando lo analizo con honestidad.
Las Dos Formas en que los Equipos Accederán a GPT-5.5
Acceso directo al proveedor
Llamas a api.openai.com con una clave de OpenAI. Un SDK, un conjunto de documentación, una factura. Cuando OpenAI lanza un nuevo nombre de modelo, cambias una cadena en tu configuración y ya lo estás usando — suponiendo que tu nivel tenga acceso desde el primer día.
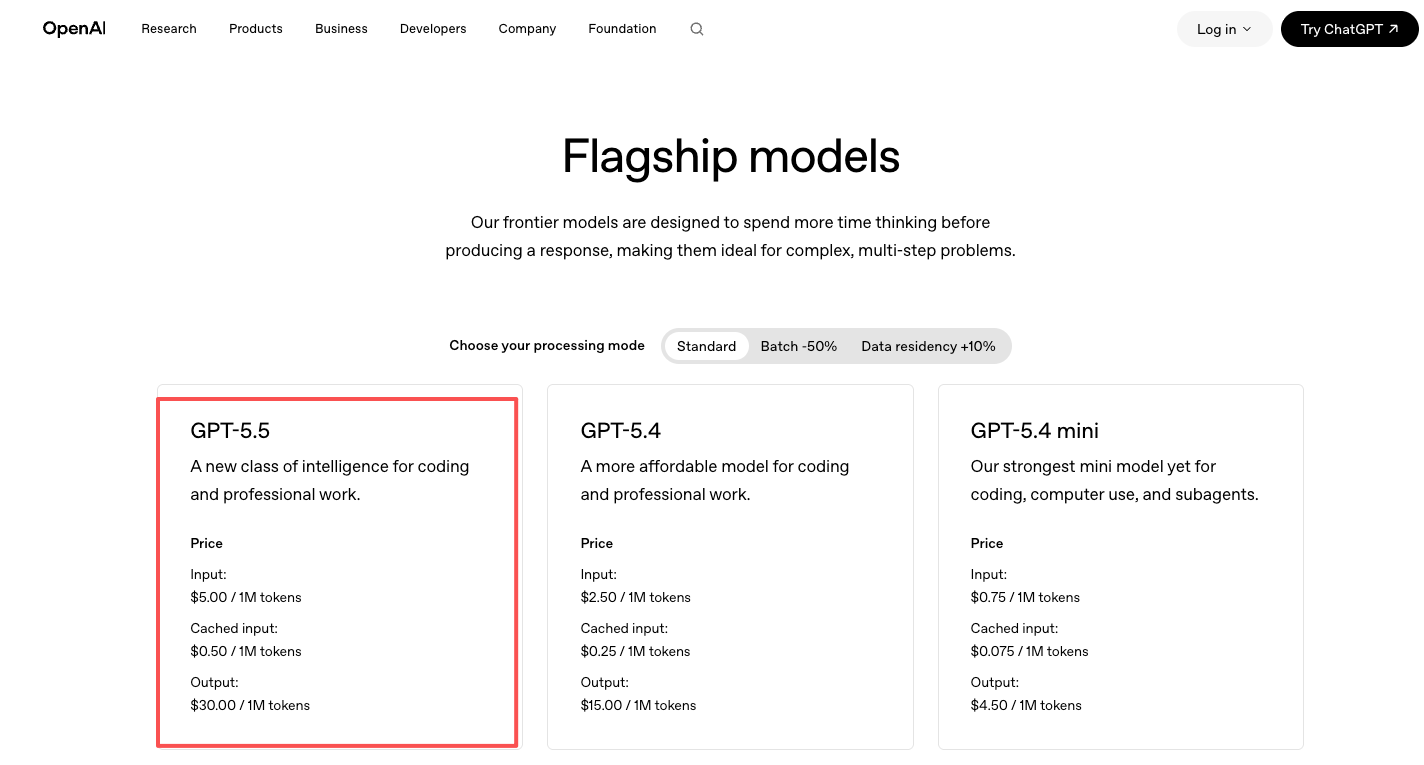
Los precios están en la página oficial de precios de OpenAI: GPT-5.5 a $5/M de tokens de entrada y $30/M de salida, GPT-5.5 Pro a $30/M de entrada y $180/M de salida. Aproximadamente el doble que GPT-5.4. Pagas directamente a OpenAI.
Acceso a través de una plataforma de modelos
Llamas a una capa de enrutamiento — OpenRouter, LiteLLM, una pasarela interna o una plataforma multimodelo — y esa capa habla con OpenAI en tu nombre. Mismo formato de SDK de OpenAI (la mayoría de las plataformas son compatibles con OpenAI), pero la cadena del modelo puede apuntar a GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro o una cadena de respaldo entre los tres.
Pagas a la plataforma. La plataforma paga a OpenAI. Hay un pequeño recargo, a veces ninguno. A cambio, obtienes una sola factura entre proveedores, cambio de modelo sin modificaciones de código y una ruta de respaldo cuando algo falla.
Ese es el panorama completo. Ninguno es “mejor”. Optimizan para cosas diferentes.
Dónde Gana el Acceso Directo
Simplicidad, menor abstracción y optimización específica del proveedor
Si solo usas modelos de OpenAI, llamar a OpenAI directamente es la arquitectura más simple posible. Un proveedor. Un conjunto de códigos de error. Una página de estado que monitorear. Cuando algo falla, sabes a quién preguntar.
También importa que OpenAI lanza funciones que no siempre están disponibles de inmediato a través de capas de abstracción. API de Responses. Controles de esfuerzo de razonamiento. Salidas estructuradas con esquemas estrictos. La superficie de la herramienta Codex. Formatos de llamada de herramientas específicos del proveedor. Una capa de plataforma eventualmente se pone al día, pero “eventualmente” puede significar semanas. Si tu producto depende de una función específica de OpenAI desde el primer día, el camino directo es el único camino.
También hay un costo real en la indirección del que nadie habla. Cada capa entre tu código y el modelo es un lugar más donde algo puede salir mal, una página de estado más de otro equipo para monitorear, una sorpresa de facturación más al final del mes. Para un equipo pequeño que ejecuta un modelo en producción, esa sobrecarga puede superar el beneficio.
Cuando un modelo es suficiente
Muchos equipos genuinamente solo necesitan un modelo. Eligieron GPT-5 hace un año, el flujo de trabajo funciona, los prompts están ajustados, las evaluaciones son estables. No quieren hacer pruebas A/B con Claude. No quieren hacer respaldo a Gemini. Quieren que el modelo siga funcionando y que la factura siga siendo predecible.
Para ese equipo, una capa de enrutamiento está resolviendo un problema que no tienen. El acceso directo es la respuesta correcta y agregar una plataforma encima es la incorrecta. No pagues el costo de complejidad por una opcionalidad que no vas a usar.
Dónde Gana una Plataforma de Modelos
Velocidad de lanzamiento, respaldo y control de enrutamiento
Aquí es donde la cronología de GPT-5.5 realmente importó. Entre el 23 y el 24 de abril, GPT-5.5 estaba activo en ChatGPT pero no en la API. CNBC informó en ese momento que OpenAI señaló “diferentes salvaguardas” para el lanzamiento de la API, sin una fecha comprometida. Para la mayoría de los equipos esa brecha de 24 horas no fue nada. Para algunos — cualquiera con un contrato de “lanzamos el modelo más reciente dentro de X horas” — fue un problema.
Una capa de plataforma no hace que OpenAI sea más rápido. Pero cambia lo que significa “esperar”. Mientras GPT-5.5 aún no estaba en la API de OpenAI, Claude Opus 4.7 sí lo estaba. Gemini 3.1 Pro también. Una configuración enrutada puede preferir GPT-5.5 una vez que llegue, hacer respaldo al modelo de frontera que esté disponible actualmente y no requerir un despliegue de código cuando la situación cambie.
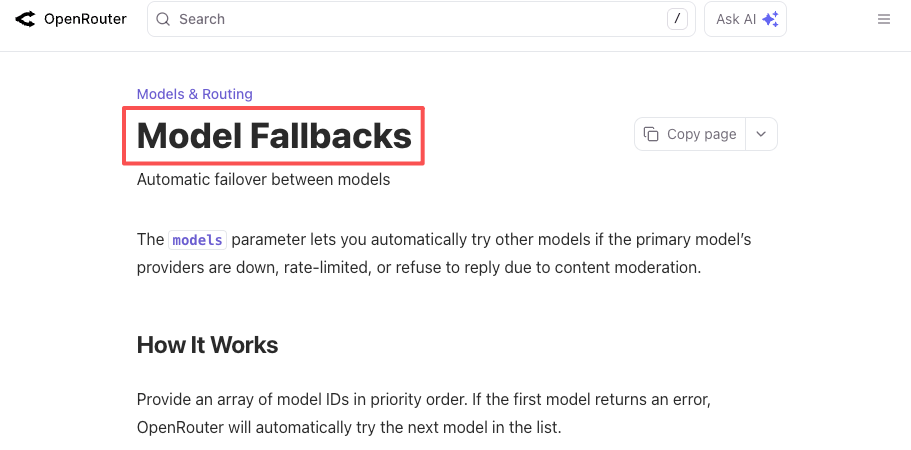
La misma lógica se aplica a las interrupciones. OpenAI ha tenido incidentes de API de varias horas este año. También todos los demás proveedores. Si tu producto requiere estrictamente “un LLM que funcione ahora mismo”, o construyes el respaldo tú mismo o dejas que una plataforma lo maneje. Tanto la documentación de respaldo de OpenRouter como la documentación del enrutador de LiteLLM describen esto en configuración concreta: declara un modelo primario, lista los respaldos, obtén una respuesta funcional cuando falla el primario.
Este no es un escenario hipotético. Es un escenario que he experimentado dos veces este trimestre.
Experimentación multimodelo y resiliencia de adquisición
El otro lugar donde una plataforma justifica su valor es cuando aún no sabes qué modelo es el adecuado para el trabajo — o cuando sospechas que esa respuesta cambiará en seis meses.
El liderazgo de los modelos de frontera está rotando en ciclos de aproximadamente 3 a 6 meses. GPT-5.5 se lanza, luego Anthropic lanza, luego Google lanza, y la respuesta de “mejor modelo para código” o “mejor modelo para análisis de contexto largo” sigue moviéndose. Si te has integrado con el SDK de un solo proveedor, cambiar significa trabajo de ingeniería real. Si estás detrás de una capa de enrutamiento, cambiar significa cambiar una cadena de modelo.
La misma lógica se aplica a la adquisición. Una plataforma consolida el gasto entre proveedores en una sola factura, un conjunto de análisis de uso, un control de presupuesto. Los equipos de finanzas se preocupan por esto más de lo que los equipos de ingeniería se dan cuenta. “Tenemos un proveedor de IA” es más fácil de gestionar que “tenemos tres proveedores de IA y el gasto por proveedor cambia mensualmente.”
Y luego hay una señal más sutil: el lanzamiento del 5 de mayo de GPT-5.5 Instant como el nuevo predeterminado de ChatGPT — cubierto en el propio anuncio de OpenAI — se distribuyó como chat-latest en la API. Los equipos vinculados a ese alias recibieron la actualización automáticamente. Los vinculados a una fecha de versión específica no. Una plataforma puede darte una abstracción unificada sobre ambos comportamientos entre proveedores, en lugar de que tú rastrees las reglas de versiones de cada proveedor por separado.
Un Marco de Decisión por Tipo de Equipo
No me gustan las tablas de marcos en los artículos de blog porque simplifican demasiado. Pero una heurística aproximada ayuda aquí:
| Perfil del equipo | Mejor opción probable | Razón |
|---|---|---|
| Desarrollador individual, un modelo, un producto | OpenAI directo | La capa de enrutamiento agrega costo sin resolver un problema real |
| Equipo de producción, solo OpenAI, depende de características específicas del proveedor | OpenAI directo | Acceso desde el primer día a la API de Responses, salidas estructuradas, etc. |
| Equipo de producción, multimodelo en evaluaciones, planea seguir siendo multimodelo | Plataforma | El costo de cambio es la variable dominante |
| Equipo con SLA de tiempo activo estricto en una función respaldada por LLM | Plataforma | Las cadenas de respaldo son el seguro más barato |
| Equipo que ejecuta herramientas internas, no orientadas al cliente | Cualquiera | Elige el que tenga menos sobrecarga operativa para ti |
| Empresa con adquisición, revisión de seguridad por proveedor | Plataforma | Un contrato es mejor que N contratos |
| Equipo de investigación / experimentación comparando modelos de frontera | Plataforma | El cambio de modelo es todo el flujo de trabajo |
| Equipo que depende del acceso desde el primer día a versiones de modelos completamente nuevas | Plataforma con cobertura desde el día cero, o proveedor directo con nivel alto | Ambos funcionan, pero la elegibilidad de nivel importa más de lo que la gente piensa |
La tabla no es un veredicto. Es una pregunta inicial: ¿qué fila se acerca más a mi equipo y qué implica eso sobre mi arquitectura predeterminada?
Preguntas Frecuentes

¿Cuándo es suficiente la integración directa con OpenAI?
Cuando ya has elegido OpenAI, tu volumen de uso no es lo suficientemente grande como para justificar negociar un contrato de plataforma separado y no tienes una necesidad explícita de respaldo a otro proveedor. La mayoría de los equipos pequeños y medianos que ejecutan cargas de trabajo de OpenAI en producción caen aquí.
¿Por qué los equipos agregarían una plataforma de modelos encima?
Las tres razones que aparecen con más frecuencia: enrutamiento multimodelo sin cambios de código, respaldo durante interrupciones o lanzamientos parciales y facturación consolidada entre proveedores. Si ninguna de esas se aplica a ti ahora mismo, probablemente no la necesites ahora mismo.
¿Ayuda una plataforma durante lanzamientos parciales?
Sí — pero solo para el modo de fallo de “necesito un modelo de frontera que funcione y el que prefiero aún no está disponible”. No ayuda si específicamente necesitas GPT-5.5 y solo GPT-5.5. Una plataforma puede enrutar al mejor modelo disponible de una lista. No puede invocar acceso a un modelo que OpenAI aún no ha lanzado.
¿Qué compensaciones vienen con otra capa?
Agregas un proveedor entre tú y el modelo. Eso significa otra página de estado, otra superficie de facturación, otro punto potencial de fallo, a veces un pequeño recargo y ocasionalmente un retraso en las características específicas del proveedor. Ninguno de estos es un factor decisivo. Son costos reales que debes considerar.
Conclusión
La versión honesta es esta. OpenAI directo es la respuesta correcta para muchos equipos — probablemente más de lo que la multitud de evangelistas de plataformas admite. Una plataforma de modelos es la respuesta correcta para muchos otros equipos — probablemente más de lo que la multitud de solo-OpenAI admite. La división no es ideológica. Se trata de cuántos modelos realmente usas, cuánto depende tu historia de tiempo activo del LLM y cuánto costo de cambio puedes tolerar cuando llegue el próximo modelo de frontera.
El lanzamiento de GPT-5.5 fue una prueba de estrés útil porque tuvo tres momentos en dos semanas: ChatGPT primero, la API un día después, la variante Instant doce días después. Cada equipo que usa un modelo de frontera va a vivir versiones de ese patrón repetidamente. Vale la pena decidir ahora, en un día tranquilo, qué arquitectura quieres tener la próxima vez.
Haz los cálculos con tu propia configuración. Eso te dirá más que este artículo.
Artículos anteriores:
- Disponibilidad de la API de GPT-5.5: Lo que los desarrolladores necesitan saber
- GPT-5.5 vs GPT-5.4: ¿Deberían los equipos actualizar ya?
- GPT-5.5 para desarrolladores: Lecciones tempranas de producción
- Claude Opus 4.7 y el auge de las capas de API de modelos unificados
- Cómo configurar g0dm0d3 en OpenRouter (2026)
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
