2026年GitHub Copilot数据训练政策
GitHub Copilot现在默认使用部分用户的交互数据进行模型训练。以下是变更内容以及开发者应验证的事项。

某个周一早晨,我打开了 Copilot 设置页面。那个开关已经在那里了,就在”隐私”一栏下面,等着我。“允许 GitHub 使用我的数据训练 AI 模型”。默认状态:已启用。
我叫 Dora。这不是一篇隐私抱怨文章。我不写那种东西。但 2026 年 4 月 24 日的这次变更,是那种悄然改写工具本质的供应商政策更新——这很重要,因为 Copilot 在很多工作流程中都承担着关键作用,包括我的。如果你用的是个人计划,并且还没有审查这次变更,你的交互数据已经被用作训练素材大约两周了。
这篇文章记录了变更了什么、影响了谁,以及在继续将 Copilot 视为既定选择之前,各团队应该审查哪些内容。我不是要你放弃它。我是要告诉你,这个问题变得更复杂了。
GitHub 在 2026 年 4 月 24 日做了哪些变更
3 月 25 日,GitHub 提前 30 天发出通知。4 月 24 日,新政策正式生效。简而言之:来自 Copilot Free、Pro 和 Pro+ 用户的交互数据,现在默认用于模型训练,除非用户主动选择退出。Business 和 Enterprise 版本不受影响。完整内容见 GitHub 官方政策公告。
此前这是选择加入的。现在变成了选择退出。这就是结构性变化。
哪些计划受到影响
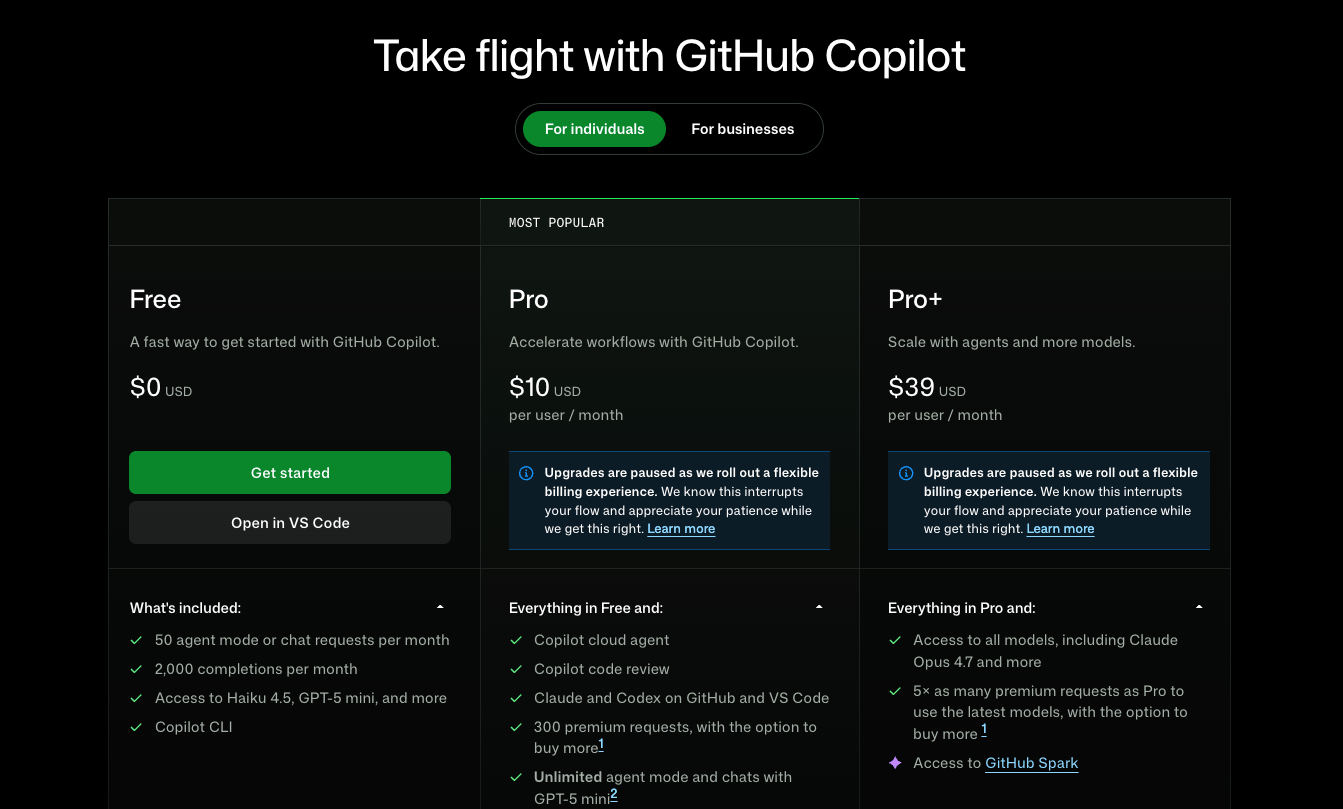
三个个人计划在范围之内:Copilot Free、Copilot Pro、Copilot Pro+。Business 和 Enterprise 被明确排除在外——GitHub 表示,对这些客户的合同承诺禁止将其交互数据用于训练,且这些承诺得到了履行。根据 GitHub 社区 FAQ,通过免费 Copilot Pro 访问的学生和教师也不受影响。
这种模式是可以识别的。企业合同获得更强的保障。个人付费用户——是的,包括个人计划顶端的 Pro+——得到的是选择退出版本。
哪些数据可能被用于训练
政策中使用了”交互数据”这个说法。它涵盖的内容比人们通常认为的要多:
- 你发送给 Copilot 的输入:提示词、聊天消息、光标周围的代码。
- Copilot 返回的输出:建议、补全、聊天回复。
- 会话期间生成的代码片段,包括在私有仓库中工作时生成的代码。
- 关联上下文:文件名、导航模式、接受/拒绝信号、点赞/点踩反馈。
GitHub 在更新的隐私声明和服务条款变更日志中划了一条清晰的界线:私有仓库中”静态存储”的内容不用于训练。但在该仓库中工作时产生的交互数据可以。措辞很关键。如果你把一个专有函数粘贴到 Copilot Chat 中寻求帮助,那个代码片段就是交互数据。仓库没有被训练,但那次会话被训练了。
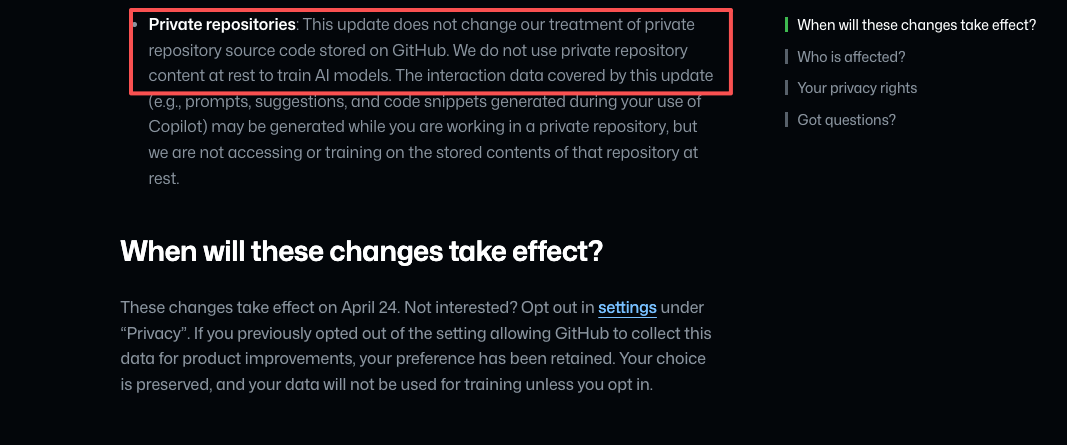
隐私声明新增的 J 节还扩大了与关联公司的数据共享范围,其中包括 Microsoft。不是第三方模型提供商——仅限关联公司。这比最坏的解读范围要小,但比”GitHub 内部保留”要宽。
我在这里停顿了一下。“静态存储”的区分在技术上是准确的,在实践中却很滑头。这是采购审查人员需要读两遍的那种条款。
为什么这对开发者和团队很重要
信任、隐私与工作流风险
4 月 24 日的变更不是隐私丑闻。它是供应商风险的重新分类。
我认识的大多数团队,在”个人 Copilot 账户”和”我为客户或雇主工作的代码”之间没有清晰的分隔。界限是模糊的。一个副业项目。一道带回家的面试题。一段从技术上不属于你的仓库中粘贴到 Copilot Chat 的代码片段。上个月这些都不是数据治理问题。从 4 月 24 日起,在个人计划上,它们都是了。
还有一个在政策文本中看不到的信誉问题。选择退出的开关是存在的。默认值做了选择。“你有控制权”和”你必须知道如何使用它”之间的差距,正是 GitLab 在其关于这次变更的博文中所称的治理警醒。他们是竞争对手。但这个描述仍然准确。
个人与 Business/Enterprise 的影响差异
这是团队反复搞错的部分,所以我会慢慢说清楚。
如果你的团队使用 Copilot Business 或 Copilot Enterprise——通过组织购买、按组织计费、由管理员管理——新的训练政策不适用于你们。你们的交互数据不用于训练。那个合同边界在 4 月 24 日之前成立,现在仍然成立。
如果你的团队中有人在工作机器上、对工作代码、针对工作仓库使用个人 Copilot Pro 或 Pro+ 账户,这就是风险所在。计划级别跟着账户走,而不是跟着代码走。企业代码库上的个人账户,会将该代码库的交互数据纳入训练范围,除非该用户已经选择退出。
一些大学很快意识到了这一点。例如,华盛顿州立大学现在明确禁止在机构代码上使用个人 Copilot Free、Pro 或 Pro+ 计划,除非禁用了训练功能并获得书面批准。这是一个合理的政策模板。大多数公司还没有制定相应政策。
这才是真正需要下功夫的地方。
继续使用 Copilot 之前,开发者应该审查什么
以下是我为自己的设置逐一检查的清单。请根据你的团队情况调整。
- 审查每位开发者实际使用的是哪个 Copilot 计划。 不是公司付费的那个——而是每位开发者机器上登录的那个。工作代码上的个人账户是失败模式。
- 确认每个接触不想被训练的代码的个人账户的退出状态。 该设置位于 Copilot 个人设置的”隐私”下,参见 GitHub 针对个人订阅者的官方文档。将”允许 GitHub 使用我的数据训练 AI 模型”切换为禁用。重新加载页面并验证设置已保存。
- 更新你的 AI 工具政策,明确指定计划级别。 “已批准:Copilot Business 或 Enterprise”是一个与”已批准:GitHub Copilot”不同的政策。前者能经受住 4 月 24 日的考验,后者不能。
- 决定你对敏感代码路径的标准是什么。 一些团队可以接受 Copilot Business。一些团队希望在任何计划下都不进行训练,这意味着需要不同的供应商或不同的部署模式。这是一个判断决策,不是默认值。
- 在下次供应商审查周期时重新评估,而不是本周惊慌失措。 这次变更是真实的,但它是政策调整,而不是数据泄露。将其视为下次 AI 供应商审查的输入,而不是紧急迁移的信号。
工作流中少一个意外。听起来很小。积累起来很快。
常见问题

哪些 GitHub Copilot 计划受到影响?
Copilot Free、Copilot Pro 和 Copilot Pro+——三个个人计划。Copilot Business 和 Copilot Enterprise 不受影响。通过 GitHub Education 免费使用 Copilot Pro 的学生和教师也不受影响。
用户可以选择退出训练吗?
可以。 点击你的头像,打开 Copilot 设置,在”隐私”下找到”允许 GitHub 使用我的数据训练 AI 模型”,将其设置为禁用。退出适用于整个账户——没有按仓库控制的选项。如果你之前已经禁用了旧版”提示词和建议收集”设置,你的偏好设置已自动延续,无需操作。
Business 和 Enterprise 账户是否被排除在外?
是的,通过合同约定。 GitHub 与 Business 和 Enterprise 客户的协议禁止将其交互数据用于模型训练,4 月 24 日的更新不改变这一点。请注意,这仅适用于你使用 Business 或 Enterprise 许可登录的情况——而不是恰好属于 Business 客户员工的个人账户。
团队现在应该审查其内部政策的哪些方面?
三件事。 每位开发者在接触你的代码时实际使用的是哪个计划级别。你的书面 AI 政策是否指定了计划级别(还是只写了产品名称)。敏感代码库是否需要比”Business 即可”更严格的标准——对于一些团队来说答案是肯定的,这是一个单独的供应商讨论。
结语
4 月 24 日的变更没有让 Copilot 在编写代码方面变差。它让”Copilot 对于这个代码库来说是安全的供应商吗?“这个问题的答案,以两周前不存在的方式依赖于计划级别、账户类型和个人退出状态。
对于做副业项目的独立开发者来说,选择退出只需拨动一个开关,对话就此结束。对于交付生产代码的团队来说,对话更长——而且应该在有人注意到个人 Pro+ 账户登录在敏感仓库上之前就进行。
我仍在使用 Copilot。我用的是 Business 版本。边界目前还在。我的数据止步于此。其余的,你需要自己去验证。
更多内容即将发布。
往期文章:




