Migração da API DeepSeek V4: Atualize os Nomes dos Modelos Antes de Julho
DeepSeek-chat e deepseek-reasoner serão descontinuados em 24 de julho de 2026. Migração passo a passo para deepseek-v4-pro e deepseek-v4-flash com diffs de código.

Puxei os logs de produção numa segunda-feira de manhã e contei 14.000 chamadas ainda atingindo deepseek-chat. Daqui a três meses, cada uma delas retorna um 404. Essa é a situação em que muitas equipes estão entrando sem saber — o DeepSeek anunciou a descontinuação, o calendário avançou, e ninguém no plantão repassou o changelog para as pessoas que realmente mantêm a integração. Rodei a migração na nossa própria stack semana passada, então esta é a versão com os diffs que funcionaram, não a que parafraseia o anúncio. Meu nome é Dora, escrevo notas de infraestrutura para equipes de backend, e a versão curta é: é uma mudança de uma linha no código, mas os testes em torno dela são onde tudo dá errado se você pular.
Já usa DeepSeek? Mude para WaveSpeedAI sem alterações no código — mesmo OpenAI SDK, basta mudar a URL base e a chave. DeepSeek V3.2 API → · DeepSeek R1 API →
A data limite é 24 de julho de 2026, 15:59 UTC. Após isso, deepseek-chat e deepseek-reasoner retornam erros. Não há extensão sendo discutida. Migre agora, termine os testes em maio, deixe junho para os retardatários.
O Que Muda e Quando
Cronograma de descontinuação: sunset de deepseek-chat / deepseek-reasoner em 2026-07-24
O DeepSeek V4 foi lançado em 24 de abril de 2026, e as notas oficiais de lançamento do DeepSeek V4 afirmam que ambos os nomes de modelos legados serão “totalmente desativados e inacessíveis” após 24 de julho de 2026, 15:59 UTC. É um corte definitivo, não um aviso suave. Requisições usando os nomes antigos após esse timestamp falham.
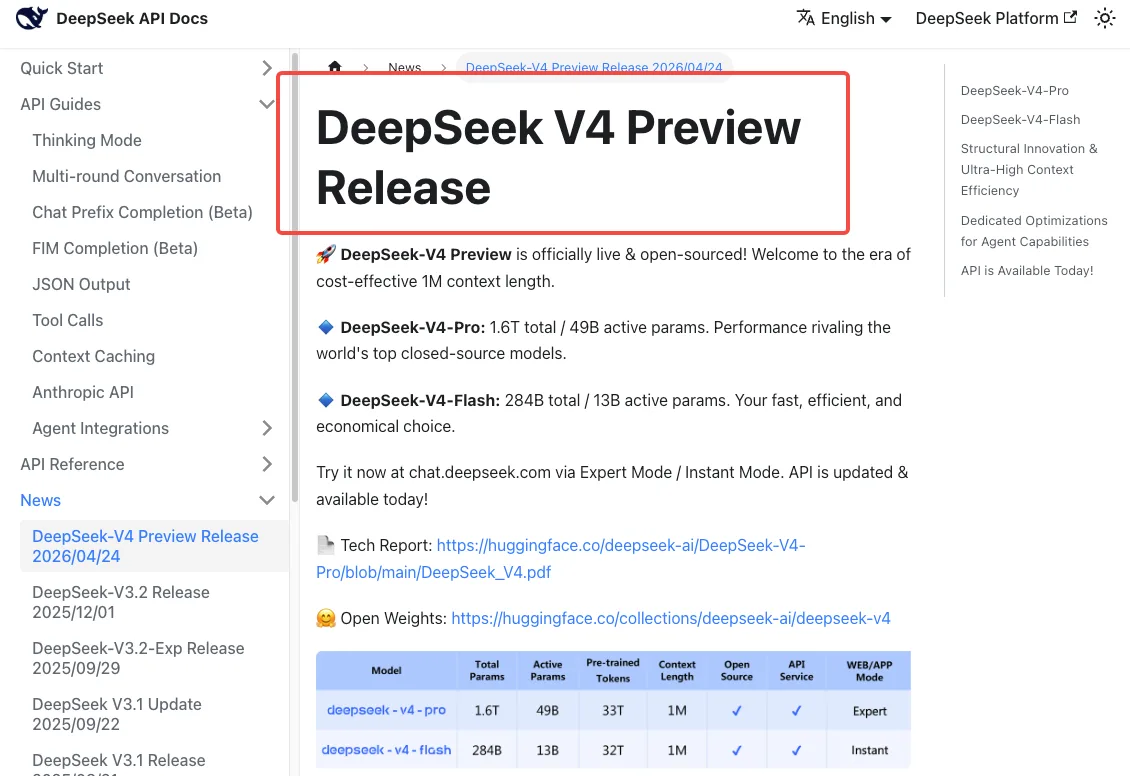
Durante o período de carência — agora até 24 de julho — ambos os nomes legados continuam funcionando, mas são roteados de forma transparente para o V4-Flash. Então você já está no V4, quer tenha atualizado seu código ou não.
Novos nomes de modelos: deepseek-v4-pro, deepseek-v4-flash
Dois novos IDs de modelo substituem os aliases antigos:
deepseek-v4-pro— 1,6T de parâmetros totais, 49B ativos, janela de contexto de 1M, saída máxima de 384K. A opção com foco em raciocínio.deepseek-v4-flash— 284B totais, 13B ativos, mesmo 1M de contexto. Mais barato e rápido, adequado para a maioria das cargas de trabalho em produção.
Ambos suportam modos de pensamento e não-pensamento através do mesmo ID de modelo. Você não escolhe mais o raciocínio selecionando um modelo separado — você o ativa via parâmetros. Esta é a parte que quebra migrações ingênuas.
Mapeamento transitório durante o período de carência
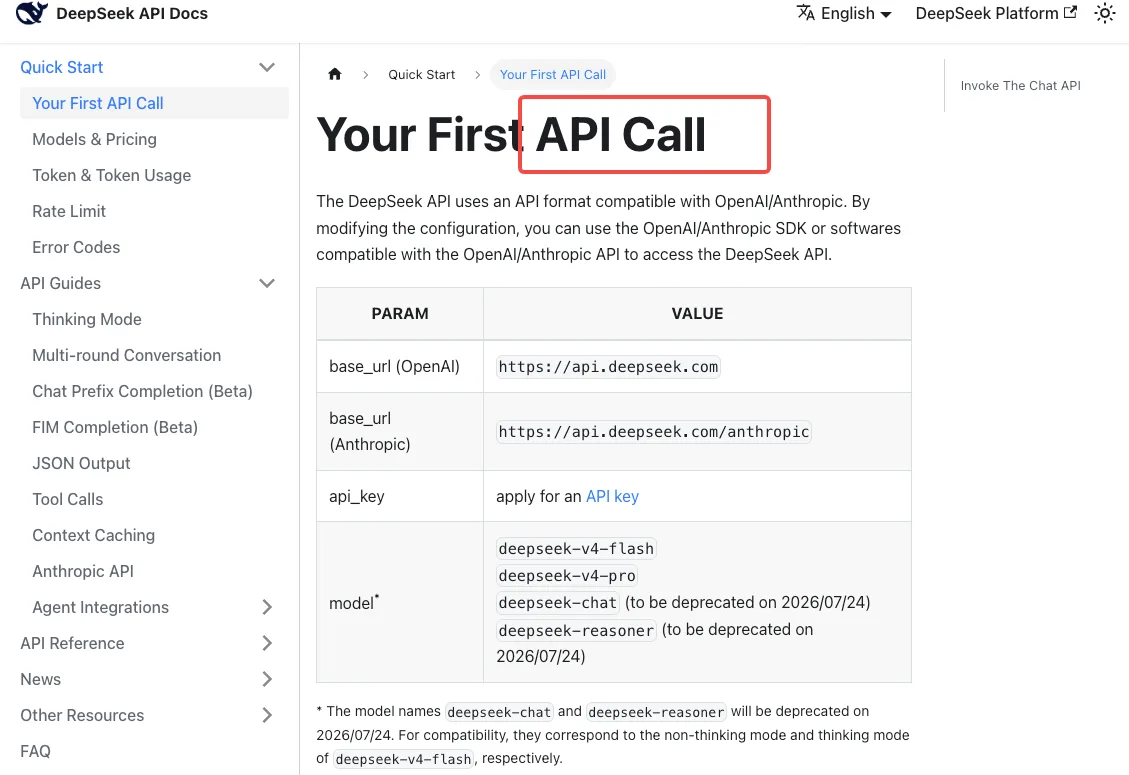
De acordo com a documentação de início rápido da API DeepSeek, o mapeamento de compatibilidade agora é:
deepseek-chat→deepseek-v4-flash(modo sem pensamento)deepseek-reasoner→deepseek-v4-flash(modo com pensamento)
Note o que isso significa: se você estava no deepseek-reasoner, você já está rodando no Flash, não no Pro. Se suas cargas de trabalho de raciocínio parecem ligeiramente diferentes na última semana, é por isso. Para obter raciocínio de nível Pro você precisa migrar explicitamente para deepseek-v4-pro — o alias nunca aponta para lá.
Checklist Pré-Migração
Inventarie cada serviço que acessa a API DeepSeek
Faça grep em todo o monorepo. Ambas as strings:
grep -rn "deepseek-chat\|deepseek-reasoner" .Não confie na sua memória sobre quais serviços usam isso. Encontrei dois cron jobs e um manipulador de webhook que havia esquecido que existiam. Verifique também templates .env, configurações de deploy, arquivos IaC e quaisquer tabelas de roteamento de gateway LLM. Se você usa um proxy como LiteLLM ou n1n.ai, verifique lá também — o log de mudanças do DeepSeek em api-docs.deepseek.com confirma que os nomes antigos estão programados para descontinuação completa, não apenas avisos de depreciação, então qualquer coisa que ainda os use falhará definitivamente.
Capture linhas de base de latência e qualidade atuais
Antes de mudar uma única str ing, capture como está “funcionando” hoje:
ing, capture como está “funcionando” hoje:
- Latência p50 / p95 / p99 por endpoint
- Distribuição de tokens de saída (média, desvio padrão)
- Pontuação de qualidade no seu conjunto de avaliação, se tiver
- Custo diário por serviço
O V4-Flash se comporta de forma ligeiramente diferente dos pesos V3.x para os quais deepseek-chat costumava rotear. Você precisa de uma linha de base para saber o que mudou após a troca.
Identifique onde o modo de pensamento era implícito (reasoner)
Todo serviço usando deepseek-reasoner recebia o modo de pensamento de graça. Após a migração, o modo de pensamento é opt-in via parâmetro. Se você esquecer de adicioná-lo, você perde silenciosamente sua capacidade de raciocínio e suas saídas pioram sem nenhum erro. Este é o bug de migração mais comum.
Alterações de Código Necessárias
Troca do nome do modelo (exemplos antes/depois)
Para serviços que não precisam do modo de pensamento:
python
# Antes
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# Depois
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Para serviços que precisam de raciocínio, a mudança é maior.
Adicionando reasoning_effort onde reasoner era usado
A documentação do modo de pensamento do DeepSeek especifica que o pensamento é habilitado via extra_body e ajustado com reasoning_effort:
python
# Antes
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# Depois
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Algumas coisas a observar:
reasoning_effortaceitahighemax. De acordo com a documentação,lowemediumsão mapeados parahigh, exhighé mapeado paramax. O padrão para requisições no modo de pensamento éhigh.- O modo de pensamento ignora silenciosamente
temperature,top_p,presence_penalty, efrequency_penalty. Configurá-los não gera erro — simplesmente não faz nada. Se sua configuração antiga do reasoner dependia detemperature=0.7, isso já estava sendo ignorado.
URL base e autenticação — sem alterações
Esta parte é genuinamente simples. https://api.deepseek.com permanece o mesmo. Sua chave de API permanece a mesma. Ambos os formatos OpenAI ChatCompletions e Anthropic SDK são suportados, então sua configuração de cliente existente continua funcionando. Apenas a string model e (para raciocínio) o extra_body mudam.
Testes de Regressão
Diferenças de formato de saída que você deve esperar
O V4-Flash é um modelo diferente dos pesos V3.2 para os quais deepseek-chat costumava rotear. Espere:
- Verbosidade ligeiramente diferente — o V4 tende a produzir saídas mais longas com o mesmo prompt
- Diferentes escolhas de formatação para blocos de código e listas
- Melhor seguimento de instruções em tarefas agênticas
- O tokenizador é da mesma família, mas as contagens de tokens podem mudar
Execute seu conjunto de avaliação. Não assuma que “é compatível” significa “é idêntico.”
Reconfirmação da linha de base de custo
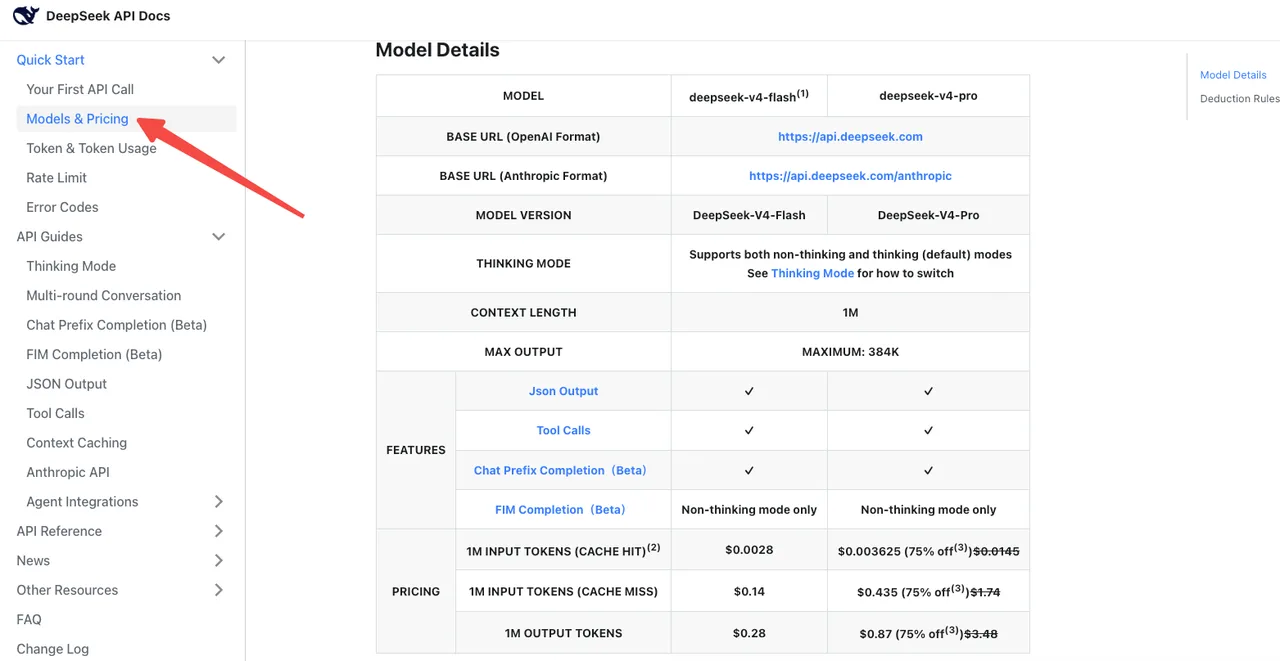
De acordo com a página oficial de preços do DeepSeek, o V4-Flash custa $0,14 / $0,28 por 1M de tokens de entrada/saída nas taxas padrão. O V4-Pro custa $1,74 / $3,48 (atualmente com 75% de desconto até 2026/05/05). O preço de cache-hit foi reduzido para 1/10 do preço de lançamento em toda a linha.
A armadilha: o modo de pensamento no V4-Pro consome dramaticamente mais tokens de saída do que o antigo reasoner. A Artificial Analysis avaliou o V4-Pro como tendo volumes de saída “muito verbosos”, gerando aproximadamente 4x a contagem média de tokens de raciocínio. Sua conta pode aumentar mesmo que a mudança do nome do modelo pareça neutra.
Validação de fluxo de trabalho agêntico
Se você executa agentes de múltiplas etapas, retestar a cadeia completa. O comportamento de chamada de ferramentas do V4 está mais próximo do Claude Code do que o V3.x estava. Esquemas de argumentos que funcionavam estão na maioria dos casos bem, mas o modelo é mais agressivo em tentar novamente e se autocorrigir, o que significa às vezes mais chamadas de ferramentas por tarefa — e mais tokens.
Estratégia de Implantação
Abordagem com feature flag
Não faça uma troca global. Encapsule o nome do modelo em um flag de configuração por serviço:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Implante serviço por serviço. Monitore taxas de erro e latência p99 por 24-48 horas por serviço antes de continuar.
Tráfego paralelo durante a mudança
Para serviços de alto tráfego, espelhe requisições para ambos o antigo e o novo por uma janela curta. Compare as saídas offline. Esta é a única maneira de detectar regressões de qualidade silenciosas antes que os usuários as detectem.
Armadilhas Comuns de Migração
As cinco que realmente vi semana passada:
- Trocar
deepseek-reasoner→deepseek-v4-prosem adicionarextra_body={"thinking": {"type": "enabled"}}. A qualidade do raciocínio cai, nenhum erro é gerado. - Fixar
temperature=0para cargas de trabalho de raciocínio e assumir que ainda funciona (é silenciosamente ignorado no modo de pensamento). - Esquecer que o alias
deepseek-reasonersó mapeava para o V4-Flash, não V4-Pro. Migrar para Pro é uma atualização, não uma troca equivalente. - Não atualizar dashboards de monitoramento. Se seu dashboard agrupa por nome de modelo, as chamadas V4 não aparecem no seu tile antigo do DeepSeek até você corrigir o rótulo.
- Esquecer integrações de terceiros. Se você faz proxy através do LiteLLM, OpenRouter ou qualquer gateway, provedores como OpenRouter já publicaram rotas V4 — mas sua configuração de gateway ainda pode fixar o nome antigo.
Perguntas Frequentes
O que acontece se eu não migrar até 24 de julho?
Após 24 de julho de 2026, 15:59 UTC, requisições usando deepseek-chat ou deepseek-reasoner falham. O aviso oficial diz que ambos os nomes serão “totalmente desativados e inacessíveis.” Não há extensão anunciada.
O deepseek-v4-flash é um substituto direto do deepseek-chat?
Para cargas de trabalho sem pensamento, na maioria das vezes sim — mesmo nível de velocidade, mesma classe de preços, mesmo endpoint. As saídas diferem ligeiramente porque os pesos subjacentes são diferentes, então execute novamente suas avaliações. Para cargas de trabalho com pensamento, você precisa adicionar o parâmetro de pensamento extra_body explicitamente.
Como preservo o comportamento do reasoner?
Use deepseek-v4-flash com o modo de pensamento habilitado se quiser permanecer no mesmo nível de computação (isso corresponde ao que deepseek-reasoner já estava fazendo). Use deepseek-v4-pro com pensamento habilitado se quiser uma melhoria de qualidade. Ambos requerem extra_body={"thinking": {"type": "enabled"}}.
Minha estrutura de cobrança vai mudar?
O modelo de cobrança por token é o mesmo. As taxas diferem — Flash é mais barato do que as antigas taxas do deepseek-chat, Pro é mais caro mas atualmente com desconto. O preço de cache-hit agora é 10% das taxas padrão. Fique atento à inflação de tokens de saída no modo de pensamento.
Posso testar o antigo e o novo em paralelo?
Sim. Ambos os nomes de modelos legados e novos funcionam simultaneamente até 24 de julho. Use um feature flag para rotear uma porcentagem do tráfego para o V4 e compare. Este é o caminho de migração de menor risco.
Se você for colocar em produção amanhã, o movimento mais seguro é o menor: troque deepseek-chat → deepseek-v4-flash primeiro, deixe as cargas de trabalho de raciocínio por último, e não toque no V4-Pro até que você tenha feito benchmark em relação ao seu conjunto de avaliação real. O prazo é real, mas também está a três meses — há tempo para fazer isso com cuidado. As equipes que serão prejudicadas no final de julho serão as que trataram isso como um PR de uma linha e pularam a revisão de regressão. Não seja essas equipes.
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber