DeepSeek V4 APIマイグレーション:7月までにモデル名を更新する
deepseek-chatとdeepseek-reasonerは2026年7月24日に廃止されます。deepseek-v4-proとdeepseek-v4-flashへのステップバイステップの移行ガイド(コード差分付き)。

月曜日の朝、本番ログを確認したら deepseek-chat へのリクエストが14,000件あった。3ヶ月後、そのリクエストはすべて404を返す。多くのチームがそれを知らずに直面しようとしている状況だ — DeepSeekが廃止をアナウンスし、カレンダーは進み、オンコールのローテーションに入っている誰もそのchangelogをインテグレーションを実際に担当している人に転送しなかった。先週、自分たちのスタックでマイグレーションを実行した。これはアナウンスを言い換えたものではなく、実際に動いたdiffの話だ。私はDoraといい、バックエンドチーム向けにインフラのメモを書いている。短くまとめると:コードの変更は1行だが、それを取り巻くテストこそが、スキップすればすべてが崩れる部分だ。
すでにDeepSeekをお使いですか? コードを変更せずWaveSpeedAIに切り替えられます — 同じOpenAI SDK、ベースURLとキーを変えるだけ。DeepSeek V3.2 API → · DeepSeek R1 API →
ハードな期限は 2026年7月24日 15:59 UTC だ。それ以降、deepseek-chat と deepseek-reasoner はエラーを返す。延長の議論はない。今すぐマイグレーションし、5月中にテストを終え、6月を遅れているサービスの対応に充てよう。
何が、いつ変わるのか
廃止タイムライン:deepseek-chat / deepseek-reasoner は2026-07-24にサンセット
DeepSeek V4は2026年4月24日にローンチされ、DeepSeek V4公式リリースノートには、両方のレガシーモデル名が2026年7月24日 15:59 UTC以降「完全に廃止され、アクセス不能になる」と明記されている。ソフトな警告ではなく、ハードなカットオフだ。そのタイムスタンプ以降に古い名前を使ったリクエストは失敗する。
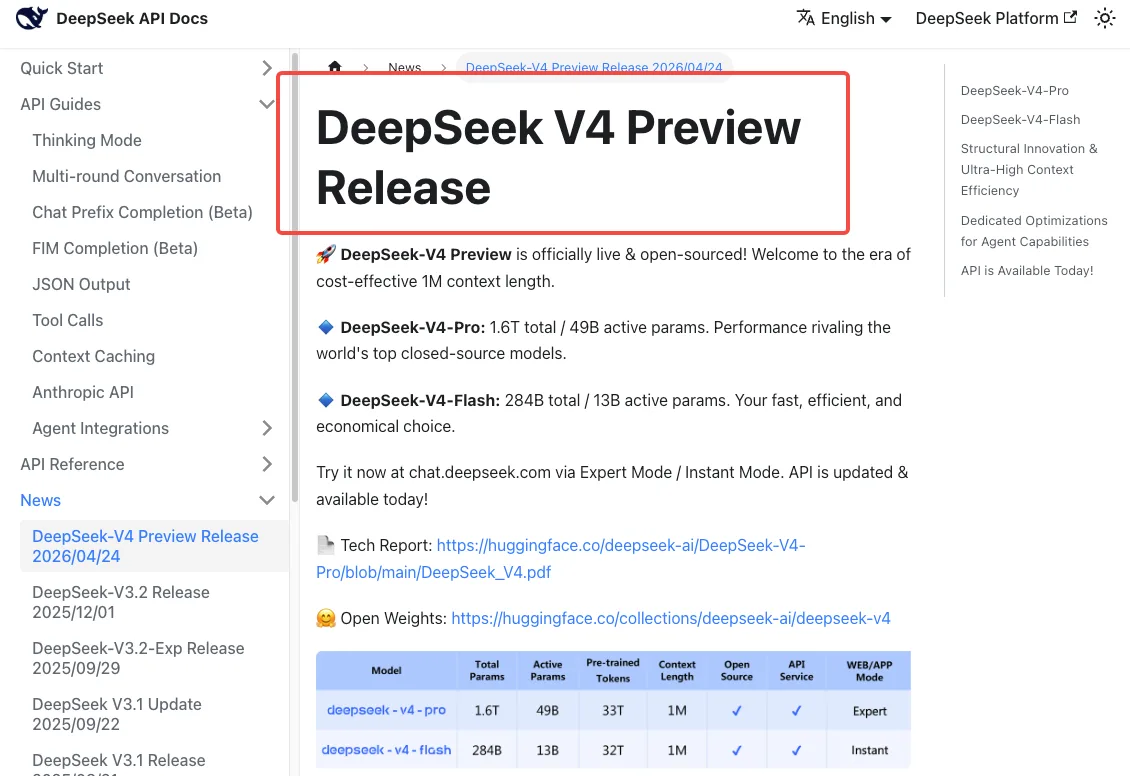
猶予期間中 — 現在から7月24日まで — 両方のレガシー名は引き続き動作するが、透過的にV4-Flashにルーティングされる。つまり、コードを更新したかどうかに関わらず、あなたはすでにV4上で動いている。
新しいモデル名:deepseek-v4-pro、deepseek-v4-flash
2つの新しいモデルIDが古いエイリアスを置き換える:
deepseek-v4-pro— 総パラメータ1.6T、アクティブ49B、コンテキストウィンドウ1M、最大出力384K。推論重視のオプション。deepseek-v4-flash— 総284B、アクティブ13B、同じ1Mコンテキスト。安くて速く、ほとんどの本番ワークロードに適している。
両方とも同じモデルIDでthinkingモードと非thinkingモードをサポートする。推論のために別のモデルを選ぶ必要はなくなった — パラメータでトグルする。これが単純なマイグレーションを壊す部分だ。
猶予期間中の移行マッピング
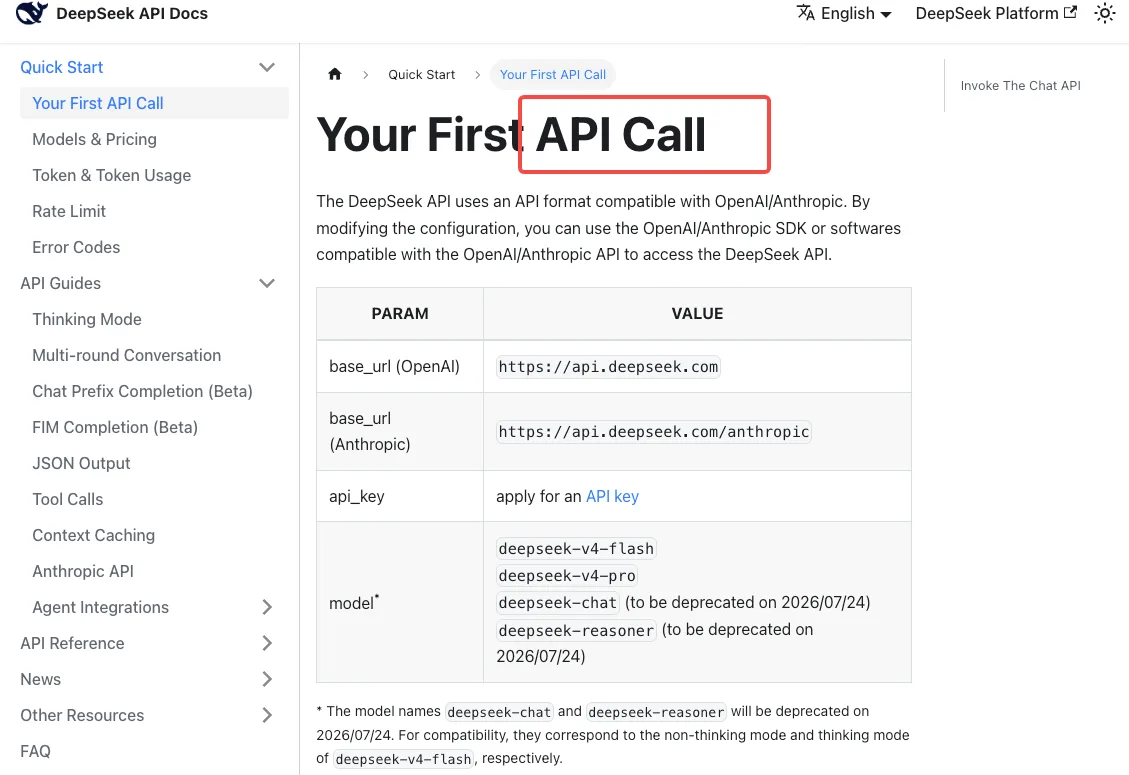
DeepSeek APIクイックスタートドキュメントによると、現在の互換性マッピングは以下の通り:
deepseek-chat→deepseek-v4-flash(非thinkingモード)deepseek-reasoner→deepseek-v4-flash(thinkingモード)
これが意味することに注目:deepseek-reasoner を使っていた場合、すでにProではなくFlash上で動いている。先週から推論ワークロードの挙動が少し違うと感じていたなら、それが理由だ。Proレベルの推論を得るには deepseek-v4-pro に明示的にマイグレーションする必要がある — エイリアスはそこに向いていない。
マイグレーション前チェックリスト
DeepSeek APIを叩いているすべてのサービスを洗い出す
モノレポ全体をgrepする。両方の文字列を:
grep -rn "deepseek-chat\|deepseek-reasoner" .どのサービスが使っているか記憶を信用しないこと。忘れていたcronジョブが2つとwebhookハンドラーが1つ見つかった。.env テンプレート、デプロイ設定、IaCファイル、LLMゲートウェイのルーティングテーブルも確認すること。LiteLLMやn1n.aiのようなプロキシを使っている場合はそこも確認する — api-docs.deepseek.comのDeepSeek変更ログは古い名前が廃止警告だけでなく完全な廃止が予定されていることを確認しているので、それらを使っているものはすべてハードフェイルする。
現在のレイテンシと品質のベースラインを記録する
1文字も変更する前に、今日の「動作している」状態をスナップショットしておく:
- エンドポイントごとのp50 / p95 / p99レイテンシ
- 出力トークンの分布(平均、標準偏差)
- evalセットがあればその品質スコア
- サービスごとの日次コスト
V4-Flashは deepseek-chat がかつてポイントしていたV3.xの重みとは異なるモデルだ。スワップ後に何が変わったかを把握するためにベースラインが必要だ。
thinkingモードが暗黙的だった箇所を特定する(reasoner)
deepseek-reasoner を使っていたすべてのサービスは、無料でthinkingモードを得ていた。マイグレーション後、thinkingモードはパラメータで明示的にオプトインが必要になる。追加し忘れると、エラーなしに推論能力が静かに失われ、出力の品質が悪化する。これが最も一般的なマイグレーションバグだ。
必要なコード変更
モデル名のスワップ(変更前後の例)
thinkingモードが不要なサービスの場合:
# Before
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# After
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)推論が必要なサービスの場合、変更はより大きい。
reasonerを使っていた箇所にreasoning_effortを追加する
DeepSeek thinkingモードドキュメントでは、thinkingは extra_body で有効化し、reasoning_effort で調整すると規定されている:
# Before
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# After
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)いくつか注意点:
reasoning_effortはhighとmaxを受け付ける。ドキュメントによると、lowとmediumはhighにマップされ、xhighはmaxにマップされる。thinkingモードリクエストのデフォルトはhighだ。- thinkingモードは
temperature、top_p、presence_penalty、frequency_penaltyを静かに無視する。 設定してもエラーにはならない — ただし何も効かない。古いreasonerの設定がtemperature=0.7に依存していたなら、それはすでに無視されていた。
ベースURLと認証 — 変更なし
この部分は本当にシンプルだ。https://api.deepseek.com はそのまま。APIキーもそのまま。OpenAI ChatCompletionsとAnthropic SDKフォーマットの両方がサポートされているので、既存のクライアント設定はそのまま動く。変わるのは model 文字列と(推論の場合)extra_body だけだ。
リグレッションテスト
期待すべき出力の差異
V4-Flashは deepseek-chat がルーティングしていたV3.2の重みとは異なるモデルだ。以下を期待すること:
- 少し異なる冗長性 — V4は同じプロンプトでより長い出力を生成する傾向がある
- コードブロックやリストのフォーマット選択が異なる
- エージェンティックなタスクでの命令追従が向上している
- トークナイザーは同じファミリーだが、トークン数が変わる場合がある
evalセットを実行すること。「互換性あり」が「同一」を意味すると思い込まないこと。
コストベースラインの再確認
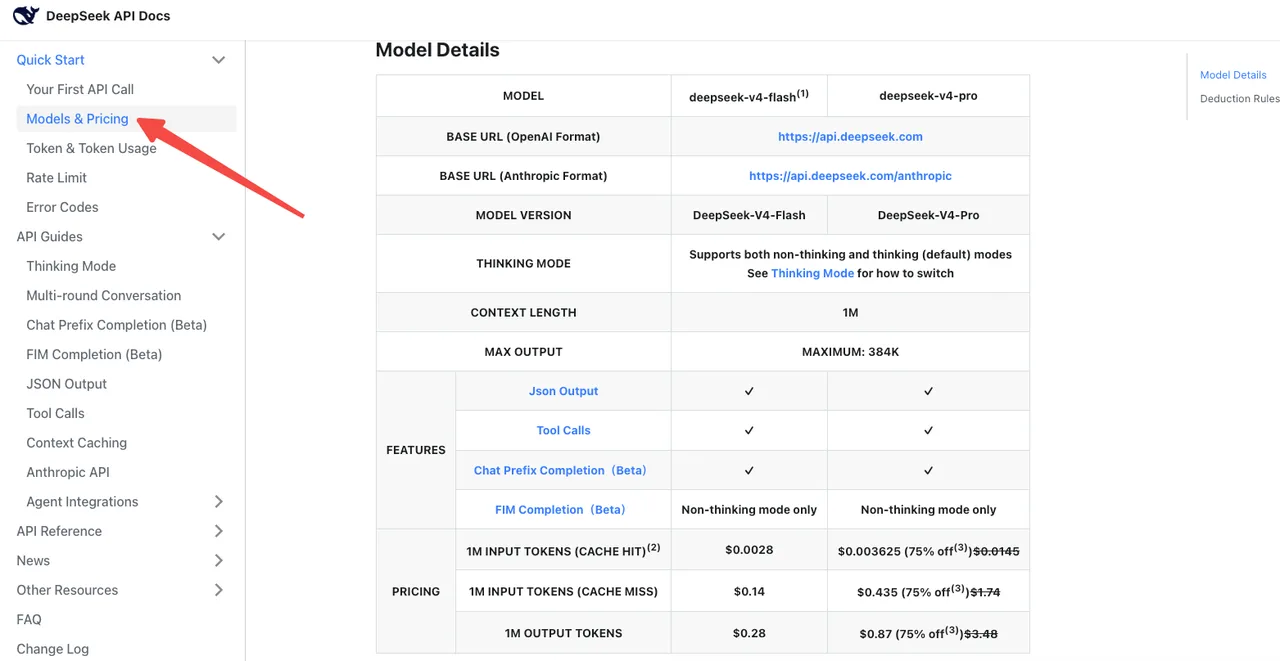
DeepSeek公式価格ページによると、V4-Flashは標準レートで入力/出力100万トークンあたり$0.14 / $0.28だ。V4-Proは$1.74 / $3.48(現在2026/05/05まで75%オフ)。キャッシュヒット価格はラインナップ全体でローンチ価格の1/10に引き下げられた。
罠:V4-ProのthinkingモードはBR老いreasonerよりも劇的に多くの出力トークンを消費する。Artificial AnalysisはV4-Proを「非常に冗長」な出力量とベンチマークしており、平均的な推論トークン数の約4倍を生成する。モデル名の変更が中立に見えても、請求額が上がる可能性がある。
エージェントワークフローの検証
マルチステップのエージェントを実行している場合、チェーン全体を再テストすること。V4のツール呼び出し動作はV3.xよりもClaude Codeに近い。動作していた引数スキーマはほぼ問題ないが、モデルはリトライと自己修正により積極的になっている。つまりタスクあたりのツール呼び出しが増える場合があり、トークンも増える。
ロールアウト戦略
フィーチャーフラグアプローチ
グローバルスワップは行わないこと。サービスごとにモデル名を設定フラグでラップする:
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")サービスごとにロールアウトする。次のサービスに移る前に、各サービスで24〜48時間エラーレートとp99レイテンシを監視する。
カットオーバー時のシャドウトラフィック
高トラフィックのサービスでは、短い期間、古いものと新しいものの両方にリクエストをミラーする。出力をオフラインで比較する。これがユーザーより先にサイレントな品質リグレッションを捉える唯一の方法だ。
よくあるマイグレーションの落とし穴
先週実際に見た5つ:
deepseek-reasoner→deepseek-v4-proをスワップする際にextra_body={"thinking": {"type": "enabled"}}を追加し忘れる。推論品質が落ちるが、エラーは発生しない。- 推論ワークロードに
temperature=0をハードコードし、それが引き続き機能すると思い込む(thinkingモードでは静かに無視される)。 - エイリアス
deepseek-reasonerがV4-Pro ではなくV4-Flash にマップされていたことを忘れる。Proへのマイグレーションは同等の置き換えではなく、アップグレード だ。 - 監視ダッシュボードを更新しない。ダッシュボードがモデル名でグループ化している場合、ラベルを修正するまでV4の呼び出しは古いDeepSeekタイルに表示されない。
- サードパーティのインテグレーションを忘れる。LiteLLM、OpenRouter、またはゲートウェイ経由でプロキシしている場合、OpenRouterのようなプロバイダーはすでにV4ルートを公開している — しかしゲートウェイ設定が古い名前にピンされたままかもしれない。
FAQ
7月24日までにマイグレーションしなかった場合はどうなる?
2026年7月24日 15:59 UTC以降、deepseek-chat または deepseek-reasoner を使ったリクエストは失敗する。公式通知では両方の名前が「完全に廃止され、アクセス不能になる」とされている。延長のアナウンスはない。
deepseek-v4-flashはdeepseek-chatのドロップイン置き換えになる?
非thinkingワークロードでは、ほぼそうだ — 同じスピードティア、同じ価格クラス、同じエンドポイント。基礎となる重みが異なるため出力は若干異なるので、evalを再実行すること。thinkingワークロードでは、extra_body のthinkingパラメータを明示的に追加する必要がある。
reasonerの動作を維持するにはどうすればいい?
同じコンピュートティアを維持したい場合は、thinkingモードを有効にした deepseek-v4-flash を使う(これは deepseek-reasoner がすでに行っていたことと一致する)。品質のアップグレードが必要なら、thinkingを有効にした deepseek-v4-pro を使う。両方とも extra_body={"thinking": {"type": "enabled"}} が必要だ。
請求構造は変わる?
トークンあたりの課金モデルは同じだ。レートは異なる — Flashは古い deepseek-chat レートより安く、Proは高いが現在割引中だ。キャッシュヒット価格は標準レートの10%になった。thinkingモードでの出力トークン増大に注意すること。
古いものと新しいものを並行してテストできる?
できる。レガシーと新しいモデル名は両方とも7月24日まで同時に動作する。フィーチャーフラグを使ってトラフィックの一定割合をV4にルーティングして比較する。これが最もリスクの低いマイグレーションパスだ。
明日本番にデプロイするなら、最も安全な動きは最小限のものだ:まず deepseek-chat → deepseek-v4-flash をスワップし、推論ワークロードは最後に残し、実際のevalセットでベンチマークするまでV4-Proには手をつけないこと。締め切りは本物だが、3ヶ月後でもある — 慎重に進める時間はある。7月末に痛い目を見るチームは、それを1行のPRとして扱い、リグレッションパスをスキップしたチームだ。そんなチームにならないようにしよう。
過去の投稿:





