DeepSeek V4 API-Migration: Modellnamen vor Juli aktualisieren
DeepSeek-chat und deepseek-reasoner werden am 24. Juli 2026 eingestellt. Schrittweise Migration zu deepseek-v4-pro und deepseek-v4-flash mit Code-Diffs.

Ich habe am Montagmorgen die Produktionslogs durchgesehen und 14.000 Aufrufe gezählt, die immer noch deepseek-chat treffen. In drei Monaten liefert jeder davon einen 404 zurück. Das ist die Situation, in der viele Teams stecken, ohne es zu wissen — DeepSeek hat die Deprecation angekündigt, der Kalender hat sich weitergedreht, und niemand im Bereitschaftsdienst hat das Changelog an die Leute weitergeleitet, die die Integration tatsächlich verantworten. Ich habe die Migration letzte Woche auf unserem eigenen Stack durchgeführt, also ist das hier die Version mit den Diffs, die funktioniert haben, nicht die Version, die die Ankündigung paraphrasiert. Mein Name ist Dora, ich schreibe Infrastrukturnotizen für Backend-Teams, und die Kurzfassung lautet: Es ist eine einzeilige Code-Änderung, aber das Testing drum herum ist der Punkt, an dem alles schiefläuft, wenn man es überspringt.
Bereits bei DeepSeek? Wechsle zu WaveSpeedAI ohne Code-Änderungen — gleiches OpenAI SDK, nur Base-URL und Key ändern. DeepSeek V3.2 API → · DeepSeek R1 API →
Das harte Datum ist 24. Juli 2026, 15:59 UTC. Danach geben deepseek-chat und deepseek-reasoner Fehler zurück. Es wird keine Verlängerung diskutiert. Migriere jetzt, schließe das Testing im Mai ab, und lass den Juni für Nachzügler.
Was sich ändert und wann
Deprecation-Zeitplan: deepseek-chat / deepseek-reasoner werden am 2026-07-24 abgeschaltet
DeepSeek V4 wurde am 24. April 2026 veröffentlicht, und die offiziellen DeepSeek V4 Release Notes besagen, dass beide veralteten Modellnamen nach dem 24. Juli 2026, 15:59 UTC „vollständig eingestellt und nicht mehr zugänglich” sein werden. Das ist ein hartes Enddatum, keine weiche Warnung. Anfragen mit den alten Namen schlagen nach diesem Zeitstempel fehl.
Während der Übergangsphase — jetzt bis zum 24. Juli — funktionieren beide veralteten Namen weiterhin, werden aber transparent zu V4-Flash weitergeleitet. Du läufst also bereits auf V4, egal ob du deinen Code aktualisiert hast oder nicht.
Neue Modellnamen: deepseek-v4-pro, deepseek-v4-flash
Zwei neue Modell-IDs ersetzen die alten Aliase:
deepseek-v4-pro— 1,6T Gesamtparameter, 49B aktiv, 1M Kontextfenster, 384K maximale Ausgabe. Die reasoning-intensive Option.deepseek-v4-flash— 284B gesamt, 13B aktiv, gleiche 1M Kontext. Günstiger und schneller, geeignet für die meisten Produktions-Workloads.
Beide unterstützen Thinking- und Non-Thinking-Modi über dieselbe Modell-ID. Du wählst Reasoning nicht mehr durch ein separates Modell — du schaltest es über Parameter um. Das ist der Teil, der naive Migrationen kaputt macht.
Übergangs-Mapping während der Übergangsphase
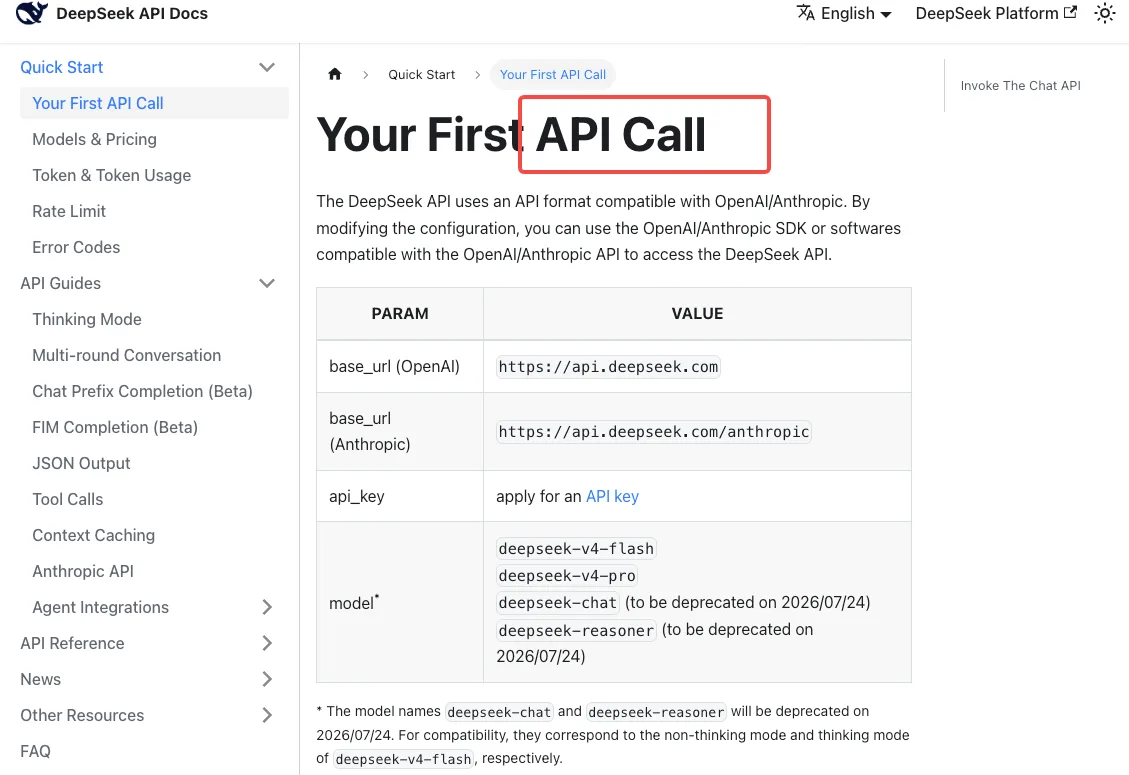
Gemäß der DeepSeek API Quickstart-Dokumentation ist das aktuelle Kompatibilitäts-Mapping:
deepseek-chat→deepseek-v4-flash(Non-Thinking-Modus)deepseek-reasoner→deepseek-v4-flash(Thinking-Modus)
Beachte, was das bedeutet: Wenn du deepseek-reasoner verwendet hast, läufst du bereits auf Flash, nicht auf Pro. Wenn sich deine Reasoning-Workloads in der letzten Woche etwas anders angefühlt haben, liegt es daran. Um Reasoning auf Pro-Niveau zu erhalten, musst du explizit zu deepseek-v4-pro migrieren — der Alias leitet dich dort nie hin.
Checkliste vor der Migration
Jeden Service inventarisieren, der die DeepSeek API trifft
Durchsuche das gesamte Monorepo. Beide Strings:
grep -rn "deepseek-chat\|deepseek-reasoner" .Vertraue nicht deiner Erinnerung, welche Services es verwenden. Ich habe zwei Cron-Jobs und einen Webhook-Handler gefunden, die ich vergessen hatte. Überprüfe auch .env-Templates, Deploy-Konfigurationen, IaC-Dateien und alle LLM-Gateway-Routing-Tabellen. Wenn du einen Proxy wie LiteLLM oder n1n.ai verwendest, überprüfe auch dort — das DeepSeek Change Log auf api-docs.deepseek.com bestätigt, dass die alten Namen für eine vollständige Einstellung geplant sind, nicht nur Deprecation-Warnungen, also wird alles, was sie noch verwendet, hart fehlschlagen.
Aktuelle Latenz- und Qualitäts-Baselines erfassen
Bevor du einen einzigen Str ing änderst, erstelle einen Snapshot davon, wie „funktionierend” heute aussieht:
ing änderst, erstelle einen Snapshot davon, wie „funktionierend” heute aussieht:
- p50 / p95 / p99 Latenz pro Endpunkt
- Ausgabe-Token-Verteilung (Mittelwert, Standardabweichung)
- Qualitätsbewertung auf deinem Eval-Set, falls vorhanden
- Tägliche Kosten pro Service
V4-Flash verhält sich etwas anders als die V3.x-Gewichte, auf die deepseek-chat früher verwies. Du möchtest eine Baseline, damit du sagen kannst, was sich nach dem Wechsel geändert hat.
Identifizieren, wo der Thinking-Modus implizit war (Reasoner)
Jeder Service, der deepseek-reasoner verwendete, bekam den Thinking-Modus kostenlos. Nach der Migration ist der Thinking-Modus opt-in über einen Parameter. Wenn du vergisst, ihn hinzuzufügen, verlierst du stillschweigend deine Reasoning-Fähigkeit und deine Ausgaben werden schlechter, ohne dass ein Fehler auftritt. Dies ist der bei weitem häufigste Migrationsfehler.
Erforderliche Code-Änderungen
Modellnamen-Tausch (Vorher/Nachher-Beispiele)
Für Services, die keinen Thinking-Modus benötigen:
python
# Vorher
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# Nachher
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Für Services, die Reasoning benötigen, ist die Änderung größer.
reasoning_effort hinzufügen, wo Reasoner verwendet wurde
Die DeepSeek Thinking-Mode-Dokumentation gibt an, dass Thinking über extra_body aktiviert und mit reasoning_effort gesteuert wird:
python
# Vorher
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# Nachher
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Einige Dinge zu beachten:
reasoning_effortakzeptierthighundmax. Laut den Docs werdenlowundmediumaufhighgemappt, undxhighwird aufmaxgemappt. Der Standard für Thinking-Mode-Anfragen isthigh.- Thinking-Modus ignoriert
temperature,top_p,presence_penaltyundfrequency_penaltystillschweigend. Das Setzen führt nicht zu einem Fehler — es tut einfach nichts. Wenn dein altes Reasoner-Setup auftemperature=0.7angewiesen war, wurde das bereits ignoriert.
Base-URL und Auth — unverändert
Dieser Teil ist wirklich einfach. https://api.deepseek.com bleibt gleich. Dein API-Key bleibt gleich. Sowohl OpenAI ChatCompletions als auch Anthropic SDK-Formate werden unterstützt, sodass dein bestehendes Client-Setup weiterhin funktioniert. Nur der model-String und (für Reasoning) das extra_body ändern sich.
Regressionstesting
Ausgabe-Shape-Unterschiede, die du erwarten solltest
V4-Flash ist ein anderes Modell als die V3.2-Gewichte, auf die deepseek-chat früher verwies. Erwarte:
- Leicht unterschiedliche Ausführlichkeit — V4 tendiert dazu, bei gleichem Prompt längere Ausgaben zu produzieren
- Andere Formatierungsentscheidungen für Code-Blöcke und Listen
- Besseres Befolgen von Anweisungen bei agentischen Aufgaben
- Der Tokenizer ist aus derselben Familie, aber Token-Anzahlen können sich verschieben
Führe dein Eval-Set aus. Gehe nicht davon aus, dass „kompatibel” bedeutet „identisch”.
Kosten-Baseline neu überprüfen
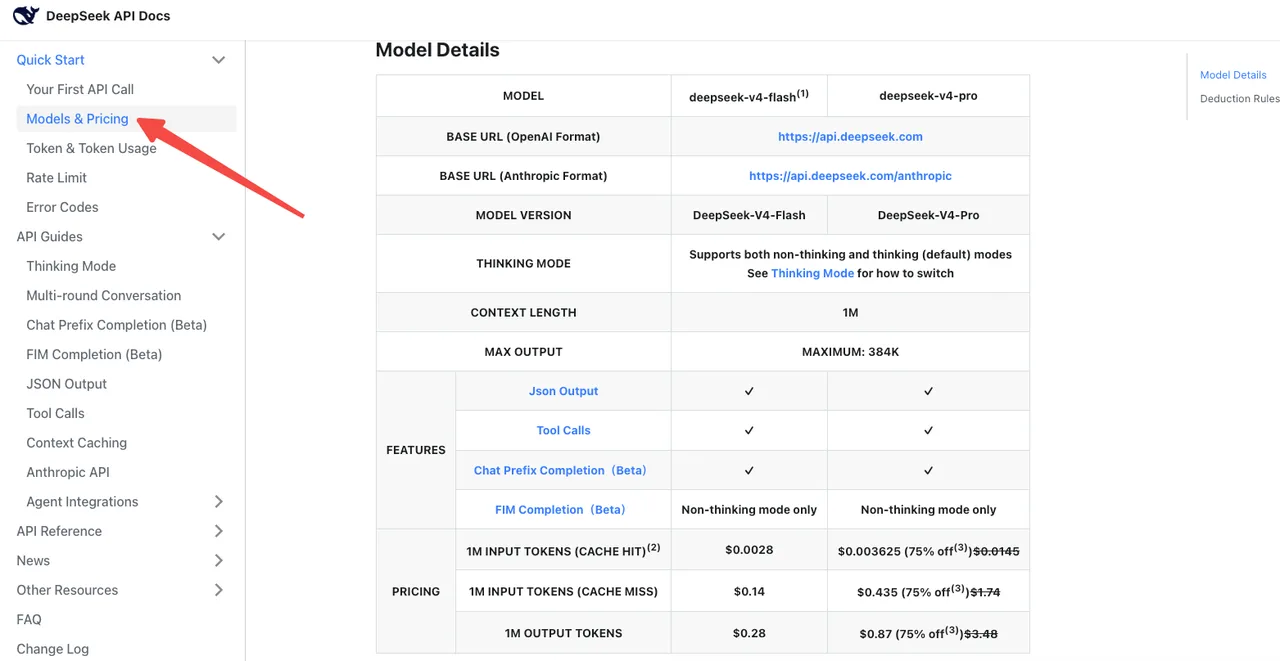
Gemäß der offiziellen DeepSeek-Preisseite kostet V4-Flash 0,14 $ / 0,28 $ pro 1M Eingabe-/Ausgabe-Token zu Standardtarifen. V4-Pro kostet 1,74 $ / 3,48 $ (derzeit 75% Rabatt bis 2026/05/05). Die Cache-Hit-Preise wurden auf 1/10 des Einführungspreises über die gesamte Produktlinie gesenkt.
Die Falle: Der Thinking-Modus auf V4-Pro verbrennt dramatisch mehr Ausgabe-Token als der alte Reasoner. Artificial Analysis hat V4-Pro als „sehr ausführlich” bei Ausgabemengen eingestuft, was etwa das 4-fache der durchschnittlichen Reasoning-Token-Anzahl generiert. Deine Rechnung kann steigen, auch wenn deine Modellnamenänderung neutral aussieht.
Agent-Workflow-Validierung
Wenn du mehrstufige Agents betreibst, teste die gesamte Kette erneut. Das Tool-Calling-Verhalten von V4 ist näher an Claude Code als V3.x. Argument-Schemas, die funktioniert haben, sind meist in Ordnung, aber das Modell ist aggressiver beim Wiederholen und Selbstkorrigieren, was manchmal mehr Tool-Aufrufe pro Aufgabe bedeutet — und mehr Token.
Rollout-Strategie
Feature-Flag-Ansatz
Führe keinen globalen Tausch durch. Kapsele den Modellnamen in einem Konfigurations-Flag pro Service:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Führe Service für Service aus. Beobachte Fehlerquoten und p99-Latenz für 24-48 Stunden pro Service, bevor du weitermachst.
Shadow-Traffic während der Umstellung
Für Services mit hohem Traffic spiegele Anfragen für ein kurzes Zeitfenster auf beide, alt und neu. Vergleiche Ausgaben offline. Das ist der einzige Weg, stille Qualitätsregressionen zu erkennen, bevor es die Nutzer tun.
Häufige Migrationsfallen
Die fünf, die ich letzte Woche tatsächlich gesehen habe:
deepseek-reasoner→deepseek-v4-protauschen ohneextra_body={"thinking": {"type": "enabled"}}hinzuzufügen. Reasoning-Qualität sinkt, kein Fehler wird ausgelöst.temperature=0für Reasoning-Workloads hardcoden und davon ausgehen, dass es noch funktioniert (es wird im Thinking-Modus stillschweigend ignoriert).- Vergessen, dass der Alias
deepseek-reasonernur auf V4-Flash gemappt wurde, nicht auf V4-Pro. Die Migration zu Pro ist ein Upgrade, kein gleichwertiger Tausch. - Monitoring-Dashboards nicht aktualisieren. Wenn dein Dashboard nach Modellnamen gruppiert, erscheinen V4-Aufrufe nicht unter deiner alten DeepSeek-Kachel, bis du die Bezeichnung korrigierst.
- Drittanbieter-Integrationen vergessen. Wenn du über LiteLLM, OpenRouter oder ein Gateway proxyst, haben Anbieter wie OpenRouter bereits V4-Routen veröffentlicht — aber deine Gateway-Konfiguration könnte noch den alten Namen anheften.
FAQ
Was passiert, wenn ich nicht bis zum 24. Juli migriere?
Nach dem 24. Juli 2026, 15:59 UTC, schlagen Anfragen mit deepseek-chat oder deepseek-reasoner fehl. Die offizielle Mitteilung besagt, dass beide Namen „vollständig eingestellt und nicht mehr zugänglich” sein werden. Es wurde keine Verlängerung angekündigt.
Ist deepseek-v4-flash ein Drop-in-Ersatz für deepseek-chat?
Für Non-Thinking-Workloads größtenteils ja — gleiche Geschwindigkeitsstufe, gleiche Preisklasse, gleicher Endpunkt. Ausgaben unterscheiden sich leicht, da die zugrunde liegenden Gewichte verschieden sind, also führe deine Evals erneut aus. Für Thinking-Workloads musst du den extra_body-Thinking-Parameter explizit hinzufügen.
Wie bewahre ich das Reasoner-Verhalten?
Verwende deepseek-v4-flash mit aktiviertem Thinking-Modus, wenn du auf der gleichen Rechenstufe bleiben möchtest (das entspricht dem, was deepseek-reasoner bereits tat). Verwende deepseek-v4-pro mit aktiviertem Thinking, wenn du ein Qualitäts-Upgrade möchtest. Beide erfordern extra_body={"thinking": {"type": "enabled"}}.
Ändert sich meine Abrechnungsstruktur?
Das Pro-Token-Abrechnungsmodell ist gleich. Tarife unterscheiden sich — Flash ist günstiger als die alten deepseek-chat-Tarife, Pro ist teurer, aber derzeit rabattiert. Cache-Hit-Preise sind jetzt 10% der Standardtarife. Achte auf Token-Inflation bei der Ausgabe im Thinking-Modus.
Kann ich beide, alt und neu, parallel testen?
Ja. Sowohl veraltete als auch neue Modellnamen funktionieren gleichzeitig bis zum 24. Juli. Verwende ein Feature-Flag, um einen Prozentsatz des Traffics zu V4 zu routen und zu vergleichen. Das ist der risikoärmste Migrationspfad.
Wenn du morgen in Produktion gehst, ist der sicherste Schritt der kleinste: Tausche zuerst deepseek-chat → deepseek-v4-flash, lass Reasoning-Workloads für zuletzt, und rühre V4-Pro nicht an, bis du es gegen dein tatsächliches Eval-Set benchmarkt hast. Die Deadline ist real, aber sie liegt auch drei Monate in der Zukunft — es gibt Zeit, das sorgfältig zu machen. Die Teams, die Ende Juli erwischt werden, sind diejenigen, die es als Ein-Zeilen-PR behandelt und den Regressions-Durchlauf übersprungen haben. Sei nicht diese Teams.
Frühere Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten