Migrasi API DeepSeek V4: Perbarui Nama Model Sebelum Juli
DeepSeek-chat dan deepseek-reasoner akan dihentikan pada 24 Juli 2026. Panduan langkah demi langkah untuk migrasi ke deepseek-v4-pro dan deepseek-v4-flash beserta perbandingan kode.

Saya menarik log produksi pada Senin pagi dan menghitung 14.000 panggilan yang masih mengarah ke deepseek-chat. Tiga bulan dari sekarang, setiap satu dari panggilan itu akan mengembalikan error 404. Itulah situasi yang dihadapi banyak tim tanpa mereka sadari — DeepSeek mengumumkan deprecation, kalender terus berjalan, dan tidak ada satu pun dalam rotasi on-call yang meneruskan changelog kepada orang-orang yang sebenarnya mengelola integrasi tersebut. Saya sudah menjalankan migrasi di stack kami sendiri minggu lalu, jadi ini adalah versi dengan diff yang berhasil, bukan versi yang hanya merangkum pengumuman. Nama saya Dora, saya menulis catatan infrastruktur untuk tim backend, dan versi singkatnya adalah: ini adalah perubahan kode satu baris, tapi pengujian di sekitarnya adalah tempat di mana segalanya bisa salah jika Anda melewatinya.
Sudah menggunakan DeepSeek? Beralih ke WaveSpeedAI tanpa perubahan kode — SDK OpenAI yang sama, cukup ubah base URL dan key. DeepSeek V3.2 API → · DeepSeek R1 API →
Tanggal tetapnya adalah 24 Juli 2026, 15:59 UTC. Setelah itu, deepseek-chat dan deepseek-reasoner akan mengembalikan error. Tidak ada perpanjangan yang sedang dibahas. Lakukan migrasi sekarang, selesaikan pengujian di bulan Mei, sisakan Juni untuk yang terlambat.
Apa yang Berubah dan Kapan
Timeline deprecation: deepseek-chat / deepseek-reasoner dihentikan pada 2026-07-24
DeepSeek V4 diluncurkan pada 24 April 2026, dan catatan rilis resmi DeepSeek V4 menyatakan bahwa kedua nama model lama akan “sepenuhnya dihentikan dan tidak dapat diakses” setelah 24 Juli 2026, 15:59 UTC. Itu adalah batas waktu keras, bukan sekadar peringatan lunak. Permintaan yang menggunakan nama lama setelah timestamp tersebut akan gagal.
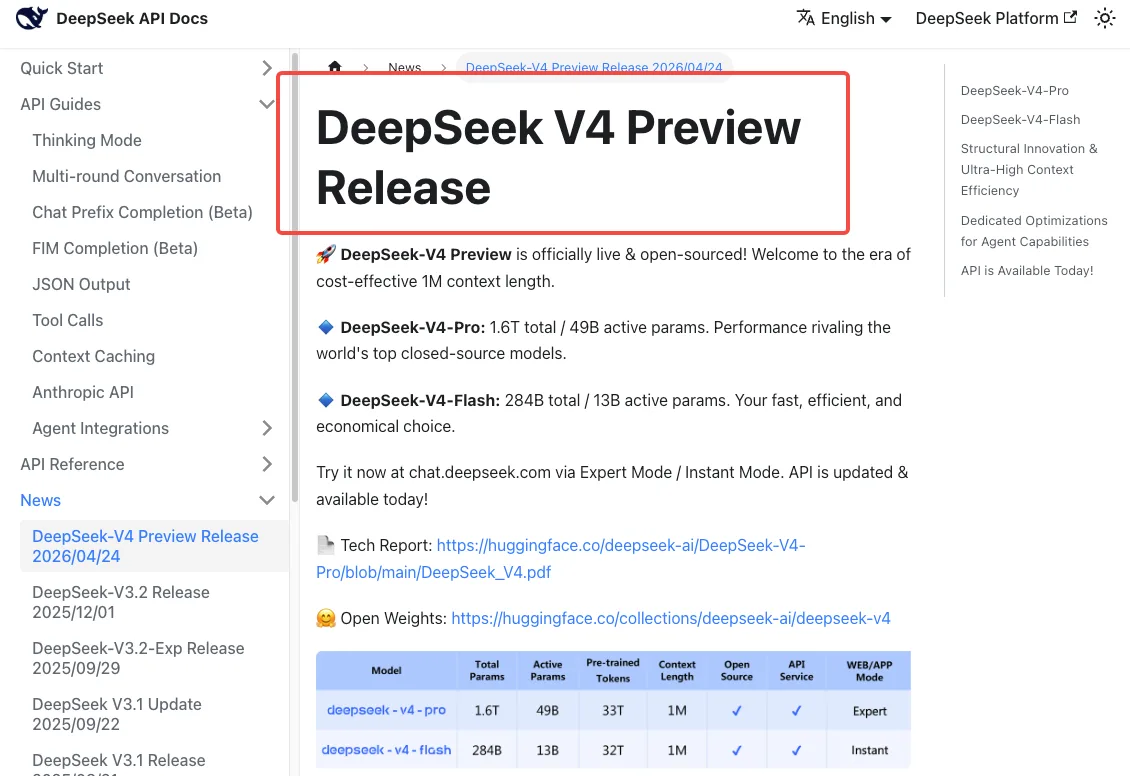
Selama periode tenggang — sekarang hingga 24 Juli — kedua nama lama masih berfungsi, tetapi secara transparan diarahkan ke V4-Flash. Jadi Anda sudah menggunakan V4 meskipun belum memperbarui kode Anda.
Nama model baru: deepseek-v4-pro, deepseek-v4-flash
Dua ID model baru menggantikan alias lama:
deepseek-v4-pro— 1,6T total parameter, 49B aktif, context window 1M, output maksimal 384K. Pilihan yang lebih berat untuk reasoning.deepseek-v4-flash— 284B total, 13B aktif, context 1M yang sama. Lebih murah dan lebih cepat, cocok untuk sebagian besar beban kerja produksi.
Keduanya mendukung mode thinking dan non-thinking melalui ID model yang sama. Anda tidak lagi memilih reasoning dengan memilih model terpisah — Anda mengaktifkannya melalui parameter. Inilah bagian yang merusak migrasi yang dilakukan sembarangan.
Pemetaan transisi selama periode tenggang
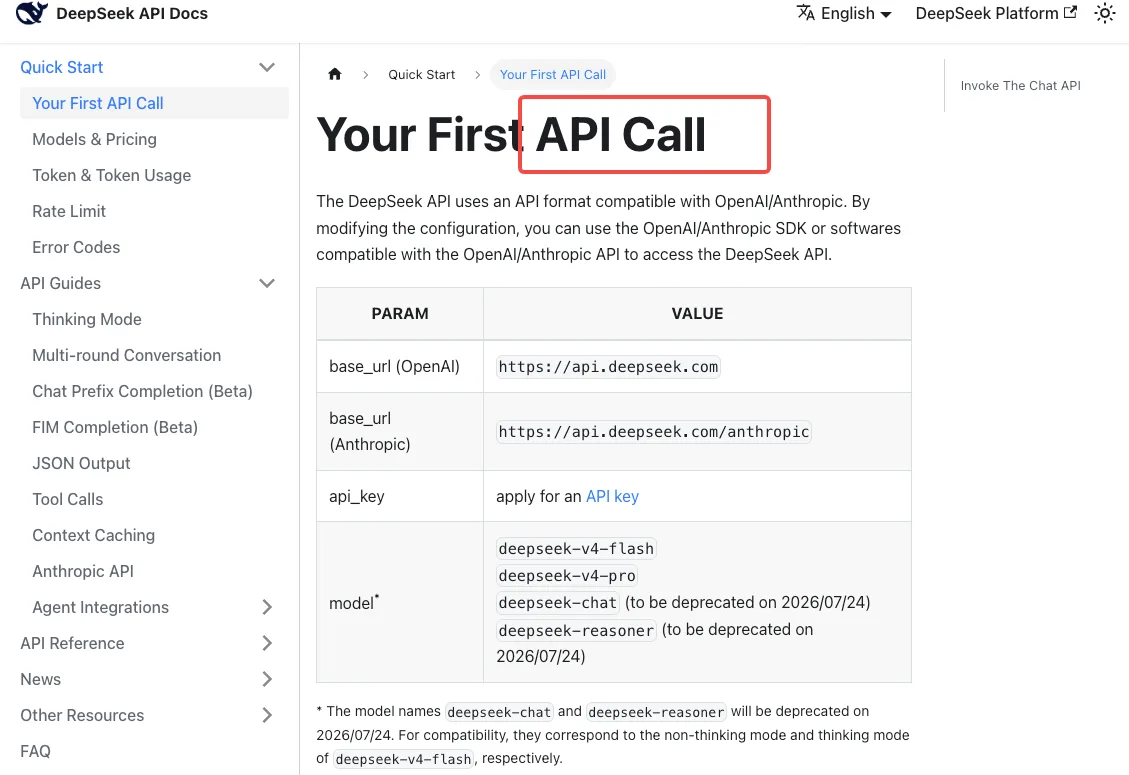
Berdasarkan dokumentasi quickstart API DeepSeek, pemetaan kompatibilitas saat ini adalah:
deepseek-chat→deepseek-v4-flash(mode non-thinking)deepseek-reasoner→deepseek-v4-flash(mode thinking)
Perhatikan artinya: jika Anda menggunakan deepseek-reasoner, Anda sudah berjalan di Flash, bukan Pro. Jika beban kerja reasoning Anda terasa sedikit berbeda dalam seminggu terakhir, itulah alasannya. Untuk mendapatkan reasoning tingkat Pro, Anda harus secara eksplisit bermigrasi ke deepseek-v4-pro — alias tidak pernah mengarahkan Anda ke sana.
Checklist Pra-Migrasi
Inventarisasi setiap layanan yang memanggil API DeepSeek
Grep seluruh monorepo. Kedua string berikut:
grep -rn "deepseek-chat\|deepseek-reasoner" .Jangan percaya ingatan Anda tentang layanan mana yang menggunakannya. Saya menemukan dua cron job dan satu webhook handler yang sudah saya lupakan keberadaannya. Periksa juga template .env, konfigurasi deploy, file IaC, dan tabel routing LLM gateway apa pun. Jika Anda menggunakan proxy seperti LiteLLM atau n1n.ai, periksa di sana juga — log perubahan DeepSeek di api-docs.deepseek.com mengkonfirmasi bahwa nama lama dijadwalkan untuk penghentian penuh, bukan sekadar peringatan deprecation, sehingga apa pun yang masih menggunakannya akan gagal secara keras.
Ambil baseline latensi dan kualitas saat ini
Sebelum Anda mengubah satu karakter pun, buat snapshot seperti apa “berfungsi dengan baik” hari ini:
- Latensi p50 / p95 / p99 per endpoint
- Distribusi token output (rata-rata, std)
- Skor kualitas pada eval set Anda, jika ada
- Biaya harian per layanan
V4-Flash berperilaku sedikit berbeda dari bobot V3.x yang dulu ditunjuk oleh deepseek-chat. Anda membutuhkan baseline agar bisa mengetahui apa yang berubah setelah penggantian.
Identifikasi di mana mode thinking bersifat implisit (reasoner)
Setiap layanan yang menggunakan deepseek-reasoner mendapatkan mode thinking secara gratis. Setelah migrasi, mode thinking bersifat opt-in melalui parameter. Jika Anda lupa menambahkannya, Anda secara diam-diam kehilangan kemampuan reasoning dan output Anda memburuk tanpa ada error apa pun. Ini adalah bug migrasi yang paling umum terjadi.
Perubahan Kode yang Diperlukan
Penggantian nama model (contoh sebelum/sesudah)
Untuk layanan yang tidak memerlukan mode thinking:
python
# Sebelum
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# Sesudah
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Untuk layanan yang memerlukan reasoning, perubahannya lebih besar.
Menambahkan reasoning_effort di mana reasoner digunakan
Dokumentasi mode thinking DeepSeek menetapkan bahwa thinking diaktifkan melalui extra_body dan disetel dengan reasoning_effort:
python
# Sebelum
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# Sesudah
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Beberapa hal yang perlu diperhatikan:
reasoning_effortmenerimahighdanmax. Berdasarkan dokumentasi,lowdanmediumdipetakan kehigh, danxhighdipetakan kemax. Default untuk permintaan mode thinking adalahhigh.- Mode thinking secara diam-diam mengabaikan
temperature,top_p,presence_penalty, danfrequency_penalty. Menyetelnya tidak akan error — hanya tidak akan melakukan apa-apa. Jika pengaturan reasoner lama Anda bergantung padatemperature=0.7, itu sudah diabaikan sejak awal.
Base URL dan autentikasi — tidak berubah
Bagian ini benar-benar sederhana. https://api.deepseek.com tetap sama. API key Anda tetap sama. Format OpenAI ChatCompletions dan Anthropic SDK keduanya didukung, sehingga pengaturan client Anda yang sudah ada tetap berfungsi. Hanya string model dan (untuk reasoning) extra_body yang berubah.
Pengujian Regresi
Perbedaan bentuk output yang perlu Anda antisipasi
V4-Flash adalah model yang berbeda dari bobot V3.2 yang dulu ditunjuk oleh deepseek-chat. Perkirakan:
- Verbositas yang sedikit berbeda — V4 cenderung menghasilkan output yang lebih panjang pada prompt yang sama
- Pilihan pemformatan yang berbeda untuk blok kode dan daftar
- Instruction-following yang lebih baik pada tugas agentic
- Tokenizer dari keluarga yang sama, tetapi jumlah token bisa bergeser
Jalankan eval set Anda. Jangan asumsikan “kompatibel” berarti “identik.”
Pemeriksaan ulang baseline biaya
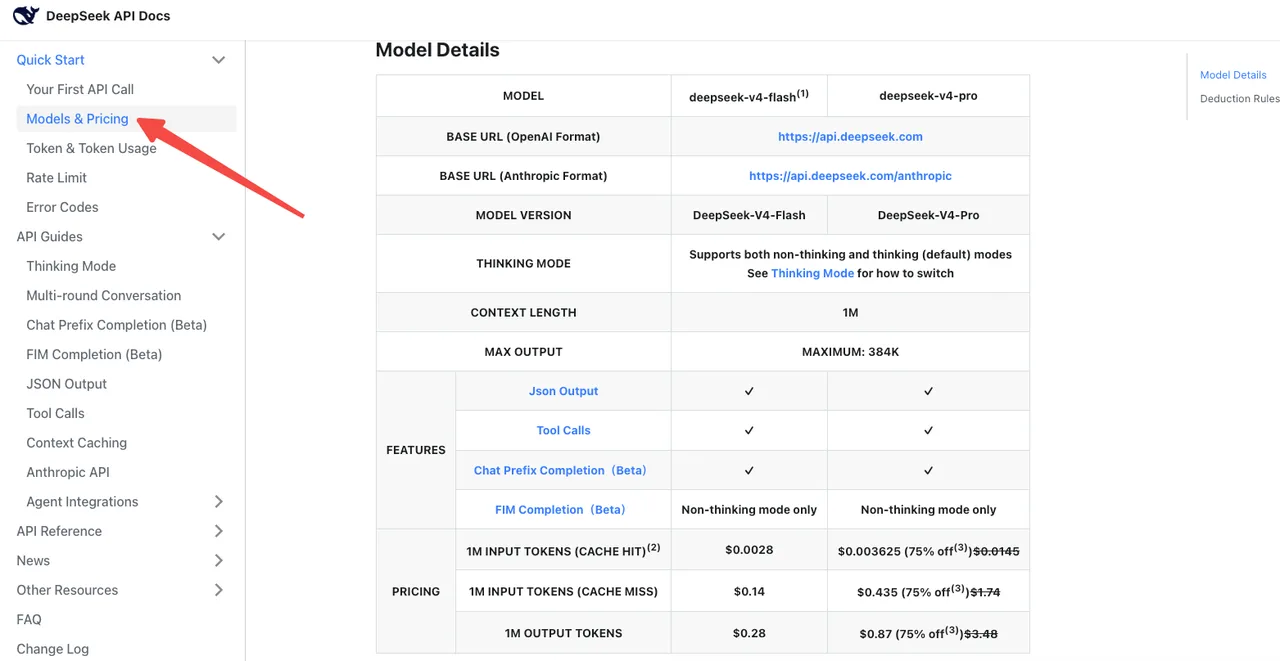
Berdasarkan halaman harga resmi DeepSeek, V4-Flash adalah $0,14 / $0,28 per 1M token input/output pada tarif standar. V4-Pro adalah $1,74 / $3,48 (saat ini diskon 75% hingga 2026/05/05). Harga cache-hit telah dikurangi menjadi 1/10 dari harga peluncuran di seluruh lini produk.
Jebakannya: mode thinking pada V4-Pro membakar jauh lebih banyak token output dibandingkan reasoner lama. Artificial Analysis membenchmark V4-Pro pada volume output “sangat verbose”, menghasilkan kira-kira 4x rata-rata jumlah token reasoning. Tagihan Anda bisa naik bahkan jika penggantian nama model Anda terlihat netral.
Validasi alur kerja agen
Jika Anda menjalankan agen multi-langkah, uji ulang seluruh rantainya. Perilaku tool-calling V4 lebih mendekati Claude Code dibandingkan V3.x. Skema argumen yang sudah berfungsi sebagian besar baik-baik saja, tetapi model ini lebih agresif dalam mencoba ulang dan mengoreksi diri, yang berarti kadang-kadang lebih banyak tool call per tugas — dan lebih banyak token.
Strategi Rollout
Pendekatan feature flag
Jangan lakukan penggantian global. Bungkus nama model dalam config flag per layanan:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Rollout layanan per layanan. Pantau tingkat error dan latensi p99 selama 24-48 jam per layanan sebelum melanjutkan.
Shadow traffic selama cutover
Untuk layanan dengan traffic tinggi, cerminkan permintaan ke lama dan baru dalam jendela waktu singkat. Bandingkan output secara offline. Ini adalah satu-satunya cara untuk mendeteksi regresi kualitas yang diam-diam sebelum pengguna merasakannya.
Jebakan Umum Migrasi
Lima hal yang benar-benar saya temui minggu lalu:
- Mengganti
deepseek-reasoner→deepseek-v4-protanpa menambahkanextra_body={"thinking": {"type": "enabled"}}. Kualitas reasoning turun, tidak ada error yang muncul. - Hardcoding
temperature=0untuk beban kerja reasoning dan berasumsi itu masih berfungsi (diabaikan secara diam-diam dalam mode thinking). - Lupa bahwa alias
deepseek-reasonerhanya dipetakan ke V4-Flash, bukan V4-Pro. Migrasi ke Pro adalah sebuah upgrade, bukan penggantian setara. - Tidak memperbarui dashboard monitoring. Jika dashboard Anda mengelompokkan berdasarkan nama model, panggilan V4 tidak akan muncul di tile DeepSeek lama Anda sampai Anda memperbaiki labelnya.
- Melupakan integrasi pihak ketiga. Jika Anda menggunakan proxy melalui LiteLLM, OpenRouter, atau gateway apa pun, provider seperti OpenRouter sudah mempublikasikan rute V4 — tetapi konfigurasi gateway Anda mungkin masih menggunakan nama lama.
FAQ
Apa yang terjadi jika saya tidak bermigrasi sebelum 24 Juli?
Setelah 24 Juli 2026, 15:59 UTC, permintaan yang menggunakan deepseek-chat atau deepseek-reasoner akan gagal. Pemberitahuan resmi menyatakan bahwa kedua nama akan “sepenuhnya dihentikan dan tidak dapat diakses.” Tidak ada perpanjangan yang diumumkan.
Apakah deepseek-v4-flash merupakan pengganti langsung untuk deepseek-chat?
Untuk beban kerja non-thinking, sebagian besar ya — tier kecepatan yang sama, kelas harga yang sama, endpoint yang sama. Output sedikit berbeda karena bobot yang mendasarinya berbeda, jadi jalankan ulang eval Anda. Untuk beban kerja thinking, Anda perlu menambahkan parameter thinking extra_body secara eksplisit.
Bagaimana cara mempertahankan perilaku reasoner?
Gunakan deepseek-v4-flash dengan mode thinking diaktifkan jika Anda ingin tetap di tier komputasi yang sama (ini sesuai dengan apa yang sudah dilakukan deepseek-reasoner). Gunakan deepseek-v4-pro dengan thinking diaktifkan jika Anda menginginkan peningkatan kualitas. Keduanya memerlukan extra_body={"thinking": {"type": "enabled"}}.
Apakah struktur penagihan saya akan berubah?
Model penagihan per token tetap sama. Tarif berbeda — Flash lebih murah dari tarif deepseek-chat lama, Pro lebih mahal tetapi saat ini sedang diskon. Harga cache-hit sekarang 10% dari tarif standar. Waspadai inflasi token output dalam mode thinking.
Bisakah saya menguji lama dan baru secara paralel?
Ya. Nama model lama dan baru keduanya berfungsi secara bersamaan hingga 24 Juli. Gunakan feature flag untuk mengarahkan sebagian persentase traffic ke V4 dan bandingkan. Ini adalah jalur migrasi dengan risiko paling rendah.
Jika Anda deploy ke produksi besok, langkah paling aman adalah langkah terkecil: ganti deepseek-chat → deepseek-v4-flash terlebih dahulu, tinggalkan beban kerja reasoning untuk terakhir, dan jangan sentuh V4-Pro sampai Anda sudah melakukan benchmark terhadap eval set aktual Anda. Batas waktunya nyata tetapi masih tiga bulan lagi — ada waktu untuk melakukan ini dengan hati-hati. Tim yang terkena masalah di akhir Juli adalah mereka yang memperlakukannya sebagai PR satu baris dan melewati regression pass. Jangan jadi tim itu.
Postingan sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8
API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi
Harga GPT-5.4 Mini: Biaya Input, Cache & Output
API MAI-Image-2.5: Yang Perlu Diketahui Para Developer