DeepSeek V4 API迁移:请在7月前更新模型名称
DeepSeek-chat与deepseek-reasoner将于2026年7月24日停止服务。附代码差异对比,手把手指导迁移至deepseek-v4-pro与deepseek-v4-flash。

周一早上我查看了生产日志,发现仍有 14,000 次调用在使用 deepseek-chat。三个月后,这些调用每一次都会返回 404。这就是很多团队在毫不知情的情况下正在走入的处境——DeepSeek 发布了弃用公告,日历一页页翻过,但值班轮换表上没有人把变更日志转发给真正负责集成的人。我上周在我们自己的技术栈上跑完了迁移,所以这篇文章里给的是真实有效的 diff,而不是对公告的转述。我叫 Dora,为后端团队写基础设施笔记。简短版本是:代码改动就一行,但如果跳过测试环节,一切都会出问题。
已在使用 DeepSeek? 无需修改代码即可切换到 WaveSpeedAI——同样的 OpenAI SDK,只需更换 base URL 和密钥。DeepSeek V3.2 API → · DeepSeek R1 API →
截止日期是 2026 年 7 月 24 日 UTC 15:59。此后,deepseek-chat 和 deepseek-reasoner 将返回错误。目前没有任何延期讨论。现在开始迁移,5 月完成测试,6 月处理收尾工作。
变更内容与时间节点
弃用时间线:deepseek-chat / deepseek-reasoner 将于 2026-07-24 下线
DeepSeek V4 于 2026 年 4 月 24 日发布,官方 DeepSeek V4 发布说明指出两个旧模型名称将在 2026 年 7 月 24 日 UTC 15:59 后”完全退役且无法访问”。这是硬截止,不是软性警告。使用旧名称的请求在该时间戳之后将全部失败。
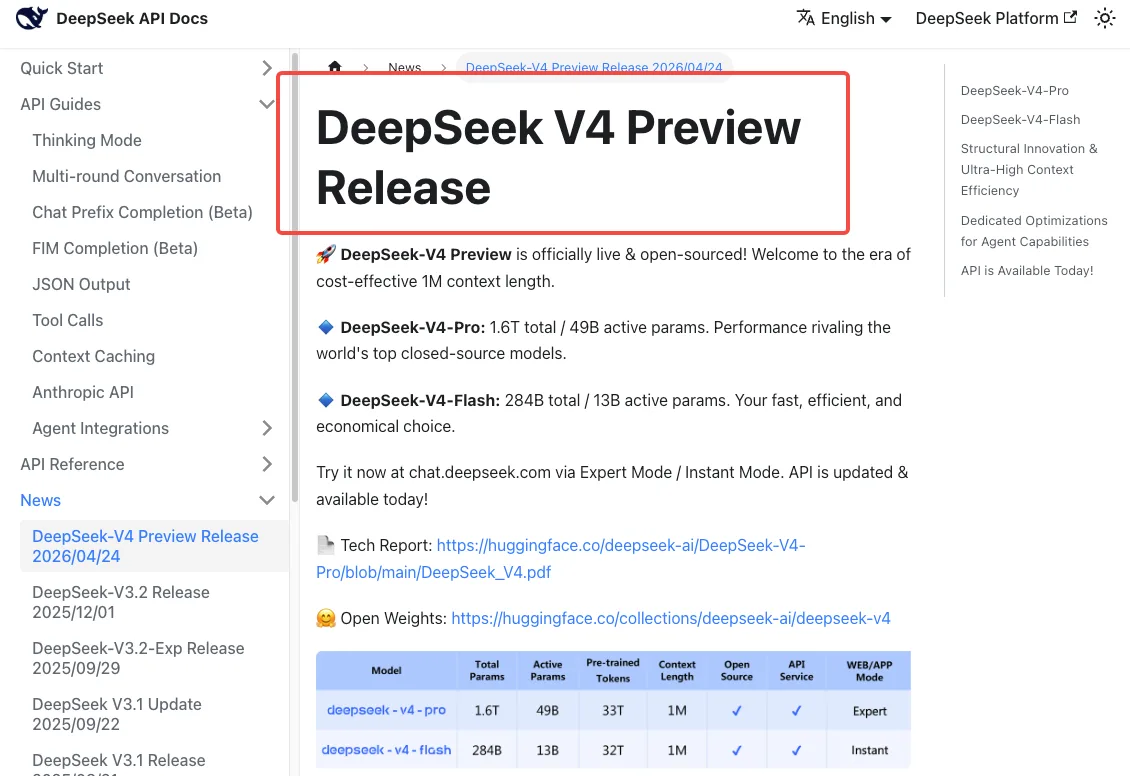
在过渡期内——从现在到 7 月 24 日——两个旧名称继续可用,但会被透明路由到 V4-Flash。因此,无论你是否更新了代码,你实际上已经在使用 V4 了。
新模型名称:deepseek-v4-pro、deepseek-v4-flash
两个新模型 ID 替代了旧的别名:
deepseek-v4-pro— 总参数 1.6T,活跃参数 49B,上下文窗口 1M,最大输出 384K。适合推理密集型场景。deepseek-v4-flash— 总参数 284B,活跃参数 13B,同样支持 1M 上下文。更便宜更快,适合大多数生产工作负载。
两者都通过同一个模型 ID 支持思考模式和非思考模式。你不再需要选择不同的模型来启用推理——而是通过参数切换。这正是粗心迁移会出问题的地方。
过渡期内的兼容映射
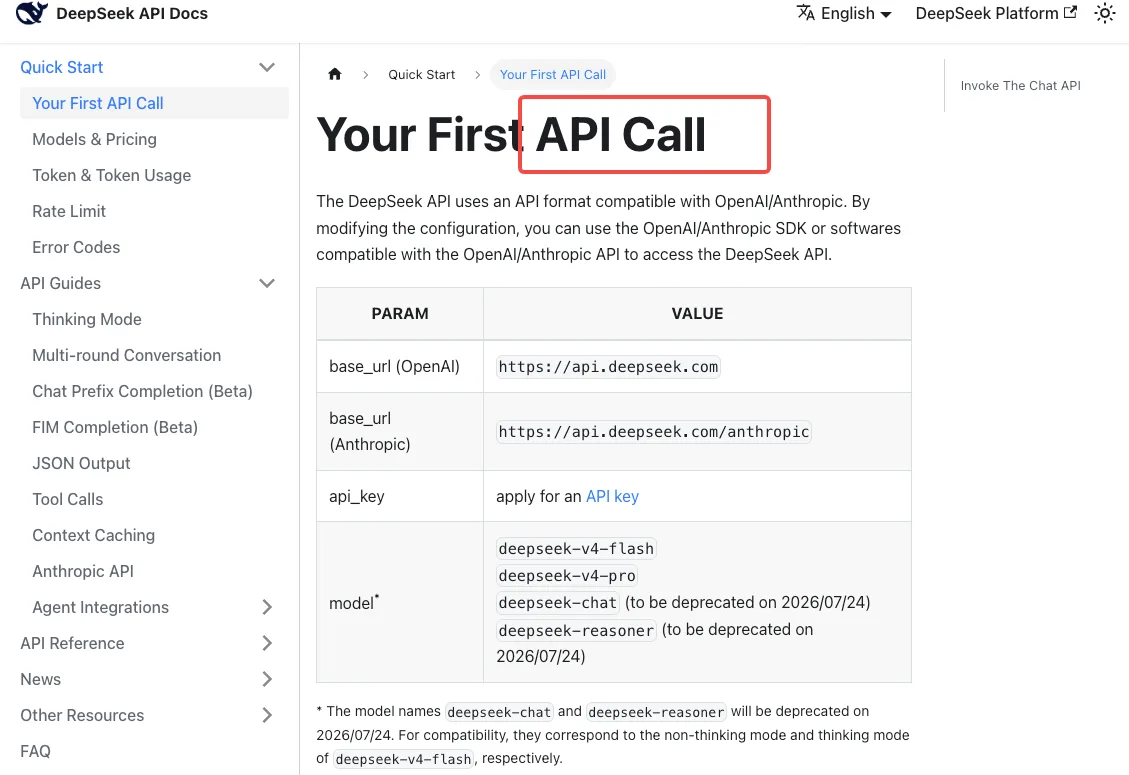
根据 DeepSeek API 快速入门文档,当前的兼容映射关系如下:
deepseek-chat→deepseek-v4-flash(非思考模式)deepseek-reasoner→deepseek-v4-flash(思考模式)
注意这意味着什么:如果你之前使用的是 deepseek-reasoner,你现在实际上运行的是 Flash,而不是 Pro。如果你上周感觉推理工作负载表现有些不同,这就是原因。要获得 Pro 级推理,你必须明确迁移到 deepseek-v4-pro——别名永远不会把你指向那里。
迁移前检查清单
清点所有访问 DeepSeek API 的服务
在整个代码仓库中执行 grep。两个字符串都要查:
grep -rn "deepseek-chat\|deepseek-reasoner" .不要凭记忆判断哪些服务在使用它。我找到了两个我已经忘记存在的定时任务和一个 webhook 处理器。同时检查 .env 模板、部署配置、IaC 文件,以及任何 LLM 网关路由表。如果你使用了 LiteLLM 或 n1n.ai 这样的代理,也要检查那里——api-docs.deepseek.com 上的 DeepSeek 变更日志确认旧名称计划完全停用,而不仅仅是弃用警告,因此仍在使用旧名称的任何东西都会硬失败。
记录当前延迟和质量基线
在修改任何一行代码之前,先快照”正常运行”的当前状态:
- 每个端点的 p50 / p95 / p99 延迟
- 输出 token 分布(均值、标准差)
- 如果有评估集,记录质量分数
- 每个服务的每日费用
V4-Flash 的行为与 deepseek-chat 之前指向的 V3.x 权重略有不同。你需要一个基线,以便在切换后判断发生了什么变化。
识别隐式使用思考模式的地方(reasoner)
每个使用 deepseek-reasoner 的服务都在默默享受思考模式。迁移后,思考模式需要通过参数显式开启。如果你忘记添加,你会悄无声息地失去推理能力,输出质量下降但没有任何报错。这是最常见的迁移 bug。
所需代码变更
模型名称替换(前后对比示例)
对于不需要思考模式的服务:
python
# 之前
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# 之后
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)对于需要推理的服务,变更幅度更大。
在原 reasoner 场景中添加 reasoning_effort
DeepSeek 思考模式文档指定通过 extra_body 启用思考模式,并通过 reasoning_effort 进行调节:
python
# 之前
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# 之后
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)几点需要注意:
reasoning_effort接受high和max。根据文档,low和medium会被映射到high,xhigh会被映射到max。思考模式请求的默认值是high。- 思考模式会静默忽略
temperature、top_p、presence_penalty和frequency_penalty。 设置它们不会报错——只是不会生效。如果你的旧 reasoner 配置依赖temperature=0.7,那本来就已经被忽略了。
Base URL 和认证——不变
这部分真的很简单。https://api.deepseek.com 保持不变。你的 API 密钥保持不变。OpenAI ChatCompletions 和 Anthropic SDK 格式都受支持,所以你现有的客户端配置继续有效。只有 model 字符串和(对于推理场景)extra_body 需要改变。
回归测试
你应该预期的输出差异
V4-Flash 是一个与 deepseek-chat 之前路由到的 V3.2 权重不同的模型。预期会有:
- 输出详细程度略有不同——在相同提示下 V4 倾向于产生更长的输出
- 代码块和列表的格式选择不同
- 在 agentic 任务上的指令遵循能力更强
- 分词器属于同一系列,但 token 数量可能有所变化
跑一遍你的评估集。不要假设”兼容”就意味着”完全相同”。
重新核对成本基线
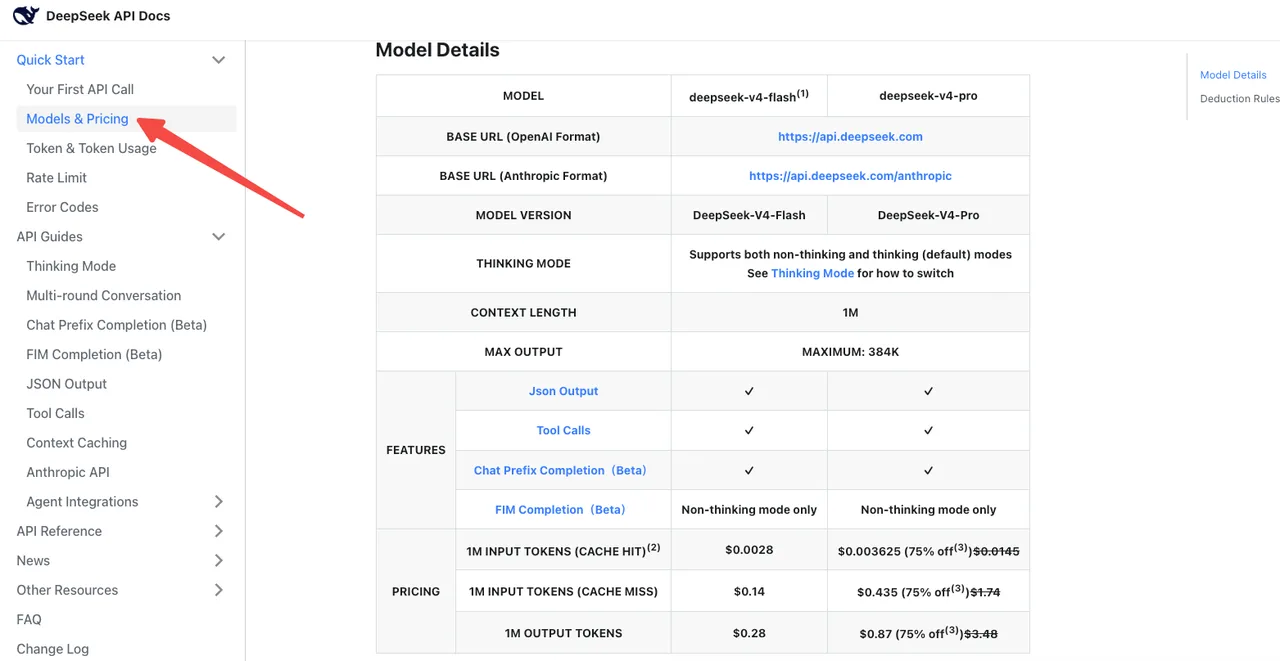
根据官方 DeepSeek 定价页面,V4-Flash 标准费率为每百万输入/输出 token $0.14 / $0.28。V4-Pro 为 $1.74 / $3.48(目前享受 75% 折扣至 2026/05/05)。缓存命中定价已降至发布价格的 1/10。
陷阱在于:V4-Pro 上的思考模式消耗的输出 token 远多于旧的 reasoner。Artificial Analysis 测评 V4-Pro 输出量”非常冗长”,产生的平均推理 token 数约为原来的 4 倍。即使你的模型名称变更看起来中性,账单也可能上涨。
Agent 工作流验证
如果你运行多步骤 agent,请重新测试完整链路。V4 的工具调用行为比 V3.x 更接近 Claude Code。参数 schema 基本上都能正常工作,但模型在重试和自我纠正方面更为积极,这意味着有时每个任务会有更多工具调用——以及更多 token。
发布策略
特性开关方案
不要做全局替换。将每个服务的模型名称封装在配置开关中:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")逐个服务发布。在推进下一个服务之前,观察每个服务 24-48 小时的错误率和 p99 延迟。
切换期间的影子流量
对于高流量服务,在短暂的窗口期内将请求同时镜像到新旧两个版本。离线比较输出。这是在用户发现之前捕获静默质量回归的唯一方法。
常见迁移陷阱
以下是我上周实际遇到的五个:
- 将
deepseek-reasoner替换为deepseek-v4-pro但没有添加extra_body={"thinking": {"type": "enabled"}}。推理质量下降,没有任何报错。 - 为推理工作负载硬编码
temperature=0并假设它仍然生效(在思考模式下会被静默忽略)。 - 忘记别名
deepseek-reasoner只映射到 V4-Flash,而不是 V4-Pro。迁移到 Pro 是一次升级,不是同类替换。 - 没有更新监控仪表盘。如果你的仪表盘按模型名称分组,V4 的调用在你修复标签之前不会出现在旧的 DeepSeek 面板下。
- 忘记第三方集成。如果你通过 LiteLLM、OpenRouter 或任何网关代理,OpenRouter 等提供商已经发布了 V4 路由——但你的网关配置可能仍然固定在旧名称上。
常见问题
如果我没在 7 月 24 日前完成迁移会怎样?
2026 年 7 月 24 日 UTC 15:59 之后,使用 deepseek-chat 或 deepseek-reasoner 的请求将全部失败。官方通知明确表示两个名称将”完全退役且无法访问”。目前没有任何延期公告。
deepseek-v4-flash 可以直接替换 deepseek-chat 吗?
对于非思考工作负载,基本上可以——速度级别相同,定价类别相同,端点相同。由于底层权重不同,输出会有轻微差异,因此需要重新跑评估。对于思考工作负载,你需要显式添加 extra_body 思考参数。
如何保留 reasoner 的行为?
如果想保持在同等计算层级(这与 deepseek-reasoner 之前实际做的一致),使用启用了思考模式的 deepseek-v4-flash。如果想要质量升级,使用启用了思考模式的 deepseek-v4-pro。两者都需要 extra_body={"thinking": {"type": "enabled"}}。
我的计费结构会改变吗?
按 token 计费模式不变。费率有所不同——Flash 比旧的 deepseek-chat 费率更便宜,Pro 更贵但目前有折扣。缓存命中定价现在是标准费率的 10%。注意思考模式下的输出 token 膨胀。
我可以同时测试新旧版本吗?
可以。两个旧名称和新名称在 7 月 24 日之前同时有效。使用特性开关将一定比例的流量路由到 V4 并进行比较。这是风险最低的迁移路径。
如果你明天要发布到生产环境,最安全的做法是最小改动:先将 deepseek-chat 替换为 deepseek-v4-flash,把推理工作负载留到最后,在你针对实际评估集完成基准测试之前不要动 V4-Pro。截止日期是真实的,但也还有三个月——有时间仔细做这件事。7 月下旬被坑的团队,都是那些把它当成一行 PR 处理、跳过回归测试的团队。不要成为那样的团队。
往期文章:
