Миграция API DeepSeek V4: обновите названия моделей до июля
DeepSeek-chat и deepseek-reasoner прекращают работу 24 июля 2026 года. Пошаговая миграция на deepseek-v4-pro и deepseek-v4-flash с примерами изменений кода.

В понедельник утром я поднял продакшн-логи и насчитал 14 000 запросов, всё ещё обращающихся к deepseek-chat. Через три месяца каждый из них вернёт 404. Вот в какой ситуации оказываются многие команды, даже не подозревая об этом — DeepSeek объявил о деприкации, календарь двинулся, а никто из дежурной смены не переслал лог изменений людям, которые реально владеют интеграцией. Я провёл миграцию на нашем собственном стеке на прошлой неделе, так что это версия с диффами, которые сработали, а не пересказ объявления. Меня зовут Дора, я пишу инфраструктурные заметки для backend-команд, и если коротко: это однострочное изменение в коде, но всё ломается именно в тестировании вокруг него — если его пропустить.
Уже используете DeepSeek? Переключитесь на WaveSpeedAI без изменений в коде — тот же OpenAI SDK, просто смените base URL и ключ. DeepSeek V3.2 API → · DeepSeek R1 API →
Жёсткая дата — 24 июля 2026 года, 15:59 UTC. После этого deepseek-chat и deepseek-reasoner начнут возвращать ошибки. Никакого продления не обсуждается. Мигрируйте сейчас, заканчивайте тестирование в мае, оставьте июнь для отстающих.
Что меняется и когда
Сроки деприкации: deepseek-chat / deepseek-reasoner прекращают работу 2026-07-24
DeepSeek V4 вышел 24 апреля 2026 года, и в официальных примечаниях к релизу DeepSeek V4 сказано, что оба устаревших названия моделей будут «полностью выведены из эксплуатации и недоступны» после 24 июля 2026 года, 15:59 UTC. Это жёсткий дедлайн, а не мягкое предупреждение. Запросы с использованием старых названий после этой временной метки будут завершаться ошибкой.
В период льготного времени — с сейчас по 24 июля — оба устаревших названия продолжают работать, но прозрачно маршрутизируются на V4-Flash. Так что вы уже работаете на V4, независимо от того, обновили ли вы код или нет.
Новые названия моделей: deepseek-v4-pro, deepseek-v4-flash
Два новых идентификатора моделей заменяют старые алиасы:
deepseek-v4-pro— 1,6T параметров всего, 49B активных, контекстное окно 1M, максимальный вывод 384K. Вариант с акцентом на рассуждения.deepseek-v4-flash— 284B всего, 13B активных, те же 1M контекста. Дешевле и быстрее, подходит для большинства продакшн-задач.
Оба поддерживают режимы с рассуждениями и без через один и тот же идентификатор модели. Вы больше не выбираете рассуждение, выбирая отдельную модель — вы переключаете его через параметры. Именно здесь ломаются наивные миграции.
Переходное сопоставление в период льготного времени
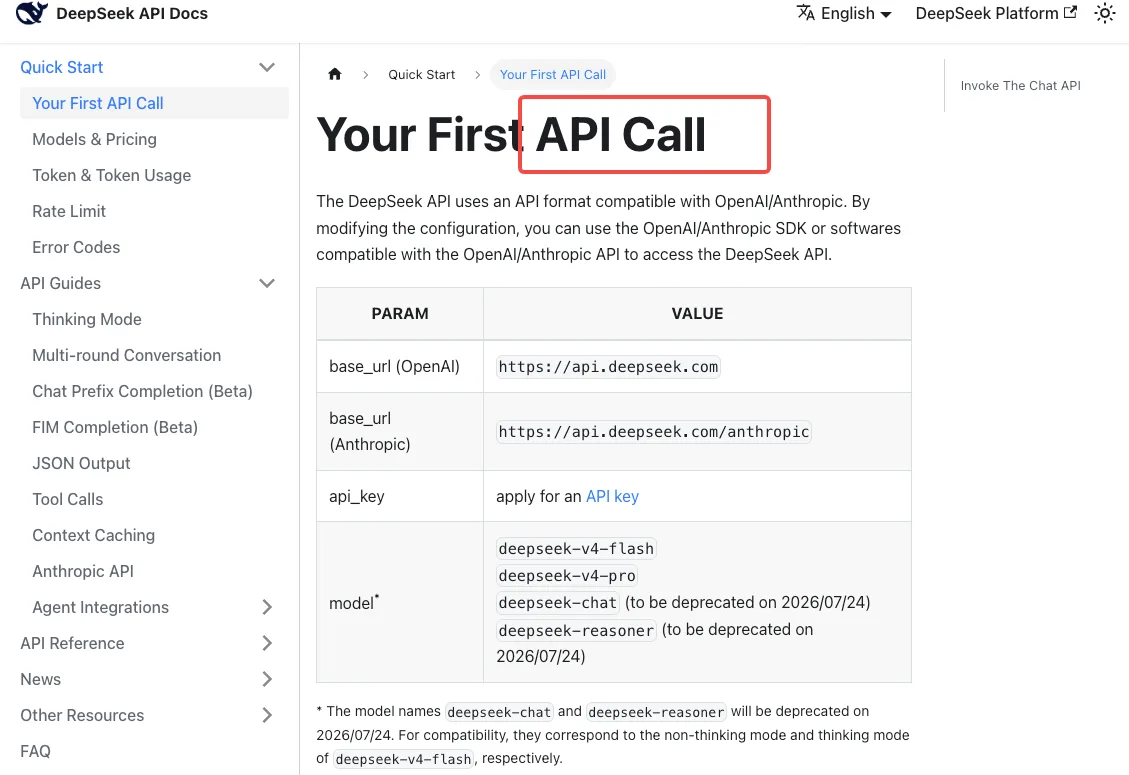
Согласно документации DeepSeek API quickstart, текущее сопоставление совместимости выглядит так:
deepseek-chat→deepseek-v4-flash(режим без рассуждений)deepseek-reasoner→deepseek-v4-flash(режим с рассуждениями)
Обратите внимание на то, что это означает: если вы использовали deepseek-reasoner, вы уже работаете на Flash, а не на Pro. Если ваши рабочие нагрузки с рассуждениями ощущались немного иначе на прошлой неделе — вот почему. Чтобы получить рассуждения уровня Pro, необходимо явно мигрировать на deepseek-v4-pro — алиас никогда не направит вас туда.
Чеклист перед миграцией
Проинвентаризируйте каждый сервис, обращающийся к DeepSeek API
Сделайте grep по всему монорепозиторию. Обе строки:
grep -rn "deepseek-chat\|deepseek-reasoner" .Не доверяйте своей памяти о том, какие сервисы его используют. Я обнаружил два cron-задания и обработчик webhook, о существовании которых забыл. Также проверьте шаблоны .env, конфиги деплоя, IaC-файлы и любые таблицы маршрутизации LLM-шлюзов. Если вы используете прокси вроде LiteLLM или n1n.ai, проверьте там тоже — журнал изменений DeepSeek на api-docs.deepseek.com подтверждает, что старые названия запланированы к полному прекращению, а не просто к предупреждениям о деприкации, так что всё, что их использует, будет жёстко падать.
Снимите базовые показатели текущей задержки и качества
Прежде чем изменить хоть одну стр оку, зафиксируйте, как выглядит «рабочее состояние» сегодня:
оку, зафиксируйте, как выглядит «рабочее состояние» сегодня:
- Задержка p50 / p95 / p99 на каждый эндпоинт
- Распределение выходных токенов (среднее, стандартное отклонение)
- Оценка качества на вашем eval-наборе, если он есть
- Ежедневные затраты на сервис
V4-Flash — это другая модель по сравнению с весами V3.x, на которые раньше указывал deepseek-chat. Вам нужен базовый показатель, чтобы понять, что изменилось после замены.
Определите, где режим рассуждений был неявным (reasoner)
Каждый сервис, использующий deepseek-reasoner, получал режим рассуждений бесплатно. После миграции режим рассуждений включается опционально через параметр. Если вы забудете его добавить, вы незаметно лишитесь возможности рассуждения, и качество выводов ухудшится без каких-либо ошибок. Это самая распространённая ошибка при миграции.
Необходимые изменения в коде
Замена названия модели (примеры до/после)
Для сервисов, которым не нужен режим рассуждений:
python
# До
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# После
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Для сервисов, которым нужны рассуждения, изменение масштабнее.
Добавление reasoning_effort там, где использовался reasoner
Документация DeepSeek по режиму рассуждений указывает, что рассуждения включаются через extra_body и настраиваются с помощью reasoning_effort:
python
# До
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# После
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Несколько вещей, на которые стоит обратить внимание:
reasoning_effortпринимает значенияhighиmax. Согласно документации,lowиmediumсопоставляются сhigh, аxhigh— сmax. По умолчанию для запросов в режиме рассуждений используетсяhigh.- Режим рассуждений молча игнорирует
temperature,top_p,presence_penaltyиfrequency_penalty. Их установка не вызовет ошибки — просто не даст никакого эффекта. Если ваша старая настройка reasoner зависела отtemperature=0.7, это уже игнорировалось.
Base URL и авторизация — без изменений
Эта часть действительно простая. https://api.deepseek.com остаётся прежним. Ваш API-ключ остаётся прежним. Поддерживаются оба формата — OpenAI ChatCompletions и Anthropic SDK, так что существующая настройка клиента продолжает работать. Меняется только строка model и (для рассуждений) extra_body.
Регрессионное тестирование
Отличия в форме вывода, которых следует ожидать
V4-Flash — это другая модель по сравнению с весами V3.2, на которые раньше маршрутизировался deepseek-chat. Ожидайте:
- Немного другую многословность — V4 склонен генерировать более длинные выводы при том же промпте
- Другие форматы для блоков кода и списков
- Лучшее следование инструкциям в агентных задачах
- Токенизатор из того же семейства, но количество токенов может сдвигаться
Прогоните свой eval-набор. Не предполагайте, что «совместимо» означает «идентично».
Повторная проверка базовых затрат
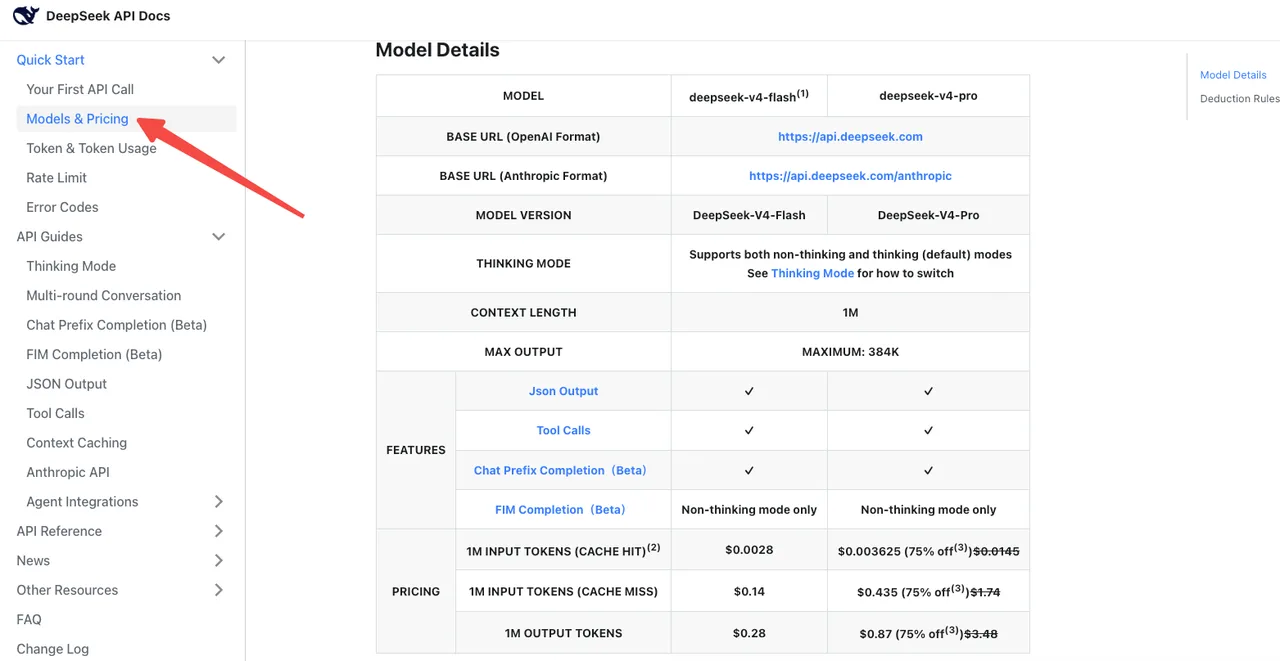
Согласно официальной странице цен DeepSeek, V4-Flash стоит $0,14 / $0,28 за 1M входных/выходных токенов по стандартным тарифам. V4-Pro — $1,74 / $3,48 (сейчас скидка 75% до 05.05.2026). Цены при попадании в кэш снижены до 1/10 от цены на момент запуска по всей линейке.
Ловушка: режим рассуждений на V4-Pro сжигает значительно больше выходных токенов, чем старый reasoner. Artificial Analysis оценил V4-Pro как генерирующий «очень объёмные» выводы, производя примерно в 4 раза больше среднего количества токенов рассуждений. Ваш счёт может вырасти, даже если изменение названия модели выглядит нейтральным.
Валидация агентных рабочих процессов
Если вы запускаете многошаговых агентов, перетестируйте всю цепочку. Поведение V4 при вызове инструментов ближе к Claude Code, чем было у V3.x. Схемы аргументов, которые работали, в основном в порядке, но модель более агрессивно повторяет попытки и самокорректируется, что иногда означает больше вызовов инструментов на задачу — и больше токенов.
Стратегия развёртывания
Подход с feature-флагом
Не делайте глобальную замену. Оберните название модели в config-флаг для каждого сервиса:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Разворачивайте сервис за сервисом. Следите за частотой ошибок и задержкой p99 в течение 24–48 часов на сервис, прежде чем двигаться дальше.
Теневой трафик во время переключения
Для высоконагруженных сервисов зеркалируйте запросы на старый и новый варианты в течение короткого периода. Сравнивайте выводы оффлайн. Это единственный способ поймать незаметные регрессии качества до того, как это заметят пользователи.
Распространённые ошибки при миграции
Пять, которые я реально видел на прошлой неделе:
- Замена
deepseek-reasoner→deepseek-v4-proбез добавленияextra_body={"thinking": {"type": "enabled"}}. Качество рассуждений падает, ошибки не возникают. - Жёсткое кодирование
temperature=0для рабочих нагрузок с рассуждениями в предположении, что это всё ещё работает (в режиме рассуждений молча игнорируется). - Забывают, что алиас
deepseek-reasonerсопоставлялся только с V4-Flash, а не с V4-Pro. Миграция на Pro — это апгрейд, а не равнозначная замена. - Не обновляются дашборды мониторинга. Если ваш дашборд группирует по названию модели, вызовы V4 не появятся под вашей старой плиткой DeepSeek, пока вы не исправите метку.
- Забывают о сторонних интеграциях. Если вы проксируете через LiteLLM, OpenRouter или любой шлюз, провайдеры вроде OpenRouter уже опубликовали маршруты V4 — но конфиг вашего шлюза может всё ещё закреплять старое название.
Часто задаваемые вопросы
Что произойдёт, если я не мигрирую до 24 июля?
После 24 июля 2026 года, 15:59 UTC, запросы с использованием deepseek-chat или deepseek-reasoner будут завершаться ошибкой. В официальном уведомлении сказано, что оба названия будут «полностью выведены из эксплуатации и недоступны». Никакого объявленного продления нет.
Является ли deepseek-v4-flash прямой заменой deepseek-chat?
Для рабочих нагрузок без рассуждений — в основном да: тот же скоростной уровень, тот же ценовой класс, тот же эндпоинт. Выводы немного отличаются, потому что базовые веса разные, так что перезапустите ваши eval-тесты. Для рабочих нагрузок с рассуждениями необходимо явно добавить параметр extra_body thinking.
Как сохранить поведение reasoner?
Используйте deepseek-v4-flash с включённым режимом рассуждений, если хотите остаться на том же вычислительном уровне (это соответствует тому, что уже делал deepseek-reasoner). Используйте deepseek-v4-pro с включёнными рассуждениями, если хотите улучшить качество. Оба требуют extra_body={"thinking": {"type": "enabled"}}.
Изменится ли моя структура выставления счетов?
Модель поштучной оплаты та же. Тарифы отличаются — Flash дешевле старых тарифов deepseek-chat, Pro дороже, но сейчас со скидкой. Цены при попадании в кэш теперь составляют 10% от стандартных. Следите за раздуванием выходных токенов в режиме рассуждений.
Могу ли я тестировать старый и новый варианты параллельно?
Да. Оба — устаревшие и новые — названия моделей работают одновременно до 24 июля. Используйте feature-флаг для маршрутизации процента трафика на V4 и сравнивайте. Это наименее рискованный путь миграции.
Если вы деплоите в продакшн завтра, самый безопасный ход — самый маленький: сначала замените deepseek-chat → deepseek-v4-flash, оставьте рабочие нагрузки с рассуждениями напоследок, и не трогайте V4-Pro, пока не проведёте бенчмарк против вашего реального eval-набора. Дедлайн реален, но он ещё через три месяца — есть время сделать это аккуратно. Команды, которых подловят в конце июля, будут теми, кто отнёсся к этому как к однострочному PR и пропустил регрессионный проход. Не будьте такими командами.
Предыдущие посты:
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение
GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене
Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов
MAI-Image-2.5 API: что нужно знать разработчикам