Claude Opus 4.7: Por qué los equipos de IA necesitan una capa de API de modelo unificada
Claude Opus 4.7 está casi aquí. Aquí te explicamos por qué los lanzamientos frecuentes de modelos exponen el costo real de las integraciones directas de API, y qué están haciendo al respecto los equipos de IA.

La conclusión primero: la parte más difícil de Claude Opus 4.7 no es el modelo. Es la migración.
Yo — Dora — gestiono pipelines de generación de IA para contenido en producción. Imágenes, video, orquestación de múltiples modelos. Cuando Anthropic lanzó Opus 4.6 en febrero, mi equipo pasó cuatro días revalidando prompts, ajustando presupuestos de tokens y corrigiendo una discrepancia de facturación que no apareció hasta el tercer día. Ahora, apenas dos meses después, Anthropic ha lanzado Opus 4.7 con un nuevo tokenizador, cambios de API incompatibles y un nuevo nivel de esfuerzo. Si eres la persona en tu equipo que mantiene la capa de integración del modelo, ya sientes el peso de esa frase.
Este artículo documenta lo que está confirmado sobre Opus 4.7 hasta ahora, lo que realmente cuesta el ciclo de actualizaciones a los equipos de ingeniería, y cuándo la matemática empieza a favorecer una capa de agregación sobre las APIs directas del proveedor.

Lo que sabemos sobre Claude Opus 4.7 (y lo que aún no está confirmado)
La información: confirmada vs. rumoreada
Opus 4.7 quedó disponible de forma general el 16 de abril de 2026. El ID del modelo es claude-opus-4-7. El precio se mantiene en $5 por millón de tokens de entrada y $25 por millón de tokens de salida — igual que Opus 4.6. La ventana de contexto de 1M de tokens no ha cambiado. La salida máxima sigue siendo 128k tokens.
Lo que sí cambió: soporte de visión de alta resolución hasta 3,75 megapíxeles (más del triple del límite de 1,15 MP en 4.6), un nuevo nivel de esfuerzo xhigh entre alto y máximo, y presupuestos de tareas para bucles agénticos — una función beta que le da al modelo una cuenta regresiva de tokens a lo largo de todo un flujo de trabajo multiturno.
Los cambios incompatibles importan más que las funciones. Los presupuestos de pensamiento extendido han sido eliminados. Los parámetros de muestreo han desaparecido. El nuevo tokenizador procesa el mismo texto generando aproximadamente 1,0–1,35x más tokens según el tipo de contenido. El precio por token es fijo, pero tu factura real puede aumentar hasta un 35% sin que cambies ni un solo prompt.
Qué cambió de Opus 4.6 a 4.7 — por qué importa para los desarrolladores
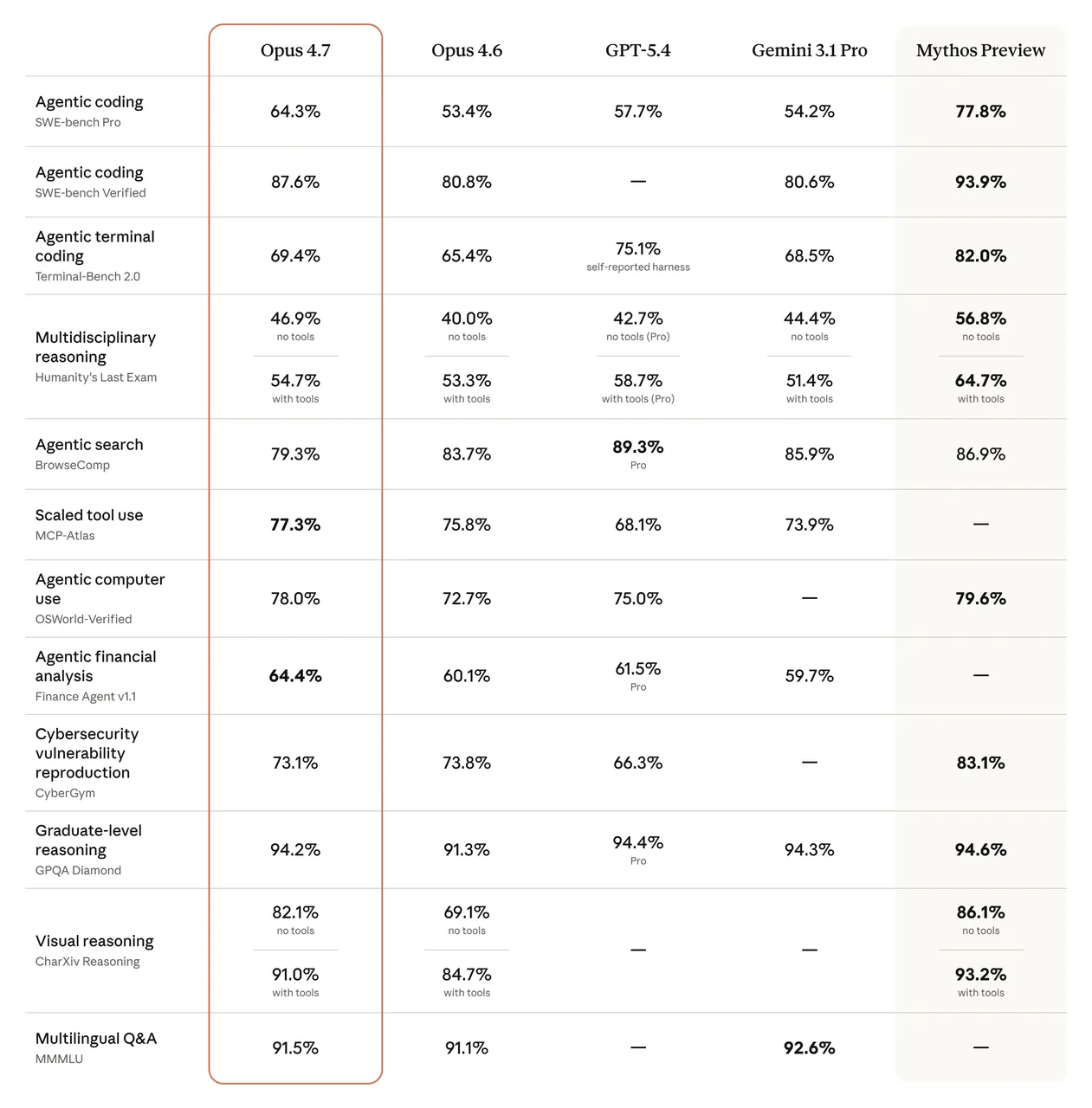
Los números de benchmark son reales. SWE-bench Verified pasó del 80,8% al 87,6%. CursorBench saltó del 58% al 70%. En SWE-bench Pro, Opus 4.7 obtiene un 64,3% — frente al 53,4% de 4.6 y por delante de GPT-5.4 con un 57,7%.
Pero aquí está la parte que realmente afecta a los equipos en producción: Opus 4.7 sigue las instrucciones de forma más literal. Los prompts que eran “sueltos” o conversacionales con 4.6 pueden producir resultados rígidos o inesperados. Si has pasado semanas afinando bibliotecas de prompts, ese cambio de comportamiento implica volver a testear — no solo cambiar una cadena del modelo.
El verdadero problema no es el nuevo modelo — es el ciclo de actualizaciones
Lo que “un nuevo Claude cada mes” realmente le cuesta a un equipo de ingeniería
Anthropic lanzó Opus 4.5 en noviembre de 2025. Opus 4.6 en febrero de 2026. Opus 4.7 en abril de 2026. Eso son tres versiones principales del modelo en cinco meses. Cada una trajo cambios de parámetros, cambios de comportamiento o actualizaciones de API incompatibles.
El costo de ingeniería de cada actualización no es el cambio de modelo. Es el bucle de validación. Pruebas de regresión de prompts. Recalibración del presupuesto de tokens. Actualizaciones de proyecciones de facturación. Pruebas de integración en staging y producción. En mis flujos de trabajo, cada migración consume entre tres y cinco días de ingeniería — y eso es para un equipo que ya lo ha hecho antes.
Riesgo de versiones: cuando tus prompts se rompen tras una actualización del modelo
La guía de migración para Opus 4.7 es transparente al respecto. El tokenizador actualizado hace que /v1/messages/count_tokens devuelva números diferentes para la misma entrada. Si tu sistema tiene límites max_tokens codificados de forma fija, ahora pueden recortar la salida prematuramente. Si dependías del prefill o de los parámetros de muestreo, esos han desaparecido.
He visto equipos tratar las actualizaciones de modelos como actualizaciones de dependencias — cambiar la cadena de versión, ejecutar las pruebas, publicar. Ese enfoque dejó de funcionar alrededor de Opus 4.5.
Quién sufre más: equipos con API directa vs. capa de agregación
Los equipos que llaman directamente a la API de Anthropic absorben cada cambio incompatible por su cuenta. Los equipos que trabajan detrás de una capa de agregación — un middleware que normaliza las APIs del proveedor en una única interfaz — lo absorben una vez, de forma centralizada. La diferencia se acumula. Tres actualizaciones del proveedor al año en dos o tres proveedores significa entre seis y nueve eventos de migración. Las capas de agregación convierten eso en una actualización de configuración.
Esto no es hipotético. Mantengo integraciones con múltiples proveedores de modelos. Las que están enrutadas a través de una capa unificada tardaron horas en actualizarse. Las directas tardaron días.
Cómo los equipos de productos de IA estructuran el acceso a modelos en 2026
API directa del proveedor: cuándo sigue teniendo sentido
La API directa gana cuando necesitas acceso en el día cero a nuevas funciones, cuando tu carga de trabajo aprovecha capacidades específicas del proveedor (como los presupuestos de tareas de Opus 4.7), o cuando estás tan integrado con un proveedor que el costo de cambio es efectivamente cero porque no estás cambiando.
Si todo tu producto está construido sobre Claude y solo Claude, y tienes el ancho de banda de ingeniería para absorber cambios incompatibles trimestrales, la API directa sigue siendo el camino más directo.
Capa de agregación: cuándo se invierte la matemática del costo de cambio
El punto de inflexión es el uso de múltiples modelos combinado con actualizaciones frecuentes del proveedor. Una vez que estás llamando a Claude para razonamiento, a un modelo diferente para clasificación, y a un tercero para embeddings — y cada proveedor publica cambios incompatibles en su propio calendario — la sobrecarga de coordinación empieza a consumir tiempo de ingeniería real.
Según la previsión de Gartner, aproximadamente el 40% de las aplicaciones empresariales incorporarán agentes de IA específicos para tareas a finales de 2026. Cada agente puede llamar a un modelo diferente. Gestionar eso a través de APIs directas del proveedor no es incorrecto — simplemente es costoso de una manera que se refleja en horas de ingeniería, no en una factura.
La lista de verificación de evaluación antes de migrar a cualquier nueva versión de Claude
Antes de cambiar claude-opus-4-6 por claude-opus-4-7 en producción, hay una lista corta que reviso: pruebas de impacto del tokenizador (ejecuta tus prompts reales a través de count_tokens en ambas versiones y compara), regresión del comportamiento de prompts (el cambio de instrucción literal se manifestará aquí), actualización de la proyección de facturación (el aumento de tokens de 1,0–1,35x depende del contenido — mídelo con tus datos, no con los promedios de Anthropic), y auditoría de dependencias de funciones (verifica si estás usando algo que ha sido eliminado o cambiado).
Si tu equipo no puede hacer esto en menos de un día, eso es una señal sobre tu arquitectura, no sobre el modelo.
Qué observar tras el lanzamiento oficial de Opus 4.7
Cronograma de disponibilidad de la API y niveles de acceso
Opus 4.7 ya está disponible en la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry. Los planes Claude Pro, Max, Team y Enterprise tienen acceso. Los límites de velocidad están agrupados entre las versiones de Opus, por lo que puedes ejecutar tráfico de 4.6 y 4.7 en paralelo durante la migración.
Precios vs. 4.6 — confirmados vs. especulativos
La tarifa es idéntica. $5/$25 por millón de tokens. El almacenamiento en caché de prompts sigue ofreciendo hasta un 90% de ahorro; el procesamiento por lotes sigue dando un 50% de descuento. Pero el cambio de tokenizador significa que el costo efectivo por prompt es mayor — cuánto más depende de tu mezcla de contenido. ¿Código denso? Espera algo cercano a 1,35x. ¿Prompts conversacionales cortos? Más cerca de 1,0x.
Una cosa que sigo observando: el nuevo tokenizador de Opus 4.7 supuestamente maneja el contenido multilingüe de forma diferente. Para los equipos que procesan texto en idiomas distintos al inglés a escala, la inflación de tokens podría ser incluso mayor al 35%. Aún no tengo suficientes datos sobre esto.
Señales de compatibilidad: ventana de contexto, uso de herramientas, salida estructurada
Ventana de contexto: 1M tokens, sin cambios. Uso de herramientas: el mismo conjunto que 4.6 — bash, ejecución de código, uso del ordenador, editor de texto, búsqueda web, conector MCP. Salida estructurada: compatible. La tarjeta del sistema de Opus 4.7 señala que el modelo es más minucioso en la autoverificación de salidas, lo que significa que algunos scaffolding de prompts existentes (“verifica el diseño de la diapositiva antes de devolver”) pueden eliminarse.
Vale la pena señalar la relación con Claude Mythos: Opus 4.7 está explícitamente posicionado como el banco de pruebas para las salvaguardas que Anthropic eventualmente quiere implementar en modelos de clase Mythos. Opus 4.7 lleva detección automatizada de uso cibernético que Mythos Preview no tiene en la misma forma. Esto no es directamente relevante para la integración de la API — pero señala hacia dónde se dirige la hoja de ruta de modelos de Anthropic.
Preguntas frecuentes
¿Está disponible Claude Opus 4.7 a través de la API?
Sí. Quedó disponible de forma general el 16 de abril de 2026. El ID del modelo es claude-opus-4-7. Disponible en la API directa de Anthropic, Amazon Bedrock, Google Vertex AI y Microsoft Foundry.
¿Cómo se comparan los precios de Opus 4.7 con los de Opus 4.6?
La tarifa es idéntica: $5 por millón de tokens de entrada, $25 por millón de tokens de salida. Pero el tokenizador actualizado puede inflar los recuentos reales de tokens hasta un 35%, lo que significa que el mismo prompt puede costar más ejecutarlo en 4.7 que en 4.6.
¿Puedo ejecutar Claude Opus 4.7 a través de una API de inferencia de terceros?
Sí. Múltiples plataformas de agregación y capas de enrutamiento admiten Opus 4.7. La pregunta clave es si la capa de terceros expone funciones específicas de 4.7 como los presupuestos de tareas y el nivel de esfuerzo xhigh, o solo transmite las completaciones estándar.
¿Cuál es la diferencia entre Claude Opus 4.7 y Claude Mythos?
Mythos Preview es el modelo más potente de Anthropic, restringido a socios seleccionados bajo el Proyecto Glasswing para trabajo de ciberseguridad defensiva. Opus 4.7 está disponible de forma general y lleva salvaguardas automatizadas que Anthropic está probando antes de ampliar eventualmente el acceso de clase Mythos. Son diferentes niveles de capacidad con diferentes modelos de acceso.
¿Debería mi equipo esperar a Opus 4.7 o quedarse en 4.6 para producción?
Si tus prompts están bien probados en 4.6 y tu sistema funciona bien, no te apresures. Prueba 4.7 en una pequeña porción del tráfico, mide el impacto del tokenizador y los cambios en el comportamiento de los prompts, luego migra por etapas. El modelo es mejor — pero la migración no es un esfuerzo nulo.
Sigo ejecutando 4.6 y 4.7 en paralelo en mis propios pipelines. Las ganancias en benchmark son reales, pero también lo es el reajuste de prompts. Tendré más datos en una o dos semanas sobre si la sobrecarga del tokenizador se compensa con las ganancias de eficiencia derivadas de menos llamadas a herramientas. Esa parte aún no está resuelta.
Artículos anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber