直接使用OpenAI還是透過平台存取GPT-5.5?
團隊應直接從OpenAI存取GPT-5.5,還是透過模型平台?比較推出速度、備援機制、路由選擇與操作控制能力。

GPT-5.5 於 4 月 23 日在 ChatGPT 和 Codex 上線。API 在一天後的 4 月 24 日跟進。接著在 5 月 5 日,GPT-5.5 Instant 成為 ChatGPT 的預設模型,並以 chat-latest 的形式發佈至 API。短短兩週內,三個不同的推出時間點,各有不同的層級資格與適用平台。
我是 Dora。我追蹤這件事是因為我必須這樣做。我有一個工作流程涉及 GPT-5 系列模型,而 ChatGPT 發佈與 API 發佈之間 24 小時的落差對我而言並非理論問題。這意味著要麼等待,要麼透過已有存取權限的方案繞道。這個抉擇——等待還是繞道——正是每個使用前沿模型的團隊在每次發佈時都必須面對的問題。因此這篇文章就是圍繞這個主題而寫。
問題不在於「OpenAI 好不好」。而是:當 GPT-5.5(或下一個繼任者)分階段發佈時,你是直接呼叫 OpenAI,還是坐在一個替你處理分階段問題的平台後面?對不同的團隊而言,兩種答案都是正確的。以下是我誠實審視後所看到的情況。
團隊存取 GPT-5.5 的兩種方式
直接使用供應商
你用 OpenAI 金鑰直接打 api.openai.com。一套 SDK、一份文件、一張帳單。當 OpenAI 發佈新的模型名稱時,你在設定檔裡改一個字串就能使用——前提是你的層級在第一天就有存取權。
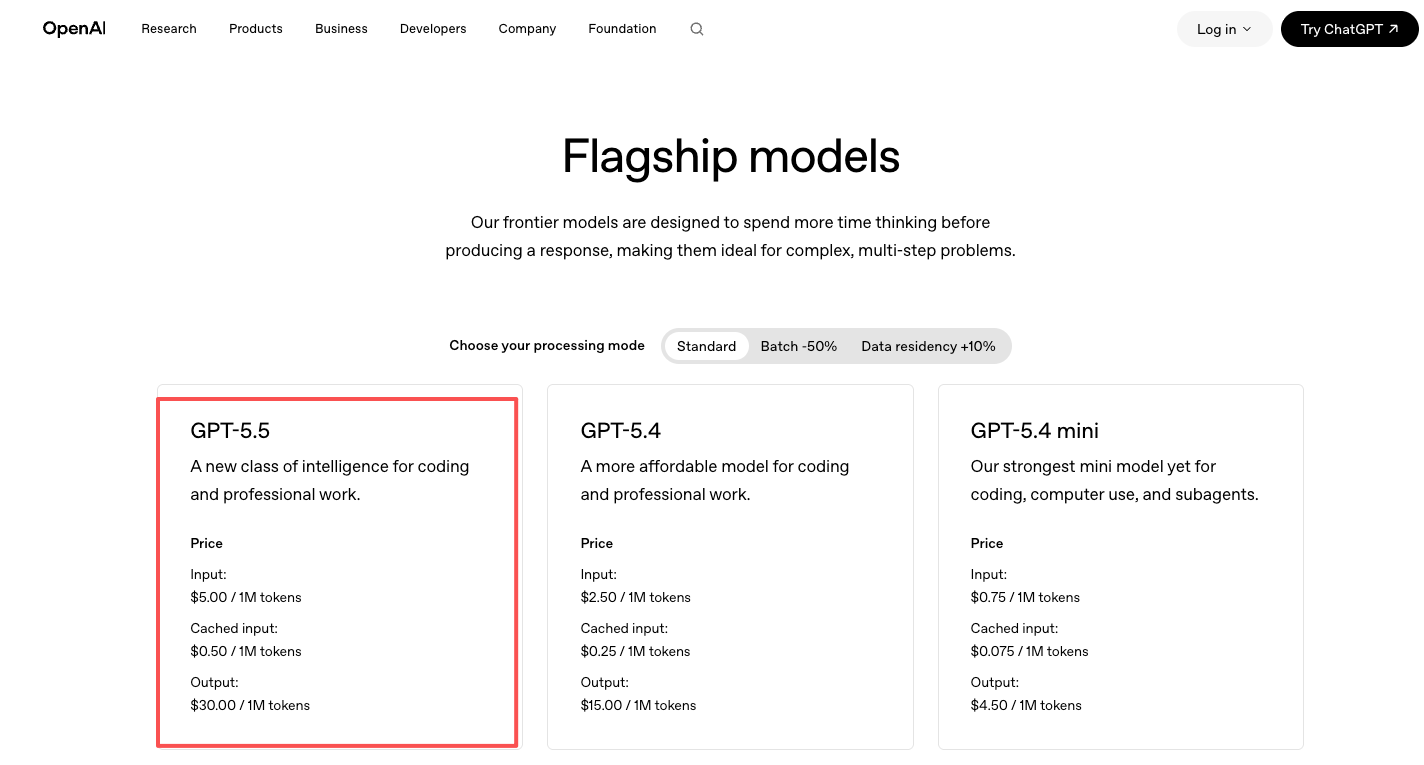
定價資訊在 OpenAI 官方定價頁面:GPT-5.5 為每百萬 token 輸入 $5、輸出 $30,GPT-5.5 Pro 為每百萬 token 輸入 $30、輸出 $180。大約是 GPT-5.4 的兩倍。你直接付費給 OpenAI。
透過模型平台存取
你打到一個路由層——OpenRouter、LiteLLM、內部閘道,或多模型平台——由該層代替你與 OpenAI 溝通。SDK 介面與 OpenAI 相同(大多數平台相容 OpenAI),但模型字串可以指向 GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro,或三者的備援鏈。
你付費給平台,平台付費給 OpenAI。有時有少量加成,有時沒有。作為交換,你獲得跨供應商的統一帳單、無需改動程式碼即可切換模型,以及出問題時的備援路徑。
這就是全貌。兩者都沒有「比較好」,它們各自針對不同的需求進行最佳化。
直接存取的優勢所在
簡單性、低抽象層次,以及供應商專屬最佳化
如果你只使用 OpenAI 的模型,直接呼叫 OpenAI 是最簡單的架構。一個廠商、一套錯誤碼、一個狀態頁面。出問題時,你知道該找誰。
另一個重要因素是,OpenAI 發佈的功能不一定能立即在抽象層中使用。Responses API、推理力度控制、嚴格結構化輸出、Codex 工具介面、供應商專屬的工具呼叫格式——平台最終會跟上,但「最終」可能意味著數週。如果你的產品在第一天就需要 OpenAI 的某個特定功能,直接路徑是唯一的路徑。
間接呼叫還有一個真實的成本,鮮少有人談到。你的程式碼與模型之間每多一層,就多一個可能出問題的地方、多一個需要監控的狀態頁面、多一個月底的帳單驚喜。對於一個在正式環境中運行單一模型的小團隊而言,這些開銷可能超過帶來的好處。
當一個模型就夠用的時候
許多團隊確實只需要一個模型。他們一年前選了 GPT-5,工作流程運作順暢,提示詞已調整到位,評估結果穩定。他們不想跟 Claude 做 A/B 測試,不想故障轉移到 Gemini,只想模型持續運作、帳單保持可預期。
對這樣的團隊來說,路由層是在解決一個根本不存在的問題。直接存取才是正確答案,在上面加一個平台反而是錯誤的選擇。不要為你用不到的靈活性支付複雜性的代價。
模型平台的優勢所在
推出速度、備援與路由控制
這正是 GPT-5.5 的時間軸真正重要的地方。在 4 月 23 日至 4 月 24 日之間,GPT-5.5 在 ChatGPT 上已上線,但尚未進入 API。CNBC 當時報導,OpenAI 表示 API 推出需要「不同的安全措施」,且未給出確定日期。對大多數團隊而言,這 24 小時的落差無關痛癢。但對少數團隊——任何有「我們在 X 小時內部署最新模型」合約條款的——這就是問題。
平台層無法讓 OpenAI 的速度更快。但它改變了「等待」的樣貌。在 GPT-5.5 尚未進入 OpenAI API 的時候,Claude Opus 4.7 已可用,Gemini 3.1 Pro 也已可用。路由設定可以在 GPT-5.5 上線後優先使用它,同時備援到當前可用的任何前沿模型,且在情況改變時無需重新部署程式碼。
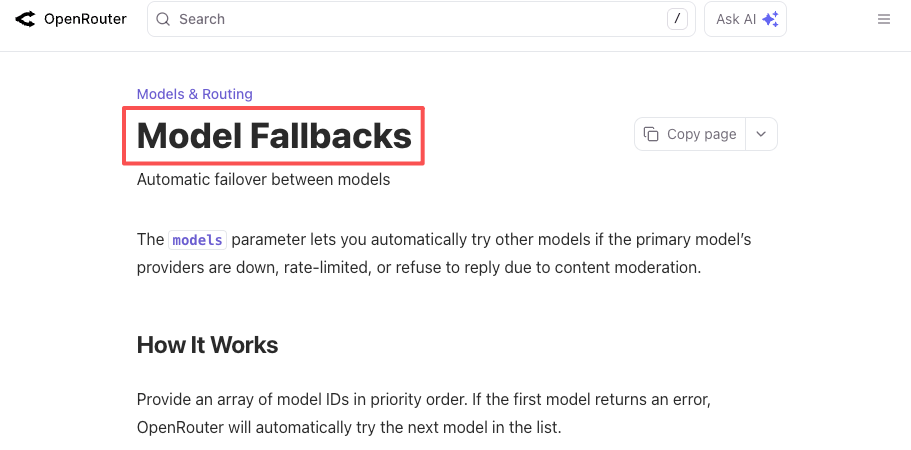
同樣的邏輯適用於中斷事故。今年 OpenAI 發生過長達數小時的 API 故障,其他供應商也一樣。如果你的產品硬性要求「一個現在就能工作的 LLM」,你要麼自己建構備援機制,要麼讓平台幫你處理。OpenRouter 的備援文件和 LiteLLM 的路由文件都以具體設定說明了這一點:宣告主要模型,列出備援模型,當主要模型失敗時獲得有效回應。
這不是假設情境,而是我這一季遇到過兩次的真實情況。
多模型實驗與採購韌性
平台發揮價值的另一個場景,是當你還不確定哪個模型適合這項工作時——或者當你預期答案在六個月後會改變。
前沿模型的領導地位大約每 3 到 6 個月輪換一次。GPT-5.5 發佈,然後 Anthropic 發佈,然後 Google 發佈,「最適合寫程式碼的模型」或「最適合長文脈分析的模型」的答案持續在變動。如果你已針對單一供應商的 SDK 進行整合,切換模型意味著真實的工程工作。如果你在路由層後面,切換意味著改一個模型字串。
同樣的邏輯適用於採購。平台將跨供應商的支出整合為一張發票、一套用量分析、一個預算管控。財務團隊對這件事的重視程度超乎工程師的想像。「我們只有一個 AI 廠商」遠比「我們有三個 AI 廠商,且每個廠商的月度支出都在變動」更容易管理。
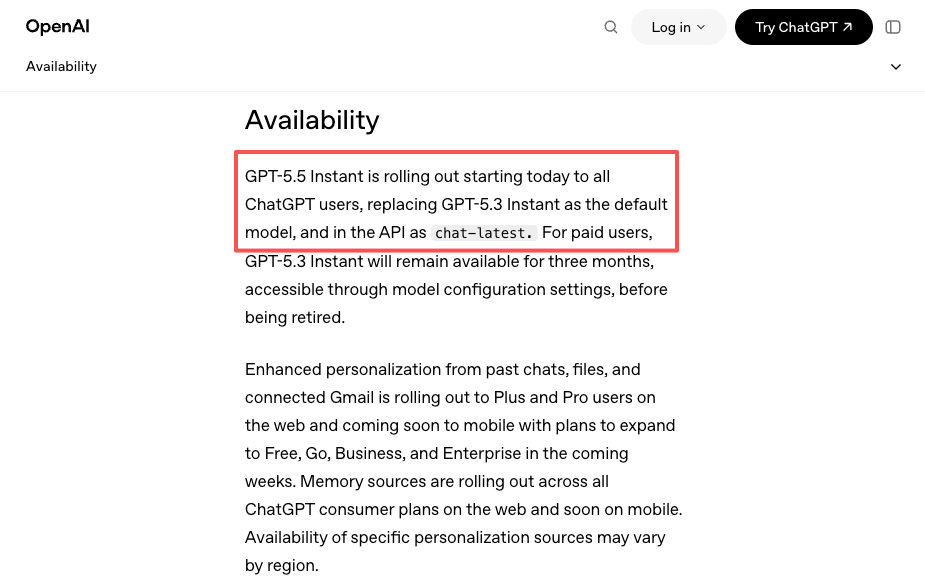
還有一個較為軟性的訊號:5 月 5 日 GPT-5.5 Instant 作為新的 ChatGPT 預設模型發佈——OpenAI 的公告中有詳細說明——在 API 中以 chat-latest 的形式推出。釘定該別名的團隊自動獲得升級,釘定特定版本日期的團隊則沒有。平台可以為你提供跨供應商的統一抽象,涵蓋這兩種行為,而無需你分別追蹤每個供應商的版本規則。
依團隊類型的決策框架
我不喜歡部落格文章裡的框架表格,因為它們過度簡化。但粗略的啟發規則在此確實有幫助,所以:
| 團隊特性 | 較適合的選擇 | 原因 |
|---|---|---|
| 個人開發者,單一模型,單一產品 | 直接 OpenAI | 路由層增加成本卻未解決實際問題 |
| 正式環境團隊,僅使用 OpenAI,依賴供應商專屬功能 | 直接 OpenAI | 第一天即可存取 Responses API、結構化輸出等 |
| 正式環境團隊,評估中使用多模型,計劃持續多模型 | 平台 | 切換成本是主導變數 |
| 有嚴格正常運行時間 SLA 的 LLM 功能團隊 | 平台 | 備援鏈是最便宜的保險 |
| 運行內部工具、非面向客戶的團隊 | 皆可 | 選擇對你而言運維負擔較低的方案 |
| 有採購流程、每個廠商需安全審查的企業 | 平台 | 一份合約勝過 N 份合約 |
| 比較前沿模型的研究/實驗團隊 | 平台 | 切換模型是整個工作流程的核心 |
| 依賴第一天就能存取全新模型版本的團隊 | 有零日覆蓋的平台,或高層級的直接供應商 | 兩者皆可,但層級資格比人們想像的更重要 |
這張表格不是定論,而是一個起始問題:哪一行最接近我的團隊,這對我的預設架構意味著什麼?
常見問答

直接整合 OpenAI 何時就足夠了?
當你已經選定 OpenAI、使用量還不足以證明另外談一份平台合約是合理的,且沒有明確需要備援到其他供應商的情況。大多數在正式環境中運行 OpenAI 工作負載的中小型團隊都屬於這一類。
為什麼團隊會在上面再加一個模型平台?
出現最多的三個原因:無需改動程式碼即可進行多模型路由、在中斷或部分推出期間提供備援,以及跨供應商的統一計費。如果這三點目前都不適用於你,你可能現在還不需要它。
平台在部分推出期間有幫助嗎?
有——但僅限於「我需要一個可用的前沿模型,而我偏好的那個目前還不可用」這種失敗模式。如果你明確需要 GPT-5.5 且只要 GPT-5.5,它就幫不上忙。平台可以從清單中路由到當前最佳可用模型,但它無法憑空提供 OpenAI 尚未發佈的模型存取權。
多一層會帶來什麼取捨?
你在自己與模型之間多了一個廠商。 這意味著多一個狀態頁面、多一個計費介面、多一個潛在故障點、有時有少量加成,以及偶爾在供應商專屬功能上有延遲。這些都不是決定性因素,但都是你應該計入的真實成本。
結論
誠實的版本是這樣的。直接使用 OpenAI 對許多團隊而言是正確答案——可能比平台倡導者所承認的更多。模型平台對許多其他團隊而言是正確答案——可能比純 OpenAI 陣營所承認的更多。這種分歧不是意識形態問題,而是關於你實際使用多少個模型、你的正常運行時間故事對 LLM 的依賴程度,以及當下一個前沿模型發佈時你能承受多少切換成本。
GPT-5.5 的推出是一次有用的壓力測試,因為它在兩週內有三個時間點:ChatGPT 率先,API 晚一天,Instant 版本在十二天後。每個使用前沿模型的團隊都將一次又一次地經歷這種模式的各種版本。值得現在在平靜的時候就決定,下次你想持有的是哪種架構。
用你自己的設置算一算,那會比這篇文章告訴你更多。
相關文章:




