Migration API DeepSeek V4 : Mettez à jour les noms de modèles avant juillet
DeepSeek-chat et deepseek-reasoner seront retirés le 24 juillet 2026. Migration étape par étape vers deepseek-v4-pro et deepseek-v4-flash avec des diffs de code.

J’ai consulté les logs de prod un lundi matin et compté 14 000 appels ciblant encore deepseek-chat. Dans trois mois, chacun d’eux retourne une 404. C’est la situation dans laquelle beaucoup d’équipes se retrouvent sans le savoir — DeepSeek a annoncé la dépréciation, le calendrier a avancé, et personne dans la rotation d’astreinte n’a transmis le changelog aux personnes qui gèrent réellement l’intégration. J’ai effectué la migration sur notre propre stack la semaine dernière, donc voici la version avec les diffs qui ont fonctionné, pas celle qui paraphrase l’annonce. Je m’appelle Dora, j’écris des notes d’infrastructure pour les équipes backend, et en résumé : c’est une modification d’une ligne de code, mais c’est dans les tests autour de ça que tout déraille si vous les sautez.
Déjà sur DeepSeek ? Passez à WaveSpeedAI sans modifier votre code — même SDK OpenAI, changez juste l’URL de base et la clé. API DeepSeek V3.2 → · API DeepSeek R1 →
La date limite est le 24 juillet 2026, 15h59 UTC. Après cela, deepseek-chat et deepseek-reasoner retournent des erreurs. Aucune prolongation n’est en discussion. Migrez maintenant, terminez les tests en mai, laissez juin pour les retardataires.
Ce qui change et quand
Calendrier de dépréciation : extinction de deepseek-chat / deepseek-reasoner le 24/07/2026
DeepSeek V4 a été lancé le 24 avril 2026, et les notes de version officielles de DeepSeek V4 indiquent que les deux anciens noms de modèles seront « entièrement retirés et inaccessibles » après le 24 juillet 2026, 15h59 UTC. C’est une coupure nette, pas un simple avertissement. Les requêtes utilisant les anciens noms après ce timestamp échouent.
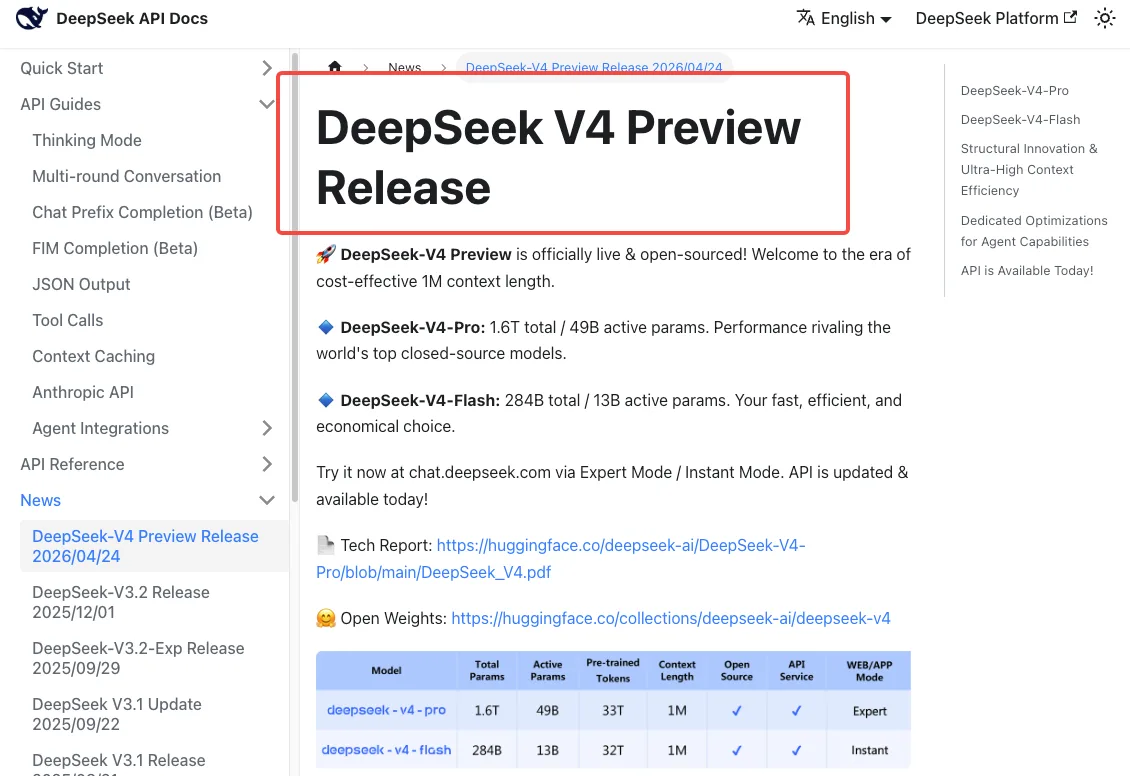
Pendant la période de grâce — maintenant jusqu’au 24 juillet — les deux anciens noms continuent de fonctionner, mais ils sont redirigés de façon transparente vers V4-Flash. Vous êtes donc déjà sur V4 que vous ayez mis à jour votre code ou non.
Nouveaux noms de modèles : deepseek-v4-pro, deepseek-v4-flash
Deux nouveaux identifiants de modèles remplacent les anciens alias :
deepseek-v4-pro— 1,6T paramètres totaux, 49B actifs, fenêtre de contexte 1M, sortie max 384K. L’option axée sur le raisonnement intensif.deepseek-v4-flash— 284B total, 13B actifs, même contexte 1M. Moins cher et plus rapide, adapté à la plupart des charges de travail en production.
Les deux supportent les modes avec et sans réflexion via le même identifiant de modèle. Vous ne choisissez plus le raisonnement en sélectionnant un modèle séparé — vous le basculez via des paramètres. C’est la partie qui fait échouer les migrations naïves.
Correspondance transitoire pendant la période de grâce
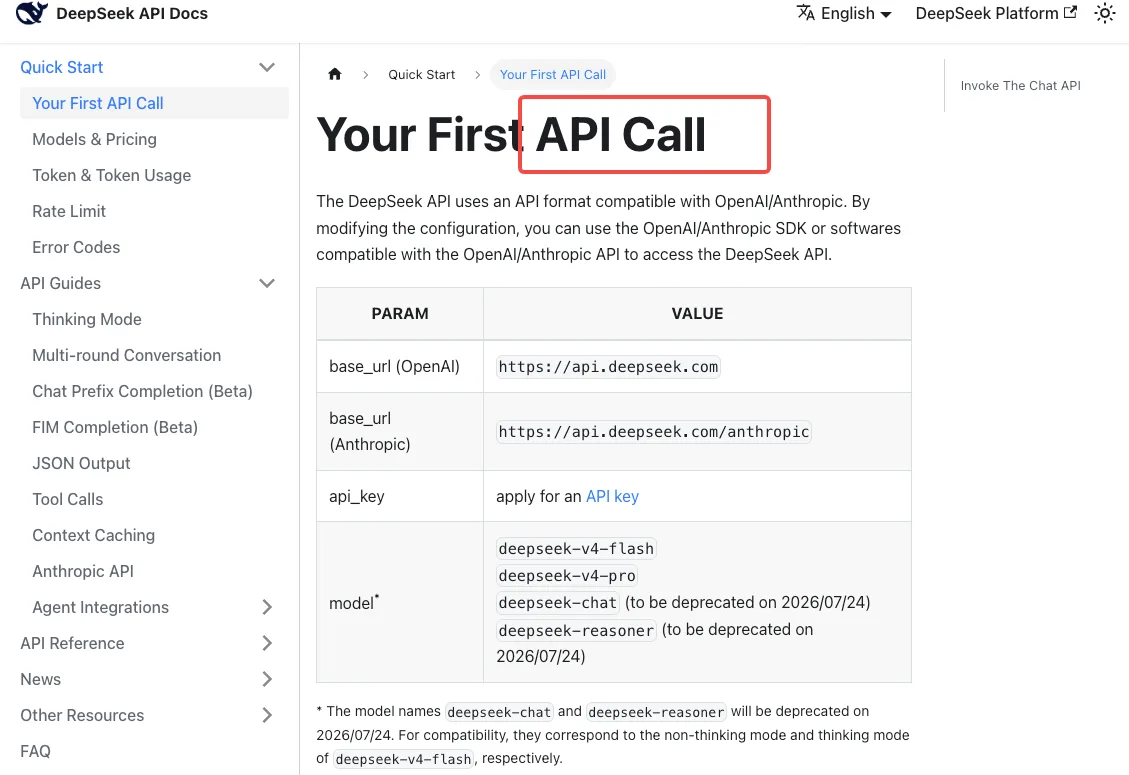
Selon la documentation quickstart de l’API DeepSeek, la correspondance de compatibilité actuelle est :
deepseek-chat→deepseek-v4-flash(mode sans réflexion)deepseek-reasoner→deepseek-v4-flash(mode avec réflexion)
Notez ce que cela implique : si vous utilisiez deepseek-reasoner, vous êtes déjà en train d’exécuter Flash, pas Pro. Si vos charges de travail de raisonnement vous ont semblé légèrement différentes la semaine dernière, c’est pour ça. Pour obtenir le raisonnement de niveau Pro, vous devez migrer explicitement vers deepseek-v4-pro — l’alias ne vous y redirige jamais.
Liste de contrôle pré-migration
Inventorier chaque service qui appelle l’API DeepSeek
Effectuez un grep sur tout le monorepo. Les deux chaînes :
grep -rn "deepseek-chat\|deepseek-reasoner" .Ne faites pas confiance à votre mémoire sur les services qui l’utilisent. J’ai trouvé deux tâches cron et un gestionnaire de webhook que j’avais oubliés. Vérifiez aussi les templates .env, les configs de déploiement, les fichiers IaC, et les tables de routage des passerelles LLM. Si vous utilisez un proxy comme LiteLLM ou n1n.ai, vérifiez-y aussi — le journal des modifications DeepSeek sur api-docs.deepseek.com confirme que les anciens noms sont prévus pour une discontinuation totale, pas juste des avertissements de dépréciation, donc tout ce qui les utilise encore échouera brutalement.
Capturer les baselines actuelles de latence et de qualité
Avant de changer une seule cha îne, prenez un instantané de ce à quoi ressemble « fonctionnel » aujourd’hui :
îne, prenez un instantané de ce à quoi ressemble « fonctionnel » aujourd’hui :
- Latence p50 / p95 / p99 par endpoint
- Distribution des tokens de sortie (moyenne, écart-type)
- Score de qualité sur votre ensemble d’évaluation, si vous en avez un
- Coût journalier par service
V4-Flash se comporte légèrement différemment des poids V3.x vers lesquels deepseek-chat pointait. Vous voulez une baseline pour pouvoir identifier ce qui a changé après le swap.
Identifier où le mode de réflexion était implicite (reasoner)
Chaque service utilisant deepseek-reasoner bénéficiait du mode de réflexion gratuitement. Après la migration, le mode de réflexion est opt-in via un paramètre. Si vous oubliez de l’ajouter, vous perdez silencieusement votre capacité de raisonnement et vos sorties se dégradent sans aucune erreur. C’est le bug de migration le plus fréquent.
Modifications de code requises
Remplacement du nom de modèle (exemples avant/après)
Pour les services qui n’ont pas besoin du mode de réflexion :
python
# Avant
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# Après
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Pour les services qui ont besoin du raisonnement, le changement est plus important.
Ajout de reasoning_effort là où reasoner était utilisé
La documentation sur le mode de réflexion DeepSeek spécifie que la réflexion est activée via extra_body et réglée avec reasoning_effort :
python
# Avant
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# Après
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Quelques points à surveiller :
reasoning_effortacceptehighetmax. Selon la documentation,lowetmediumsont mappés surhigh, etxhighest mappé surmax. La valeur par défaut pour les requêtes en mode réflexion esthigh.- Le mode de réflexion ignore silencieusement
temperature,top_p,presence_penaltyetfrequency_penalty. Les définir ne génère pas d’erreur — cela n’a simplement aucun effet. Si votre ancienne configuration de reasoner dépendait detemperature=0.7, celle-ci était déjà ignorée.
URL de base et authentification — inchangées
Cette partie est vraiment simple. https://api.deepseek.com reste identique. Votre clé API reste identique. Les formats SDK OpenAI ChatCompletions et Anthropic sont tous deux supportés, donc votre configuration client existante continue de fonctionner. Seuls la chaîne model et (pour le raisonnement) le extra_body changent.
Tests de régression
Différences de forme de sortie à anticiper
V4-Flash est un modèle différent des poids V3.2 vers lesquels deepseek-chat routait. Attendez-vous à :
- Une verbosité légèrement différente — V4 tend à produire des sorties plus longues pour le même prompt
- Des choix de formatage différents pour les blocs de code et les listes
- Un meilleur suivi des instructions pour les tâches agentiques
- Le tokenizer appartient à la même famille, mais les comptages de tokens peuvent varier
Exécutez votre ensemble d’évaluation. Ne supposez pas que « compatible » signifie « identique ».
Revérification de la baseline des coûts
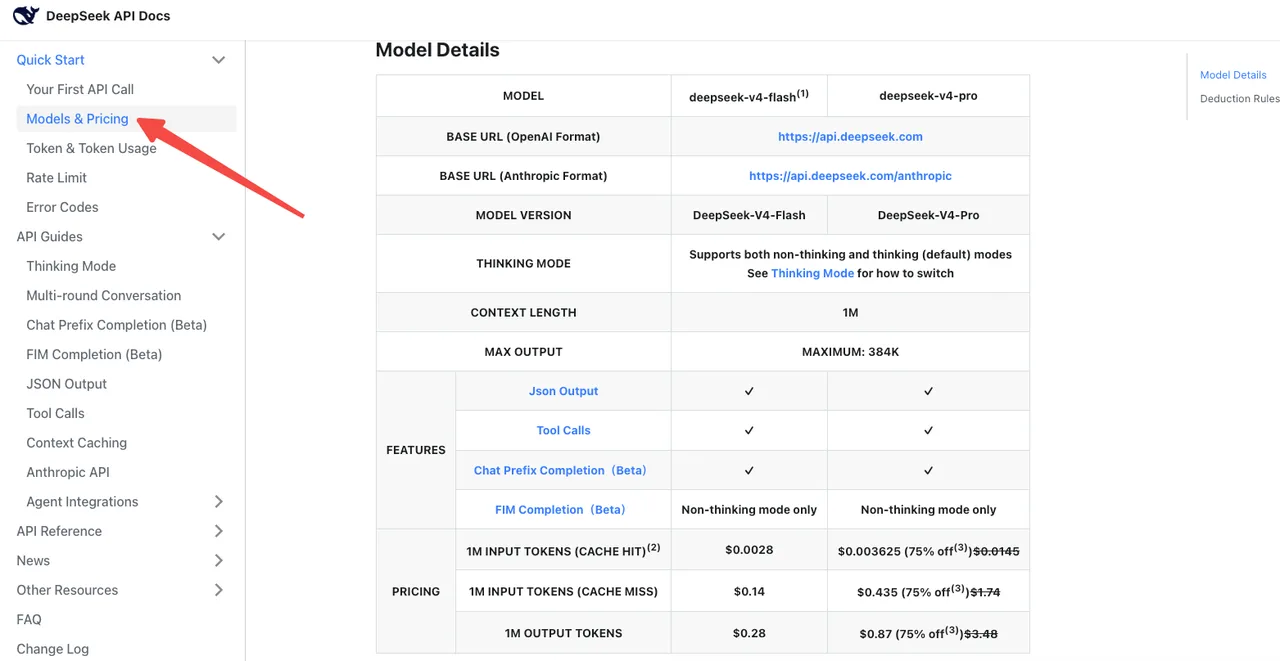
Selon la page de tarification officielle DeepSeek, V4-Flash est à 0,14 $ / 0,28 $ par million de tokens d’entrée/sortie aux tarifs standard. V4-Pro est à 1,74 $ / 3,48 $ (actuellement réduit de 75 % jusqu’au 05/05/2026). La tarification avec cache-hit a été réduite à 1/10 du prix de lancement sur toute la gamme.
Le piège : le mode de réflexion sur V4-Pro consomme dramatiquement plus de tokens de sortie que l’ancien reasoner. Artificial Analysis a mesuré V4-Pro comme produisant des volumes de sortie « très verbeux », générant environ 4 fois le nombre moyen de tokens de raisonnement. Votre facture peut augmenter même si votre changement de nom de modèle paraît neutre.
Validation des workflows agentiques
Si vous exécutez des agents multi-étapes, retestez la chaîne complète. Le comportement d’appel d’outils de V4 est plus proche de Claude Code que V3.x ne l’était. Les schémas d’arguments qui fonctionnaient sont globalement corrects, mais le modèle est plus agressif dans les nouvelles tentatives et l’auto-correction, ce qui signifie parfois plus d’appels d’outils par tâche — et plus de tokens.
Stratégie de déploiement
Approche par feature flag
Ne faites pas un swap global. Encapsulez le nom de modèle dans un flag de configuration par service :
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Déployez service par service. Surveillez les taux d’erreurs et la latence p99 pendant 24 à 48 heures par service avant de passer au suivant.
Trafic miroir pendant la bascule
Pour les services à fort trafic, dupliquez les requêtes vers l’ancien et le nouveau pendant une courte fenêtre. Comparez les sorties hors ligne. C’est le seul moyen de détecter les régressions de qualité silencieuses avant les utilisateurs.
Pièges courants de la migration
Les cinq que j’ai réellement observés la semaine dernière :
- Remplacer
deepseek-reasoner→deepseek-v4-prosans ajouterextra_body={"thinking": {"type": "enabled"}}. La qualité du raisonnement chute, aucune erreur ne se déclenche. - Forcer
temperature=0pour les charges de travail de raisonnement en supposant que ça fonctionne encore (c’est silencieusement ignoré en mode de réflexion). - Oublier que l’alias
deepseek-reasonerne pointait que vers V4-Flash, pas V4-Pro. Migrer vers Pro est une mise à niveau, pas un remplacement équivalent. - Ne pas mettre à jour les tableaux de bord de monitoring. Si votre dashboard regroupe par nom de modèle, les appels V4 n’apparaissent pas sous votre ancienne tuile DeepSeek tant que vous n’avez pas corrigé le label.
- Oublier les intégrations tierces. Si vous routez via LiteLLM, OpenRouter, ou une passerelle quelconque, des fournisseurs comme OpenRouter ont déjà publié des routes V4 — mais votre config de passerelle pointe peut-être encore sur l’ancien nom.
FAQ
Que se passe-t-il si je ne migre pas avant le 24 juillet ?
Après le 24 juillet 2026, 15h59 UTC, les requêtes utilisant deepseek-chat ou deepseek-reasoner échouent. L’avis officiel indique que les deux noms seront « entièrement retirés et inaccessibles ». Aucune prolongation n’est annoncée.
deepseek-v4-flash est-il un remplacement direct de deepseek-chat ?
Pour les charges de travail sans réflexion, globalement oui — même niveau de vitesse, même classe tarifaire, même endpoint. Les sorties diffèrent légèrement car les poids sous-jacents sont différents, donc relancez vos évaluations. Pour les charges de travail de réflexion, vous devez ajouter explicitement le paramètre extra_body thinking.
Comment préserver le comportement du reasoner ?
Utilisez deepseek-v4-flash avec le mode de réflexion activé si vous souhaitez rester sur le même niveau de calcul (cela correspond à ce que deepseek-reasoner faisait déjà). Utilisez deepseek-v4-pro avec la réflexion activée si vous voulez une amélioration de qualité. Les deux nécessitent extra_body={"thinking": {"type": "enabled"}}.
Ma structure de facturation va-t-elle changer ?
Le modèle de facturation au token est identique. Les tarifs diffèrent — Flash est moins cher que les anciens tarifs de deepseek-chat, Pro est plus cher mais actuellement remisé. La tarification avec cache-hit est désormais à 10 % des tarifs standard. Surveillez l’inflation des tokens de sortie en mode de réflexion.
Puis-je tester l’ancien et le nouveau en parallèle ?
Oui. Les noms de modèles legacy et nouveaux fonctionnent simultanément jusqu’au 24 juillet. Utilisez un feature flag pour router un pourcentage du trafic vers V4 et comparez. C’est le chemin de migration le moins risqué.
Si vous mettez en production demain, le mouvement le plus sûr est le plus petit : remplacez d’abord deepseek-chat → deepseek-v4-flash, laissez les charges de travail de raisonnement pour la fin, et ne touchez pas V4-Pro tant que vous ne l’avez pas benchmarké contre votre ensemble d’évaluation réel. La deadline est réelle mais elle est aussi à trois mois — il y a le temps de faire ça soigneusement. Les équipes qui seront touchées fin juillet seront celles qui l’ont traité comme une PR d’une ligne et ont sauté la passe de régression. Ne soyez pas ces équipes.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir