DeepSeek V4 API 遷移指南:在七月前更新模型名稱
DeepSeek-chat 與 deepseek-reasoner 將於 2026 年 7 月 24 日停用。附逐步遷移至 deepseek-v4-pro 與 deepseek-v4-flash 的指南及程式碼差異對比。

我在某個週一早上拉了生產環境日誌,數了一下,還有 14,000 次呼叫仍在打 deepseek-chat。三個月後,這些請求每一個都會回傳 404。這正是很多團隊在渾然不知的情況下正在走入的困境——DeepSeek 宣布了棄用計畫,日曆繼續往前走,但輪值待命的人沒有把 changelog 轉給真正負責整合的人。我上週在自己的技術棧上跑完了這次遷移,所以這篇文章附上的是實際可用的 diff,而不是對公告的改寫摘要。我叫 Dora,專門為後端團隊撰寫基礎架構筆記。簡短版本是:程式碼改動只有一行,但如果你跳過測試環節,那才是一切出問題的地方。
已經在用 DeepSeek? 無需修改程式碼即可切換到 WaveSpeedAI——同樣的 OpenAI SDK,只需更換 base URL 和金鑰。DeepSeek V3.2 API → · DeepSeek R1 API →
硬性截止日期是 2026 年 7 月 24 日 UTC 15:59。此後,deepseek-chat 和 deepseek-reasoner 將回傳錯誤。目前沒有任何延期的討論。請現在開始遷移,五月完成測試,六月留給還沒跟上的部分。
變更內容與時程
棄用時間表:deepseek-chat / deepseek-reasoner 將於 2026-07-24 下線
DeepSeek V4 於 2026 年 4 月 24 日發布,DeepSeek V4 官方發布說明指出,兩個舊版模型名稱將在 2026 年 7 月 24 日 UTC 15:59 之後「完全停用且無法存取」。這是硬性截止,不是軟性警告。在那個時間戳之後使用舊名稱的請求將會失敗。
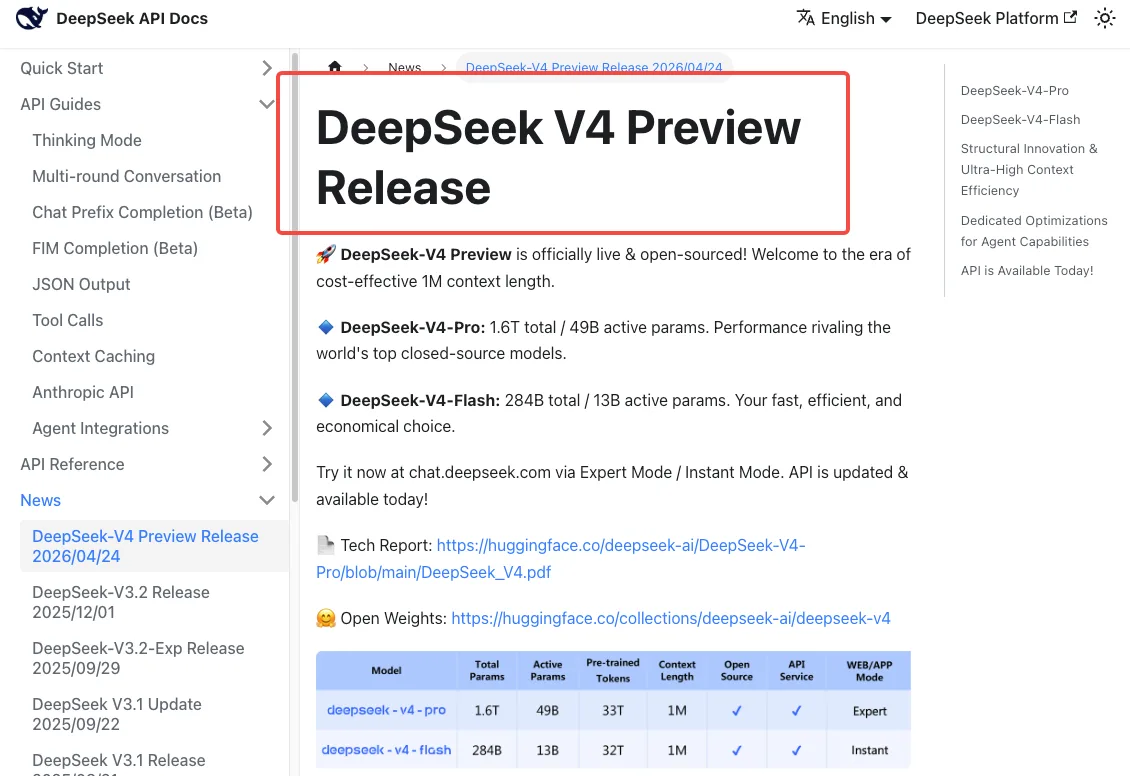
在寬限期內——從現在到 7 月 24 日——兩個舊名稱仍可繼續使用,但它們會被透明地路由至 V4-Flash。所以無論你是否更新了程式碼,你實際上已經在使用 V4 了。
新模型名稱:deepseek-v4-pro、deepseek-v4-flash
兩個新的模型 ID 取代了舊的別名:
deepseek-v4-pro——總參數量 1.6T,活躍參數 49B,1M 上下文視窗,最大輸出 384K。適合需要深度推理的場景。deepseek-v4-flash——總參數量 284B,活躍參數 13B,同樣 1M 上下文。成本更低、速度更快,適合大多數生產工作負載。
兩者都透過同一個模型 ID 支援思考模式與非思考模式。你不再需要透過選擇不同的模型來啟用推理——而是透過參數來切換。這是粗糙遷移方式容易出問題的地方。
寬限期內的過渡對應關係
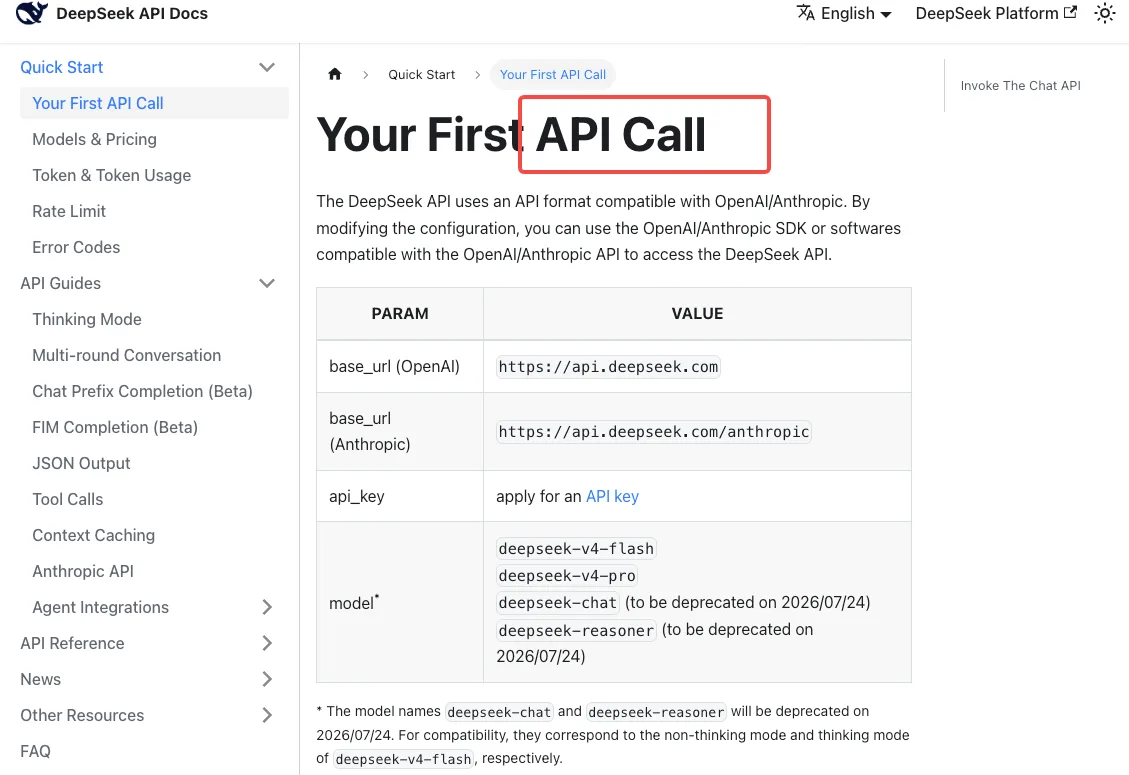
根據 DeepSeek API 快速入門文件,目前的相容性對應關係為:
deepseek-chat→deepseek-v4-flash(非思考模式)deepseek-reasoner→deepseek-v4-flash(思考模式)
注意這代表的含義:如果你原本使用 deepseek-reasoner,你現在實際上跑的是 Flash,而不是 Pro。如果你的推理工作負載在上週感覺有些不同,這就是原因。要獲得 Pro 等級的推理能力,你必須明確遷移到 deepseek-v4-pro——別名永遠不會把你指向那裡。
遷移前檢查清單
清查所有呼叫 DeepSeek API 的服務
在整個 monorepo 中執行 grep,搜尋這兩個字串:
grep -rn "deepseek-chat\|deepseek-reasoner" .不要憑記憶判斷哪些服務有用到它。我發現了兩個我早已忘記存在的 cron job 和一個 webhook handler。還要檢查 .env 模板、部署設定、IaC 檔案,以及任何 LLM 閘道路由表。如果你使用 LiteLLM 或 n1n.ai 等代理,也要在那裡檢查——DeepSeek 在 api-docs.deepseek.com 上的更新日誌確認舊名稱計畫完全停止使用,而不只是發出棄用警告,因此任何仍在使用舊名稱的服務都將硬性失敗。
記錄目前的延遲與品質基準
在你改動任何一個字 串之前,先快照「正常運作」現在長什麼樣子:
串之前,先快照「正常運作」現在長什麼樣子:
- 每個端點的 p50 / p95 / p99 延遲
- 輸出 token 分佈(平均值、標準差)
- 如果你有評估集,記錄品質分數
- 每個服務的每日成本
V4-Flash 與 deepseek-chat 過去路由到的 V3.x 權重行為略有不同。你需要一個基準,這樣才能在替換後判斷哪些東西發生了變化。
找出哪些地方隱式使用了思考模式(reasoner)
所有使用 deepseek-reasoner 的服務都免費獲得了思考模式。遷移後,思考模式需要透過參數明確啟用。如果你忘記加上它,你的推理能力會無聲無息地消失,輸出品質下降卻不會有任何錯誤提示。這是最常見的遷移 bug。
需要的程式碼修改
模型名稱替換(修改前/後範例)
對於不需要思考模式的服務:
# 修改前
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# 修改後
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)對於需要推理能力的服務,修改幅度更大。
在原本使用 reasoner 的地方加入 reasoning_effort
DeepSeek 思考模式文件指出,思考模式透過 extra_body 啟用,並以 reasoning_effort 進行調整:
# 修改前
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# 修改後
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)幾點需要注意:
reasoning_effort接受high和max。根據文件,low和medium會被對應到high,xhigh會被對應到max。思考模式請求的預設值為high。- 思考模式會靜默忽略
temperature、top_p、presence_penalty和frequency_penalty。 設定它們不會報錯——只是不會有任何效果。如果你舊的 reasoner 設定依賴temperature=0.7,那它早就已經被忽略了。
Base URL 和驗證——保持不變
這部分確實很簡單。https://api.deepseek.com 維持不變。你的 API 金鑰維持不變。OpenAI ChatCompletions 和 Anthropic SDK 格式都受到支援,所以你現有的客戶端設定繼續有效。只有 model 字串,以及(對於推理)extra_body 需要修改。
回歸測試
你應該預期的輸出形式差異
V4-Flash 與 deepseek-chat 過去路由到的 V3.2 權重是不同的模型。請預期:
- 略微不同的詳盡程度——在相同提示下,V4 傾向於產生更長的輸出
- 對程式碼區塊和列表的格式選擇不同
- 在代理任務上有更好的指令遵循能力
- 分詞器屬於同一系列,但 token 數量可能有所變動
執行你的評估集。不要假設「相容」就意味著「完全相同」。
重新確認成本基準
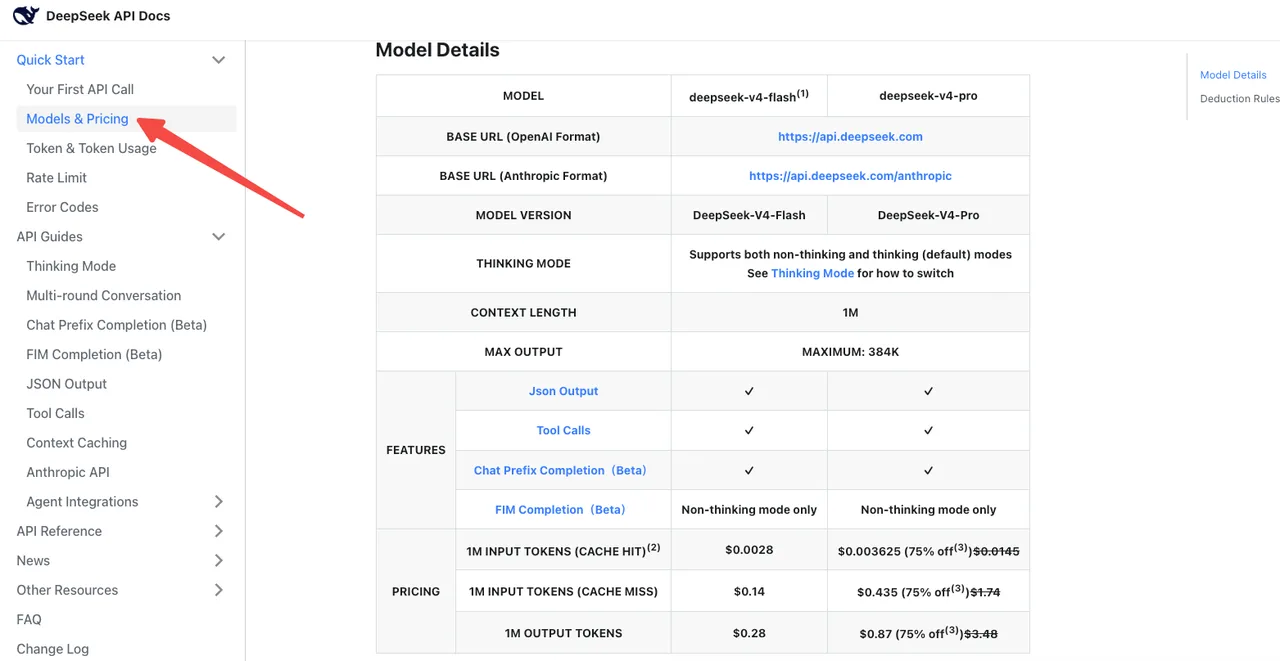
根據 DeepSeek 官方定價頁面,V4-Flash 標準費率為每 1M 輸入/輸出 token $0.14 / $0.28。V4-Pro 為 $1.74 / $3.48(目前打七五折至 2026/05/05)。快取命中定價已降至發布時價格的 1/10。
陷阱在於:V4-Pro 的思考模式消耗的輸出 token 比舊版 reasoner 多得多。Artificial Analysis 對 V4-Pro 的基準測試顯示其輸出量「非常冗長」,平均推理 token 數量約為過去的 4 倍。即使你的模型名稱修改看起來是中性的,帳單也可能飆升。
代理工作流程驗證
如果你運行多步驟代理,請重新測試完整鏈路。V4 的工具呼叫行為比 V3.x 更接近 Claude Code。有效的參數結構大多仍然可用,但模型在重試和自我修正方面更積極,這意味著有時每個任務的工具呼叫次數會增加——token 也會增加。
上線策略
功能旗標方法
不要做全域替換。為每個服務用設定旗標包裝模型名稱:
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")逐一服務上線。在繼續推進下一個之前,先監控每個服務的錯誤率和 p99 延遲 24-48 小時。
切換期間的影子流量
對於高流量服務,在短暫的時間視窗內同時將請求鏡像到新舊兩端。離線比較輸出結果。這是在使用者發現之前捕捉靜默品質回退的唯一方法。
常見遷移陷阱
以下是我上週實際觀察到的五個問題:
- 將
deepseek-reasoner替換為deepseek-v4-pro,卻沒有加上extra_body={"thinking": {"type": "enabled"}}。推理品質下降,但不會觸發任何錯誤。 - 對推理工作負載硬編碼
temperature=0並假設它仍然有效(在思考模式中它會被靜默忽略)。 - 忘記別名
deepseek-reasoner只對應到 V4-Flash,而非 V4-Pro。遷移到 Pro 是一次升級,而非同等替換。 - 沒有更新監控儀表板。如果你的儀表板按模型名稱分組,在你修正標籤之前,V4 的呼叫不會出現在你舊的 DeepSeek 圖表中。
- 忘記第三方整合。如果你透過 LiteLLM、OpenRouter 或任何閘道代理,OpenRouter 等提供商已經發布了 V4 路由——但你的閘道設定可能仍然固定在舊名稱上。
常見問題
如果我在 7 月 24 日前沒有完成遷移會怎樣?
2026 年 7 月 24 日 UTC 15:59 之後,使用 deepseek-chat 或 deepseek-reasoner 的請求將會失敗。官方公告指出兩個名稱將「完全停用且無法存取」。目前沒有宣布任何延期。
deepseek-v4-flash 是 deepseek-chat 的直接替代品嗎?
對於非思考工作負載,大致上是——相同的速度等級、相同的定價類別、相同的端點。由於底層權重不同,輸出會略有差異,所以請重新執行你的評估。對於思考工作負載,你需要明確加上 extra_body 思考參數。
如何保留 reasoner 的行為?
如果你想維持在相同的運算等級,請使用啟用了思考模式的 deepseek-v4-flash(這與 deepseek-reasoner 已經在做的事情相符)。如果你想獲得品質升級,請使用啟用了思考模式的 deepseek-v4-pro。兩者都需要 extra_body={"thinking": {"type": "enabled"}}。
我的計費結構會改變嗎?
按 token 計費的模式相同。費率有所不同——Flash 比舊版 deepseek-chat 費率更便宜,Pro 更貴但目前有折扣。快取命中定價現在為標準費率的 10%。請留意思考模式中輸出 token 膨脹的問題。
我可以同時測試新舊兩者嗎?
可以。在 7 月 24 日之前,舊版和新版模型名稱可以同時使用。使用功能旗標將一定比例的流量路由到 V4 並進行比較。這是風險最低的遷移路徑。
如果你明天就要上線,最安全的做法是最小的那個:先把 deepseek-chat → deepseek-v4-flash 換掉,把推理工作負載留到最後,在你用實際評估集對 V4-Pro 做過基準測試之前不要動它。截止日期是真實的,但距今還有三個月——有時間謹慎地完成這件事。在七月底被坑的團隊,都是那些把它當成一行 PR 來處理、跳過回歸測試的人。不要成為那樣的團隊。
相關文章:
