DeepSeek V4 API Migration: Update Model Names Before July
DeepSeek-chat and deepseek-reasoner retire July 24, 2026. Step-by-step migration to deepseek-v4-pro and deepseek-v4-flash with code diffs.

I pulled the prod logs on a Monday morning and counted 14,000 calls still hitting deepseek-chat. Three months from now, every one of those returns a 404. That’s the situation a lot of teams are walking into without knowing it — DeepSeek announced the deprecation, the calendar moved, and nobody on the on-call rotation forwarded the changelog to the people who actually own the integration. I ran the migration on our own stack last week, so this is the version with the diffs that worked, not the version that paraphrases the announcement. My name’s Dora, I write infrastructure notes for backend teams, and the short version is: it’s a one-line code change, but the testing around it is where everything goes wrong if you skip it.
Already on DeepSeek? Switch to WaveSpeedAI without code changes — same OpenAI SDK, just change base URL and key. DeepSeek V3.2 API → · DeepSeek R1 API →
The hard date is July 24, 2026, 15:59 UTC. After that, deepseek-chat and deepseek-reasoner return errors. There’s no extension being discussed. Migrate now, finish testing in May, leave June for stragglers.
What’s Changing and When
Deprecation timeline: deepseek-chat / deepseek-reasoner sunset on 2026-07-24
DeepSeek V4 launched on April 24, 2026, and the official DeepSeek V4 release notes state both legacy model names will be “fully retired and inaccessible” after July 24, 2026, 15:59 UTC. That’s a hard cutoff, not a soft warning. Requests using the old names after that timestamp fail.
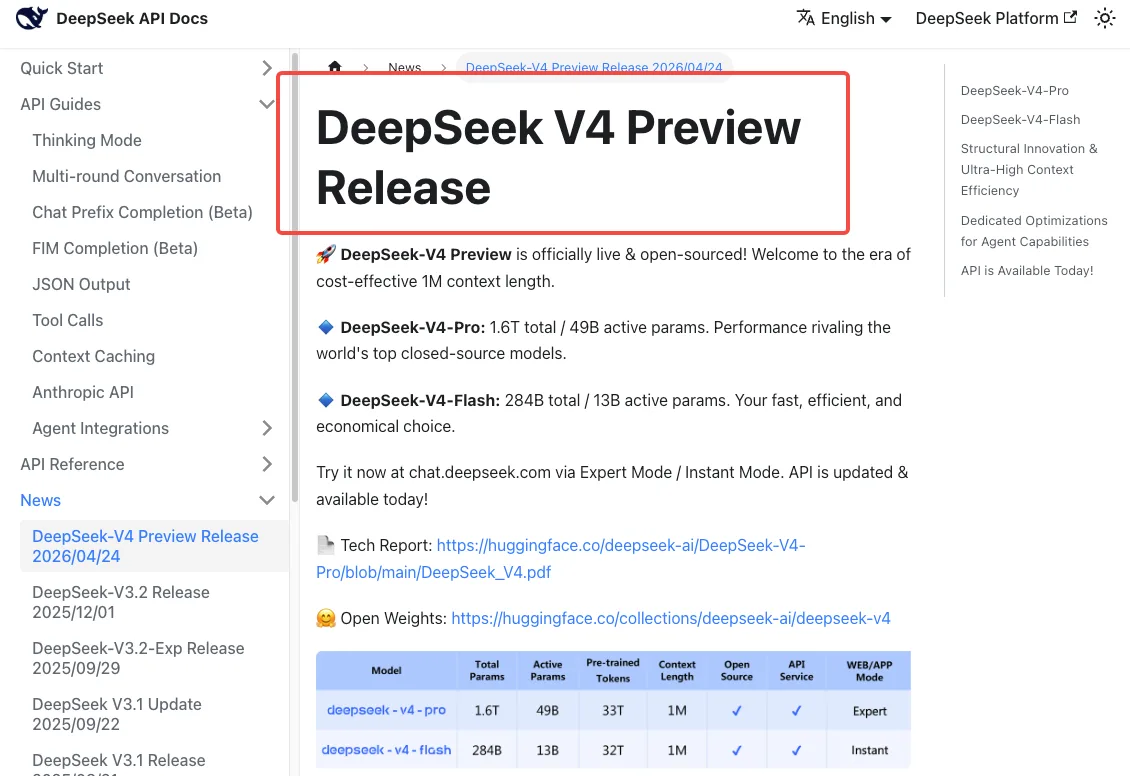
During the grace period — now through July 24 — both legacy names continue to work, but they’re transparently routed to V4-Flash. So you’re already on V4 whether you’ve updated your code or not.
New model names: deepseek-v4-pro, deepseek-v4-flash
Two new model IDs replace the old aliases:
deepseek-v4-pro— 1.6T total parameters, 49B active, 1M context window, 384K max output. The reasoning-heavy option.deepseek-v4-flash— 284B total, 13B active, same 1M context. Cheaper and faster, suitable for most production workloads.
Both support thinking and non-thinking modes through the same model ID. You no longer pick reasoning by choosing a separate model — you toggle it via parameters. This is the part that breaks naive migrations.
Transitional mapping during the grace period
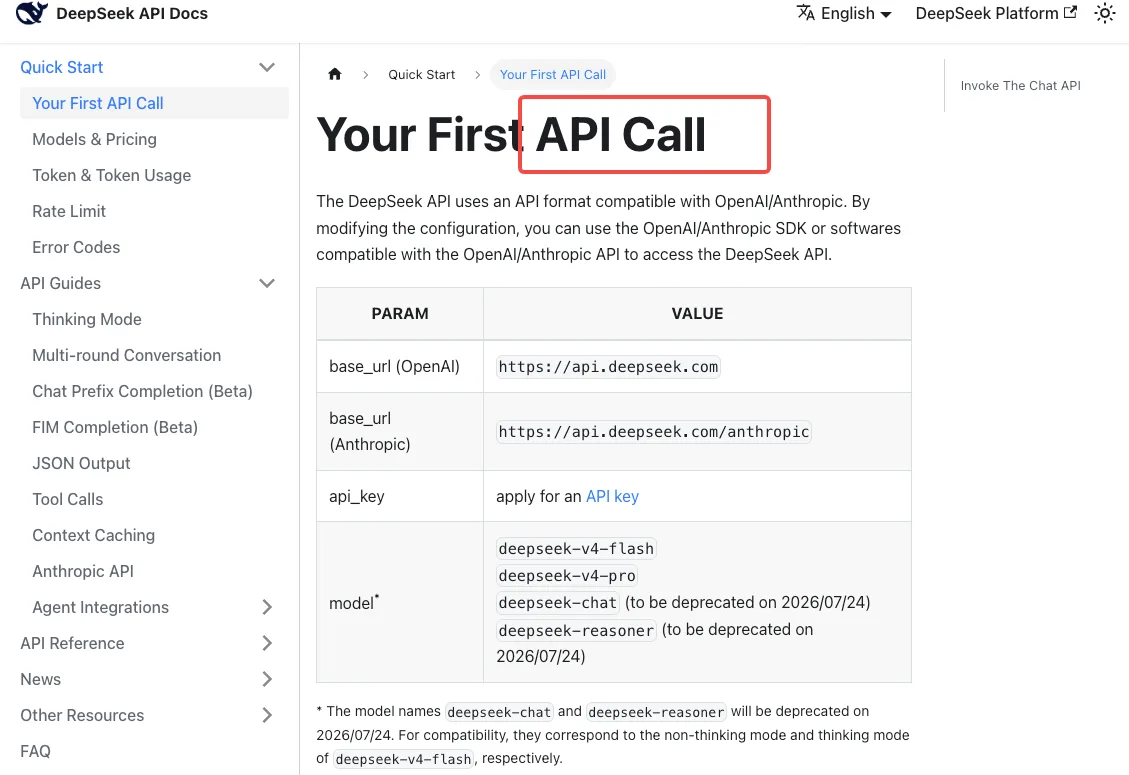
According to the DeepSeek API quickstart documentation, the compatibility mapping right now is:
deepseek-chat→deepseek-v4-flash(non-thinking mode)deepseek-reasoner→deepseek-v4-flash(thinking mode)
Note what this means: if you were on deepseek-reasoner, you’re already running on Flash, not Pro. If your reasoning workloads have felt slightly different in the last week, that’s why. To get Pro-tier reasoning you have to explicitly migrate to deepseek-v4-pro — the alias never points you there.
Pre-Migration Checklist
Inventory every service hitting the DeepSeek API
Grep the entire monorepo. Both strings:
grep -rn "deepseek-chat\|deepseek-reasoner" .Don’t trust your memory of which services use it. I found two cron jobs and a webhook handler I’d forgotten existed. Also check .env templates, deploy configs, IaC files, and any LLM gateway routing tables. If you use a proxy like LiteLLM or n1n.ai, check there too — the DeepSeek change log on api-docs.deepseek.com confirms the old names are scheduled for full discontinuation, not just deprecation warnings, so anything still using them will hard-fail.
Capture current latency and quality baselines
Before you change a single str ing, snapshot what “working” looks like today:
ing, snapshot what “working” looks like today:
- p50 / p95 / p99 latency per endpoint
- Output token distribution (mean, std)
- Quality score on your eval set, if you have one
- Daily cost per service
V4-Flash behaves slightly differently from the V3.x weights that deepseek-chat used to point to. You want a baseline so you can tell what changed after the swap.
Identify where thinking mode was implicit (reasoner)
Every service using deepseek-reasoner was getting thinking mode for free. After migration, thinking mode is opt-in via a parameter. If you forget to add it, you silently lose your reasoning capability and your outputs get worse without any error. This is the single most common migration bug.
Code Changes Required
Model name swap (before/after examples)
For services that don’t need thinking mode:
python
# Before
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# After
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)For services that need reasoning, the change is bigger.
Adding reasoning_effort where reasoner was used
The DeepSeek thinking mode documentation specifies that thinking is enabled via extra_body and tuned with reasoning_effort:
python
# Before
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# After
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)A few things to watch:
reasoning_effortacceptshighandmax. Per the docs,lowandmediumare mapped tohigh, andxhighis mapped tomax. The default for thinking-mode requests ishigh.- Thinking mode silently ignores
temperature, top_p, presence_penalty, and frequency_penalty. Setting them won’t error — it just won’t do anything. If your old reasoner setup depended ontemperature=0.7, that was already being ignored.
Base URL and auth — unchanged
This part is genuinely simple. https://api.deepseek.com stays the same. Your API key stays the same. Both OpenAI ChatCompletions and Anthropic SDK formats are supported, so your existing client setup keeps working. Only the model string and (for reasoning) the extra_body change.
Regression Testing
Output shape diffs you should expect
V4-Flash is a different model from the V3.2 weights deepseek-chat used to route to. Expect:
- Slightly different verbosity — V4 tends to produce longer outputs at the same prompt
- Different formatting choices for code blocks and lists
- Better instruction-following on agentic tasks
- Tokenizer is the same family, but token counts can shift
Run your eval set. Don’t assume “it’s compatible” means “it’s identical.”
Cost baseline re-check
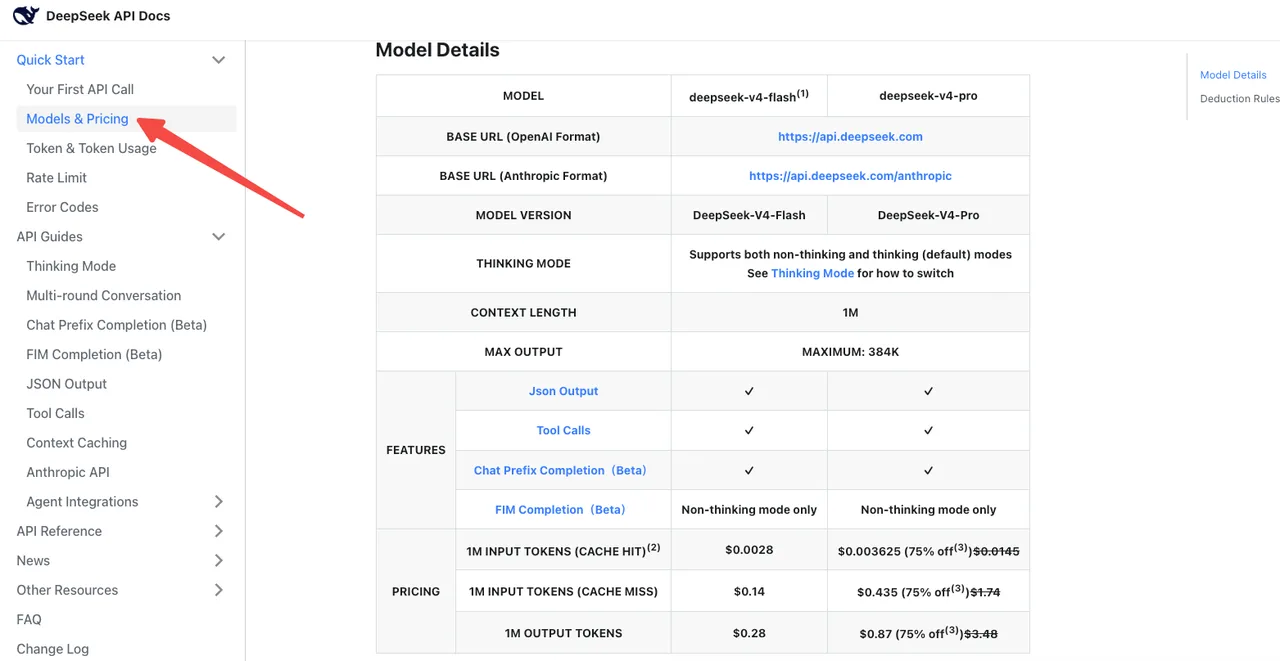
Per the official DeepSeek pricing page, V4-Flash is $0.14 / $0.28 per 1M input/output tokens at standard rates. V4-Pro is $1.74 / $3.48 (currently 75% off until 2026/05/05). Cache-hit pricing was reduced to 1/10 of the launch price across the lineup.
The trap: thinking mode on V4-Pro burns dramatically more output tokens than the old reasoner. Artificial Analysis benchmarked V4-Pro at “very verbose” output volumes, generating roughly 4x the average reasoning token count. Your bill can go up even if your model name change looks neutral.
Agent workflow validation
If you run multi-step agents, retest the full chain. V4’s tool-calling behavior is closer to Claude Code than V3.x was. Argument schemas that worked are mostly fine, but the model is more aggressive about retrying and self-correcting, which means sometimes more tool calls per task — and more tokens.
Rollout Strategy
Feature flag approach
Don’t do a global swap. Wrap the model name in a config flag per service:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Roll out service by service. Watch error rates and p99 latency for 24-48 hours per service before moving on.
Shadow traffic during cutover
For high-traffic services, mirror requests to both old and new for a short window. Compare outputs offline. This is the only way to catch silent quality regressions before users do.
Common Migration Pitfalls
The five I actually saw last week:
- Swapping
deepseek-reasoner→deepseek-v4-pro**without adding extra_body={"thinking": {"type": "enabled"}}**. Reasoning quality drops, no error fires. - Hardcoding
temperature=0for reasoning workloads and assuming it still works (it’s silently ignored in thinking mode). - Forgetting that the alias
deepseek-reasoneronly mapped to V4-Flash, not V4-Pro. Migrating to Pro is an upgrade, not a like-for-like swap. - Not updating monitoring dashboards. If your dashboard groups by model name, V4 calls don’t show up under your old DeepSeek tile until you fix the label.
- Forgetting third-party integrations. If you proxy through LiteLLM, OpenRouter, or any gateway, providers like OpenRouter have already published V4 routes — but your gateway config might still pin the old name.
FAQ
What happens if I don’t migrate by July 24?
After July 24, 2026, 15:59 UTC, requests using deepseek-chat or deepseek-reasoner fail. The official notice says both names will be “fully retired and inaccessible.” There’s no announced extension.
Is deepseek-v4-flash a drop-in replacement for deepseek-chat?
For non-thinking workloads, mostly yes — same speed tier, same pricing class, same endpoint. Outputs differ slightly because the underlying weights are different, so re-run your evals. For thinking workloads, you need to add the extra_body thinking parameter explicitly.
How do I preserve reasoner behavior?
Use deepseek-v4-flash with thinking mode enabled if you want to stay on the same compute tier (this matches what deepseek-reasoner was already doing). Use deepseek-v4-pro with thinking enabled if you want a quality upgrade. Both require extra_body={"thinking": {"type": "enabled"}}.
Will my billing structure change?
Per-token billing model is the same. Rates differ — Flash is cheaper than the old deepseek-chat rates, Pro is pricier but currently discounted. Cache-hit pricing is now 10% of standard rates. Watch for output-token inflation in thinking mode.
Can I test both old and new in parallel?
Yes. Both legacy and new model names work simultaneously through July 24. Use a feature flag to route a percentage of traffic to V4 and compare. This is the lowest-risk migration path.
If you ship to prod tomorrow, the safest move is the smallest one: swap deepseek-chat → deepseek-v4-flash first, leave reasoning workloads for last, and don’t touch V4-Pro until you’ve benchmarked it against your actual eval set. The deadline is real but it’s also three months out — there’s time to do this carefully. The teams that get bitten in late July will be the ones who treated it as a one-line PR and skipped the regression pass. Don’t be those teams.
Previous posts:





