DeepSeek V4 API 마이그레이션: 7월 전에 모델 이름 업데이트하기
DeepSeek-chat과 deepseek-reasoner는 2026년 7월 24일에 서비스 종료됩니다. deepseek-v4-pro와 deepseek-v4-flash로의 단계별 마이그레이션 가이드와 코드 변경 사항을 확인하세요.

월요일 아침에 프로덕션 로그를 열어보니 deepseek-chat을 여전히 호출하는 요청이 14,000건이나 있었다. 석 달 후면 그 모든 요청이 404를 반환한다. 많은 팀이 이 사실을 모른 채 같은 상황에 처해 있다 — DeepSeek이 지원 중단을 공지했고, 달력은 계속 넘어가고 있는데, 온콜 담당자 중 아무도 실제로 통합을 소유한 사람들에게 변경 내역을 전달하지 않았다. 나는 지난주에 우리 스택에서 마이그레이션을 직접 실행했으므로, 이 글은 공지 내용을 단순히 풀어 쓴 것이 아니라 실제로 작동한 diff가 담긴 버전이다. 나는 Dora이고, 백엔드 팀을 위한 인프라 노트를 작성한다. 요약하면 이렇다: 코드 변경은 한 줄이지만, 테스트를 건너뛰면 바로 거기서 모든 것이 틀어진다.
이미 DeepSeek을 사용 중이신가요? 코드 변경 없이 WaveSpeedAI로 전환하세요 — 동일한 OpenAI SDK, base URL과 키만 변경하면 됩니다. DeepSeek V3.2 API → · DeepSeek R1 API →
확정된 날짜는 2026년 7월 24일 15:59 UTC다. 그 이후에는 deepseek-chat과 deepseek-reasoner가 오류를 반환한다. 연장에 대한 논의는 없다. 지금 마이그레이션을 시작하고, 5월 중으로 테스트를 완료하고, 6월은 뒤처진 것들을 처리하는 데 남겨두자.
무엇이 언제 바뀌는가
지원 중단 타임라인: deepseek-chat / deepseek-reasoner 2026-07-24 종료
DeepSeek V4는 2026년 4월 24일에 출시되었으며, 공식 DeepSeek V4 릴리스 노트에는 두 레거시 모델명이 2026년 7월 24일 15:59 UTC 이후 “완전히 폐기되어 접근 불가”가 된다고 명시되어 있다. 이는 소프트 경고가 아닌 강제 종료다. 해당 시각 이후 구 모델명을 사용한 요청은 실패한다.
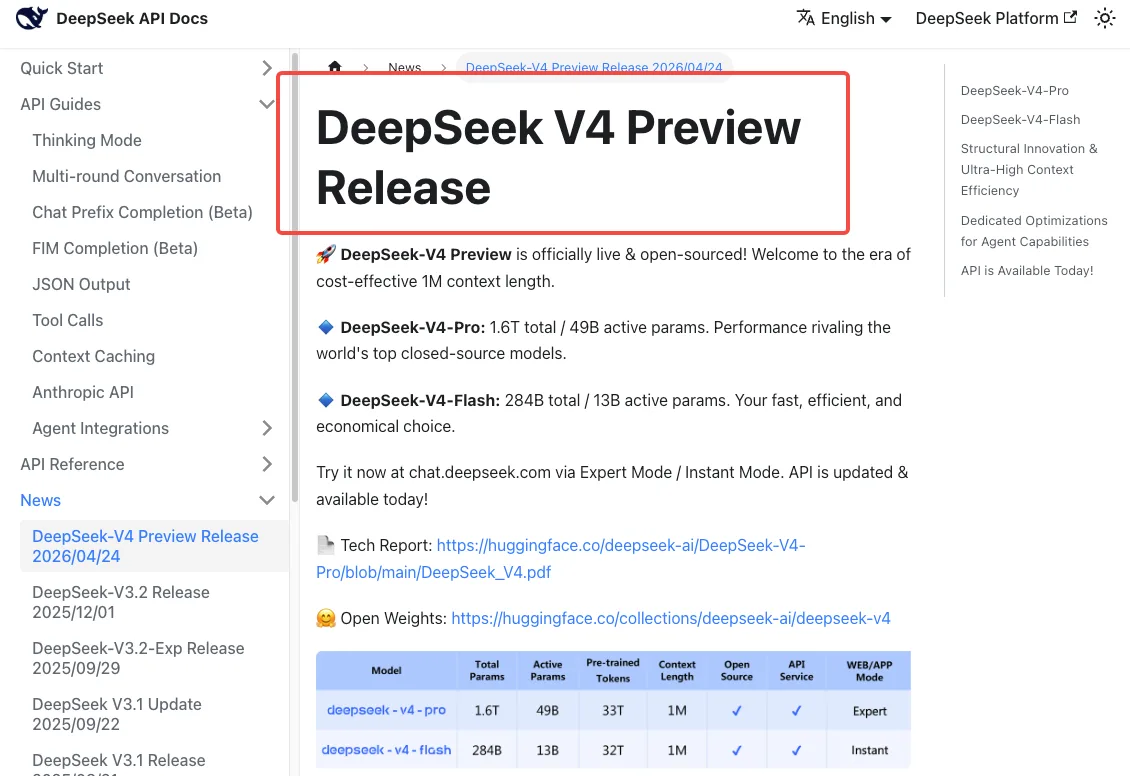
유예 기간 동안 — 지금부터 7월 24일까지 — 두 레거시 모델명은 계속 작동하지만, 내부적으로는 V4-Flash로 투명하게 라우팅된다. 즉, 코드를 업데이트했든 아니든 이미 V4에서 실행 중인 것이다.
새 모델명: deepseek-v4-pro, deepseek-v4-flash
두 개의 새 모델 ID가 기존 alias를 대체한다:
deepseek-v4-pro— 총 파라미터 1.6T, 활성 파라미터 49B, 1M 컨텍스트 윈도우, 최대 384K 출력. 추론 중심 옵션.deepseek-v4-flash— 총 284B, 활성 13B, 동일한 1M 컨텍스트. 더 저렴하고 빠르며, 대부분의 프로덕션 워크로드에 적합.
두 모델 모두 동일한 모델 ID를 통해 thinking 및 non-thinking 모드를 지원한다. 더 이상 별도 모델을 선택하여 추론 기능을 사용하지 않는다 — 파라미터로 토글한다. 단순한 마이그레이션에서 문제가 생기는 부분이 바로 여기다.
유예 기간 중 전환 매핑
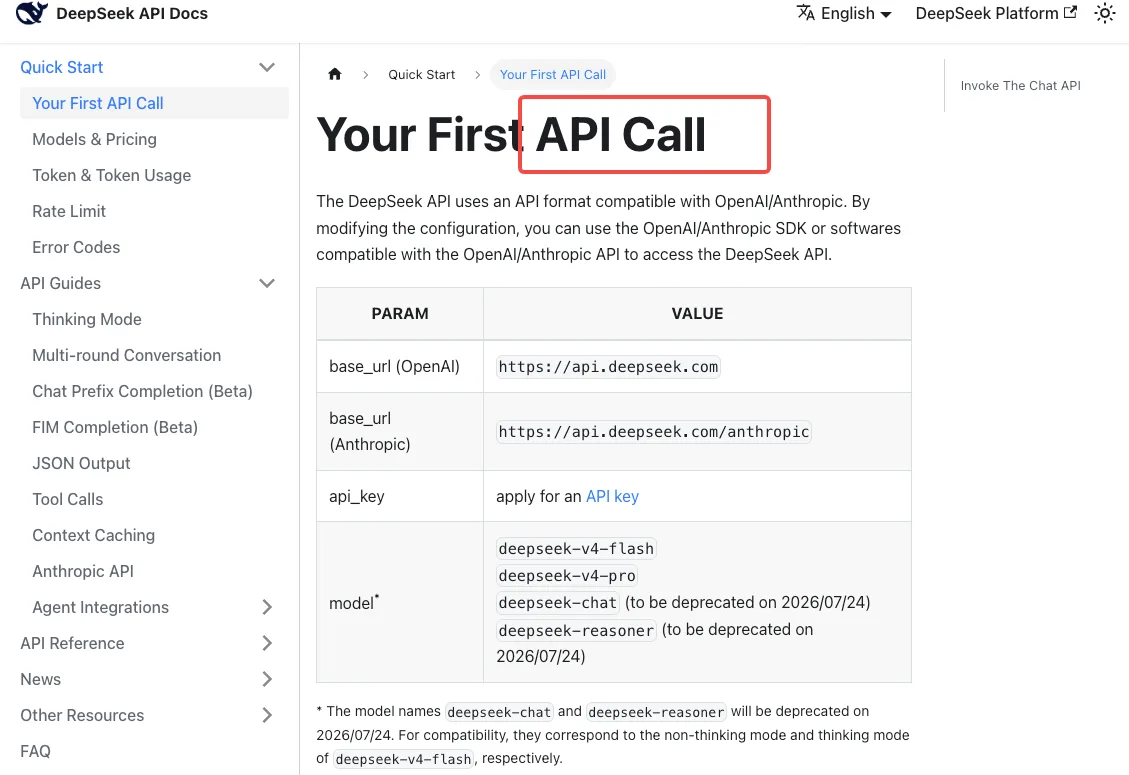
DeepSeek API 빠른 시작 문서에 따르면 현재 호환성 매핑은 다음과 같다:
deepseek-chat→deepseek-v4-flash(non-thinking 모드)deepseek-reasoner→deepseek-v4-flash(thinking 모드)
이것이 의미하는 바를 주목하라: deepseek-reasoner를 사용 중이었다면, 이미 Pro가 아닌 Flash에서 실행 중이다. 지난 한 주간 추론 워크로드가 약간 다르게 느껴졌다면, 그것이 이유다. Pro 수준의 추론을 사용하려면 명시적으로 deepseek-v4-pro로 마이그레이션해야 한다 — alias는 절대 거기로 연결되지 않는다.
마이그레이션 전 체크리스트
DeepSeek API를 호출하는 모든 서비스 목록 파악
모노레포 전체를 grep하라. 두 문자열 모두:
grep -rn "deepseek-chat\|deepseek-reasoner" .어느 서비스가 사용하는지 기억에 의존하지 마라. 나는 존재조차 잊고 있었던 크론 작업 두 개와 웹훅 핸들러 하나를 발견했다. .env 템플릿, 배포 설정, IaC 파일, 모든 LLM 게이트웨이 라우팅 테이블도 확인하라. LiteLLM이나 n1n.ai 같은 프록시를 사용한다면 거기도 확인하라 — api-docs.deepseek.com의 DeepSeek 변경 로그는 구 모델명이 단순 지원 중단 경고가 아닌 완전 종료로 예정되어 있음을 확인해주므로, 여전히 구 모델명을 사용하는 것은 모두 하드 실패한다.
현재 레이턴시 및 품질 기준선 캡처
단 하나의 문자열도 변경하기 전에, 지금 “정상 작동” 상태가 어떤 모습인지 스냅샷을 찍어라:
- 엔드포인트별 p50 / p95 / p99 레이턴시
- 출력 토큰 분포 (평균, 표준편차)
- eval 세트가 있다면 품질 점수
- 서비스별 일일 비용
V4-Flash는 deepseek-chat이 라우팅되던 V3.x 가중치와는 다른 모델이다. 스왑 후 무엇이 변했는지 파악할 수 있도록 기준선이 필요하다.
thinking 모드가 암묵적으로 사용되던 곳 파악 (reasoner)
deepseek-reasoner를 사용하던 모든 서비스는 thinking 모드를 무료로 제공받고 있었다. 마이그레이션 후에는 thinking 모드가 파라미터를 통해 명시적으로 활성화해야 한다. 이를 잊으면 추론 기능이 조용히 사라지고 오류 없이 출력 품질이 저하된다. 이것이 가장 흔한 마이그레이션 버그다.
필요한 코드 변경
모델명 교체 (변경 전/후 예시)
thinking 모드가 필요 없는 서비스의 경우:
python
# 변경 전
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# 변경 후
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)추론이 필요한 서비스의 경우, 변경 사항이 더 크다.
reasoner를 사용하던 곳에 reasoning_effort 추가
DeepSeek thinking 모드 문서에 따르면 thinking은 extra_body를 통해 활성화하고 reasoning_effort로 조정한다:
python
# 변경 전
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# 변경 후
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)주의해야 할 사항:
reasoning_effort는high와max를 허용한다. 문서에 따르면low와medium은high로 매핑되고,xhigh는max로 매핑된다. thinking 모드 요청의 기본값은high다.- thinking 모드는
temperature,top_p,presence_penalty,frequency_penalty를 조용히 무시한다. 설정해도 오류가 발생하지 않는다 — 단지 아무 효과도 없을 뿐이다. 구 reasoner 설정이temperature=0.7에 의존했다면, 이미 무시되고 있었던 것이다.
Base URL 및 인증 — 변경 없음
이 부분은 진정으로 단순하다. https://api.deepseek.com은 그대로다. API 키도 그대로다. OpenAI ChatCompletions 및 Anthropic SDK 형식 모두 지원되므로, 기존 클라이언트 설정이 그대로 작동한다. 변경되는 것은 model 문자열과 (추론의 경우) extra_body뿐이다.
회귀 테스트
예상해야 할 출력 형태 차이
V4-Flash는 deepseek-chat이 라우팅되던 V3.2 가중치와는 다른 모델이다. 다음을 예상하라:
- 출력 장황함이 약간 다름 — V4는 동일한 프롬프트에서 더 긴 출력을 생성하는 경향
- 코드 블록과 목록의 포맷팅 선택 차이
- 에이전틱 작업에서의 향상된 지시 따르기
- 토크나이저는 같은 계열이지만, 토큰 수가 달라질 수 있음
eval 세트를 실행하라. “호환 가능”이 “동일”을 의미한다고 가정하지 마라.
비용 기준선 재확인
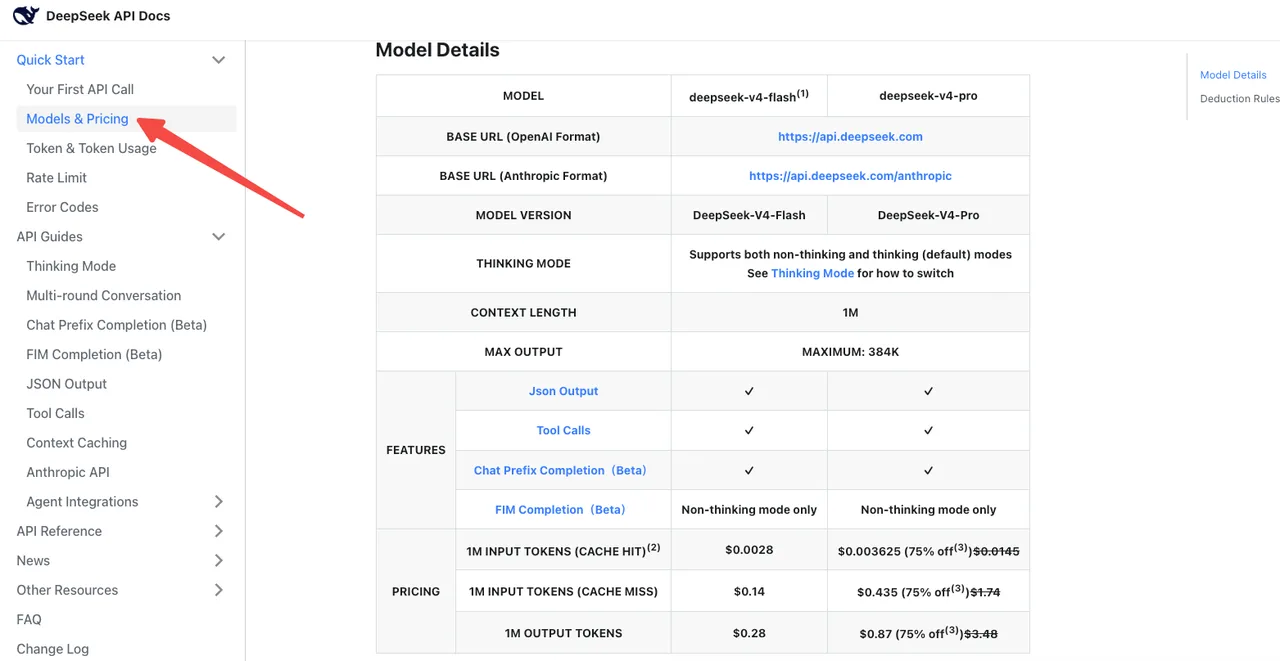
공식 DeepSeek 가격 페이지에 따르면, V4-Flash는 표준 요금으로 입력/출력 토큰 1M당 $0.14 / $0.28이다. V4-Pro는 $1.74 / $3.48 (현재 2026/05/05까지 75% 할인 중). 캐시 히트 가격은 전 라인업에 걸쳐 출시 가격의 1/10로 인하되었다.
함정: V4-Pro의 thinking 모드는 구 reasoner보다 극적으로 더 많은 출력 토큰을 소비한다. Artificial Analysis가 V4-Pro를 “매우 장황한” 출력량으로 벤치마킹했으며, 평균 추론 토큰 수의 약 4배를 생성한다. 모델명 변경이 중립적으로 보여도 청구서가 올라갈 수 있다.
에이전트 워크플로우 검증
멀티 스텝 에이전트를 실행한다면, 전체 체인을 다시 테스트하라. V4의 도구 호출 동작은 V3.x보다 Claude Code에 더 가깝다. 작동하던 인수 스키마는 대부분 괜찮지만, 모델이 재시도와 자가 수정에 더 적극적이어서 작업당 도구 호출이 더 많아질 수 있고 — 토큰도 더 많이 소비한다.
롤아웃 전략
기능 플래그 접근법
전체 일괄 교체는 하지 마라. 서비스별로 config 플래그에 모델명을 래핑하라:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")서비스별로 롤아웃하라. 다음 서비스로 넘어가기 전에 각 서비스별로 24-48시간 동안 오류율과 p99 레이턴시를 모니터링하라.
전환 중 섀도우 트래픽
트래픽이 많은 서비스의 경우, 짧은 기간 동안 구버전과 신버전 모두에 요청을 미러링하라. 오프라인에서 출력을 비교하라. 사용자가 발견하기 전에 조용한 품질 회귀를 잡는 유일한 방법이다.
흔한 마이그레이션 함정
지난주에 실제로 목격한 다섯 가지:
deepseek-reasoner→deepseek-v4-pro로 교체하면서extra_body={"thinking": {"type": "enabled"}}를 추가하지 않음. 추론 품질이 저하되지만 오류는 발생하지 않음.- 추론 워크로드에
temperature=0을 하드코딩하고 여전히 작동한다고 가정 (thinking 모드에서는 조용히 무시됨). deepseek-reasoneralias가 V4-Pro가 아닌 V4-Flash에만 매핑된다는 사실을 잊음. Pro로 마이그레이션하는 것은 업그레이드이지 동등한 교체가 아님.- 모니터링 대시보드 미업데이트. 대시보드가 모델명으로 그룹화된다면, 레이블을 수정할 때까지 V4 호출이 기존 DeepSeek 타일에 표시되지 않음.
- 서드파티 통합 누락. LiteLLM, OpenRouter, 또는 게이트웨이를 통해 프록시한다면, OpenRouter 같은 공급자는 이미 V4 라우트를 게시했지만 — 게이트웨이 설정이 여전히 구 모델명을 고정하고 있을 수 있음.
FAQ
7월 24일까지 마이그레이션하지 않으면 어떻게 되나요?
2026년 7월 24일 15:59 UTC 이후, deepseek-chat 또는 deepseek-reasoner를 사용하는 요청은 실패한다. 공식 공지는 두 모델명이 “완전히 폐기되어 접근 불가”가 된다고 밝히고 있다. 연장에 대한 공지는 없다.
deepseek-v4-flash가 deepseek-chat의 드롭인 대체제인가요?
non-thinking 워크로드의 경우, 대부분 그렇다 — 동일한 속도 티어, 동일한 가격 등급, 동일한 엔드포인트. 기반 가중치가 다르기 때문에 출력이 약간 다르므로, eval을 다시 실행하라. thinking 워크로드의 경우, extra_body thinking 파라미터를 명시적으로 추가해야 한다.
reasoner 동작을 유지하려면 어떻게 해야 하나요?
동일한 컴퓨팅 티어를 유지하고 싶다면 thinking 모드를 활성화한 deepseek-v4-flash를 사용하라 (이것이 deepseek-reasoner가 이미 하고 있던 것과 일치한다). 품질 업그레이드를 원한다면 thinking을 활성화한 deepseek-v4-pro를 사용하라. 둘 다 extra_body={"thinking": {"type": "enabled"}}가 필요하다.
청구 구조가 변경되나요?
토큰당 청구 모델은 동일하다. 요금은 다르다 — Flash는 구 deepseek-chat 요금보다 저렴하고, Pro는 더 비싸지만 현재 할인 중이다. 캐시 히트 가격은 이제 표준 요금의 10%다. thinking 모드에서의 출력 토큰 인플레이션을 주시하라.
구버전과 새 버전을 병렬로 테스트할 수 있나요?
그렇다. 레거시 모델명과 새 모델명 모두 7월 24일까지 동시에 작동한다. 기능 플래그를 사용하여 트래픽의 일부를 V4로 라우팅하고 비교하라. 이것이 가장 위험도가 낮은 마이그레이션 경로다.
내일 프로덕션에 배포한다면, 가장 안전한 움직임은 가장 작은 것이다: 먼저 deepseek-chat → deepseek-v4-flash로 교체하고, 추론 워크로드는 마지막으로 남겨두고, 실제 eval 세트에 대한 벤치마킹이 완료될 때까지 V4-Pro는 손대지 마라. 마감 기한은 실재하지만 석 달이나 남아 있다 — 신중하게 할 시간이 있다. 7월 말에 피해를 입는 팀은 이것을 한 줄짜리 PR로 처리하고 회귀 테스트를 건너뛴 팀이 될 것이다. 그런 팀이 되지 마라.
이전 게시글:





