Migración de la API de DeepSeek V4: Actualiza los Nombres de Modelos Antes de Julio
DeepSeek-chat y deepseek-reasoner se retiran el 24 de julio de 2026. Migración paso a paso a deepseek-v4-pro y deepseek-v4-flash con diferencias de código.

Revisé los logs de producción un lunes por la mañana y conté 14.000 llamadas que seguían apuntando a deepseek-chat. Dentro de tres meses, cada una de esas devolverá un 404. Esa es la situación en la que muchos equipos se encuentran sin saberlo: DeepSeek anunció la deprecación, el calendario avanzó, y nadie en la rotación de guardia reenvió el changelog a las personas que realmente son dueñas de la integración. Ejecuté la migración en nuestra propia infraestructura la semana pasada, así que esto es la versión con los diffs que funcionaron, no la versión que parafrasea el anuncio. Me llamo Dora, escribo notas de infraestructura para equipos de backend, y la versión corta es: es un cambio de una línea de código, pero las pruebas alrededor de él son donde todo sale mal si te las saltas.
¿Ya usas DeepSeek? Cambia a WaveSpeedAI sin cambios de código — mismo SDK de OpenAI, solo cambia la URL base y la clave. DeepSeek V3.2 API → · DeepSeek R1 API →
La fecha límite es 24 de julio de 2026, 15:59 UTC. Después de eso, deepseek-chat y deepseek-reasoner devuelven errores. No hay ninguna extensión en discusión. Migra ahora, termina las pruebas en mayo, deja junio para los rezagados.
Qué cambia y cuándo
Cronograma de deprecación: deepseek-chat / deepseek-reasoner se retiran el 2026-07-24
DeepSeek V4 se lanzó el 24 de abril de 2026, y las notas oficiales de la versión de DeepSeek V4 indican que ambos nombres de modelos heredados serán “completamente retirados e inaccesibles” después del 24 de julio de 2026, 15:59 UTC. Ese es un corte definitivo, no una advertencia suave. Las solicitudes que usen los nombres antiguos después de esa marca de tiempo fallarán.
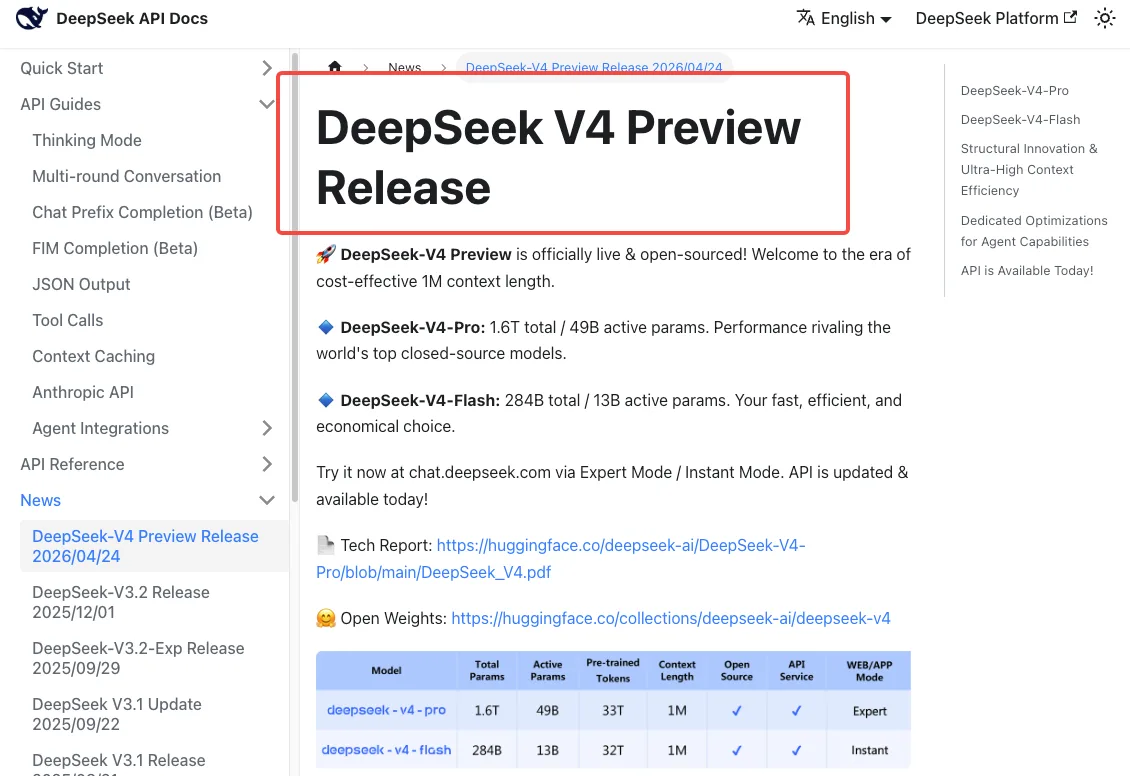
Durante el período de gracia — desde ahora hasta el 24 de julio — ambos nombres heredados siguen funcionando, pero son enrutados de forma transparente a V4-Flash. Así que ya estás en V4 hayas actualizado tu código o no.
Nuevos nombres de modelos: deepseek-v4-pro, deepseek-v4-flash
Dos nuevos IDs de modelos reemplazan los alias anteriores:
deepseek-v4-pro— 1,6T parámetros totales, 49B activos, ventana de contexto de 1M, máximo de salida de 384K. La opción con mayor carga de razonamiento.deepseek-v4-flash— 284B totales, 13B activos, mismo contexto de 1M. Más barato y rápido, adecuado para la mayoría de cargas de trabajo en producción.
Ambos soportan modos de pensamiento y no-pensamiento mediante el mismo ID de modelo. Ya no eliges el razonamiento escogiendo un modelo separado — lo activas mediante parámetros. Esta es la parte que rompe las migraciones ingenuas.
Mapeo transitorio durante el período de gracia
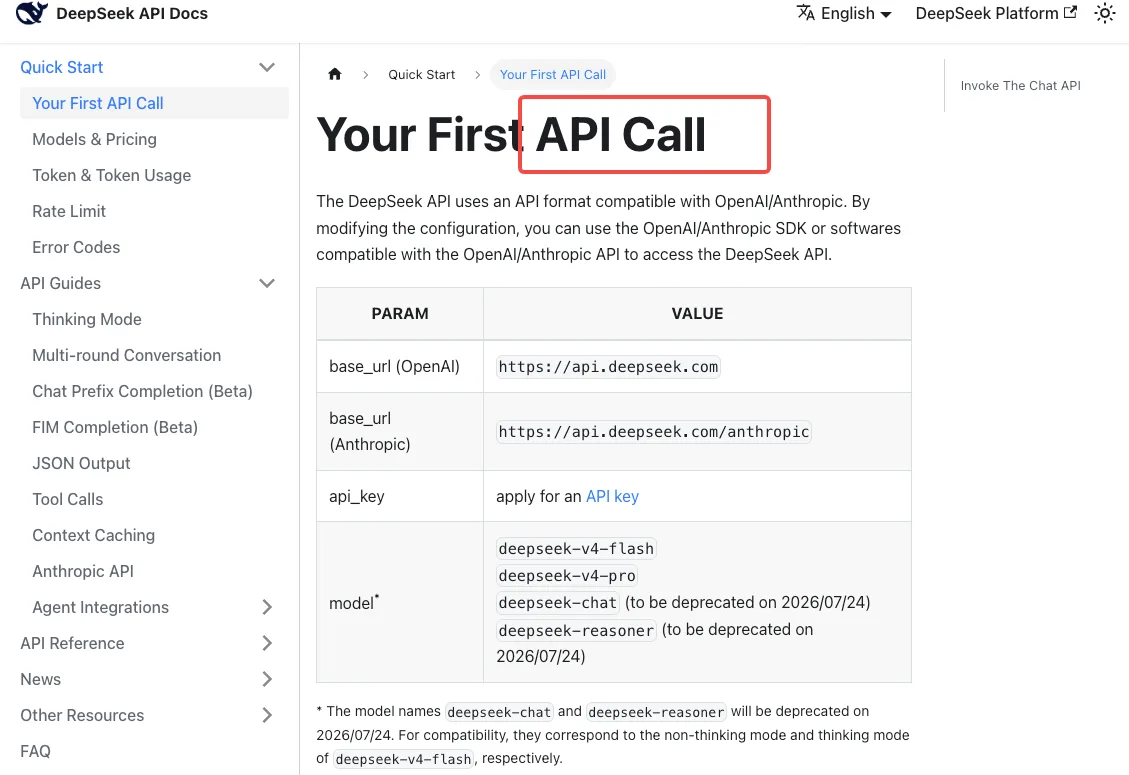
Según la documentación de inicio rápido de la API de DeepSeek, el mapeo de compatibilidad actual es:
deepseek-chat→deepseek-v4-flash(modo sin pensamiento)deepseek-reasoner→deepseek-v4-flash(modo de pensamiento)
Observa qué significa esto: si usabas deepseek-reasoner, ya estás ejecutando Flash, no Pro. Si tus cargas de trabajo de razonamiento se han sentido ligeramente diferentes en la última semana, por eso es. Para obtener razonamiento de nivel Pro tienes que migrar explícitamente a deepseek-v4-pro — el alias nunca te lleva allí.
Lista de verificación previa a la migración
Inventaria cada servicio que llama a la API de DeepSeek
Haz grep en todo el monorepo. Ambas cadenas:
grep -rn "deepseek-chat\|deepseek-reasoner" .No confíes en tu memoria sobre qué servicios lo usan. Encontré dos cron jobs y un manejador de webhooks que había olvidado que existían. También revisa plantillas .env, configuraciones de despliegue, archivos IaC y cualquier tabla de enrutamiento de gateway LLM. Si usas un proxy como LiteLLM o n1n.ai, revisa también ahí — el registro de cambios de DeepSeek en api-docs.deepseek.com confirma que los nombres antiguos están programados para discontinuación total, no solo advertencias de deprecación, así que cualquier cosa que aún los use fallará de forma definitiva.
Captura las líneas base actuales de latencia y calidad
Antes de cambiar una sola ca dena, toma una instantánea de cómo se ve “funcionando” hoy:
dena, toma una instantánea de cómo se ve “funcionando” hoy:
- Latencia p50 / p95 / p99 por endpoint
- Distribución de tokens de salida (media, desviación estándar)
- Puntuación de calidad en tu conjunto de evaluación, si tienes uno
- Costo diario por servicio
V4-Flash se comporta de forma ligeramente diferente a los pesos de V3.x a los que deepseek-chat solía apuntar. Quieres una línea base para poder saber qué cambió después del intercambio.
Identifica dónde el modo de pensamiento era implícito (reasoner)
Cada servicio que usaba deepseek-reasoner obtenía el modo de pensamiento de forma gratuita. Después de la migración, el modo de pensamiento es opt-in mediante un parámetro. Si te olvidas de añadirlo, pierdes silenciosamente tu capacidad de razonamiento y tus salidas empeoran sin ningún error. Este es el error de migración más común por mucho.
Cambios de código requeridos
Intercambio del nombre del modelo (ejemplos antes/después)
Para servicios que no necesitan modo de pensamiento:
python
# Antes
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
# Después
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages
)Para servicios que necesitan razonamiento, el cambio es mayor.
Añadir reasoning_effort donde se usaba reasoner
La documentación del modo de pensamiento de DeepSeek especifica que el pensamiento se habilita mediante extra_body y se ajusta con reasoning_effort:
python
# Antes
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# Después
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)Algunas cosas a tener en cuenta:
reasoning_effortaceptahighymax. Según la documentación,lowymediumse mapean ahigh, yxhighse mapea amax. El valor predeterminado para solicitudes en modo de pensamiento eshigh.- El modo de pensamiento ignora silenciosamente
temperature,top_p,presence_penaltyyfrequency_penalty. Configurarlos no generará error — simplemente no hará nada. Si tu configuración anterior de reasoner dependía detemperature=0.7, eso ya estaba siendo ignorado.
URL base y autenticación — sin cambios
Esta parte es genuinamente simple. https://api.deepseek.com sigue igual. Tu clave API sigue igual. Tanto los formatos OpenAI ChatCompletions como Anthropic SDK están soportados, así que la configuración de tu cliente existente sigue funcionando. Solo cambia la cadena model y (para razonamiento) el extra_body.
Pruebas de regresión
Diferencias en la forma de salida que debes esperar
V4-Flash es un modelo diferente a los pesos de V3.2 a los que deepseek-chat solía enrutar. Espera:
- Verbosidad ligeramente diferente — V4 tiende a producir salidas más largas con el mismo prompt
- Diferentes elecciones de formato para bloques de código y listas
- Mejor seguimiento de instrucciones en tareas agénticas
- El tokenizador es de la misma familia, pero los recuentos de tokens pueden variar
Ejecuta tu conjunto de evaluación. No asumas que “es compatible” significa “es idéntico”.
Reverificación de la línea base de costos
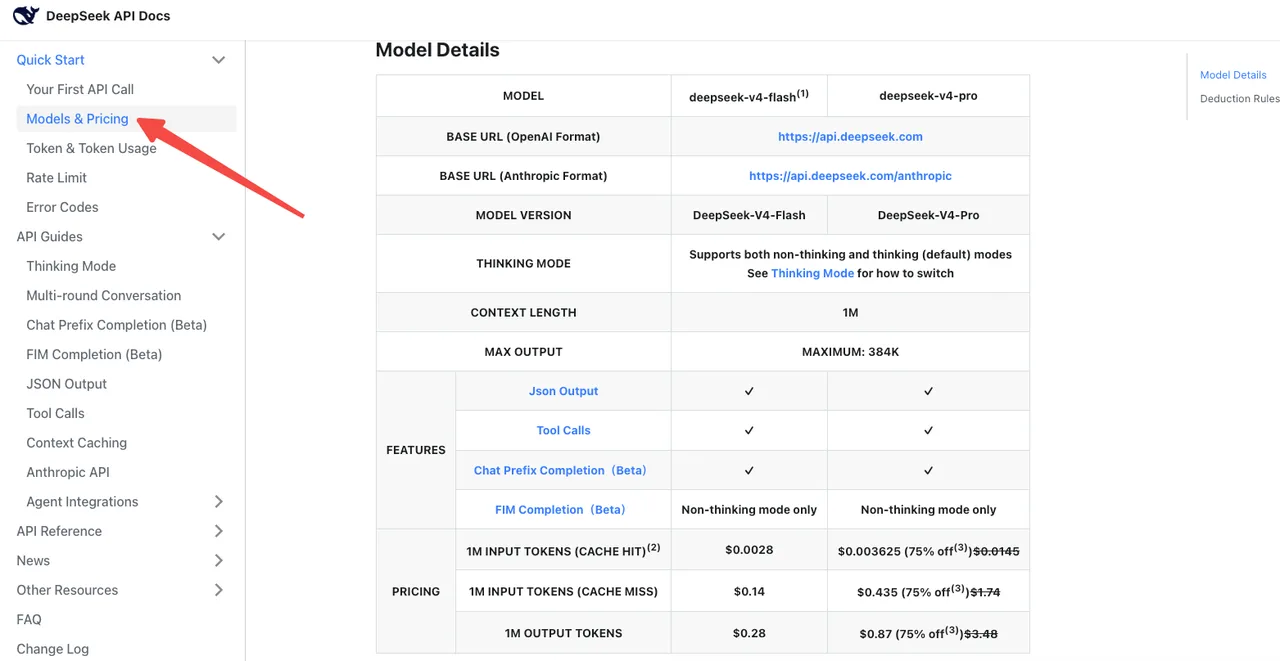
Según la página oficial de precios de DeepSeek, V4-Flash es $0,14 / $0,28 por 1M de tokens de entrada/salida a tarifas estándar. V4-Pro es $1,74 / $3,48 (actualmente con 75% de descuento hasta el 05/05/2026). El precio de caché-hit se redujo al 1/10 del precio de lanzamiento en toda la línea.
La trampa: el modo de pensamiento en V4-Pro consume dramáticamente más tokens de salida que el antiguo reasoner. Artificial Analysis evaluó V4-Pro con volúmenes de salida “muy verbosos”, generando aproximadamente 4 veces el recuento promedio de tokens de razonamiento. Tu factura puede subir aunque el cambio de nombre del modelo parezca neutro.
Validación del flujo de trabajo del agente
Si ejecutas agentes de múltiples pasos, vuelve a probar la cadena completa. El comportamiento de llamada de herramientas de V4 está más cerca de Claude Code que V3.x. Los esquemas de argumentos que funcionaban están mayormente bien, pero el modelo es más agresivo en reintentos y autocorrección, lo que significa a veces más llamadas de herramientas por tarea — y más tokens.
Estrategia de despliegue
Enfoque con feature flag
No hagas un intercambio global. Envuelve el nombre del modelo en un flag de configuración por servicio:
python
MODEL_NAME = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")Despliega servicio por servicio. Observa las tasas de error y la latencia p99 durante 24-48 horas por servicio antes de continuar.
Tráfico en sombra durante la transición
Para servicios de alto tráfico, refleja las solicitudes a ambas versiones durante una ventana corta. Compara las salidas sin conexión. Esta es la única forma de detectar regresiones silenciosas de calidad antes de que los usuarios lo hagan.
Errores comunes en la migración
Los cinco que realmente vi la semana pasada:
- Intercambiar
deepseek-reasoner→deepseek-v4-prosin añadirextra_body={"thinking": {"type": "enabled"}}. La calidad del razonamiento cae, no se dispara ningún error. - Hardcodear
temperature=0para cargas de trabajo de razonamiento y asumir que sigue funcionando (se ignora silenciosamente en modo de pensamiento). - Olvidar que el alias
deepseek-reasonersolo se mapeaba a V4-Flash, no a V4-Pro. Migrar a Pro es una mejora, no un intercambio equivalente. - No actualizar los paneles de monitoreo. Si tu panel agrupa por nombre de modelo, las llamadas de V4 no aparecen bajo tu tile antiguo de DeepSeek hasta que corrijas la etiqueta.
- Olvidar las integraciones de terceros. Si usas un proxy a través de LiteLLM, OpenRouter o cualquier gateway, proveedores como OpenRouter ya han publicado rutas de V4 — pero la configuración de tu gateway podría seguir fijando el nombre antiguo.
Preguntas frecuentes
¿Qué pasa si no migro antes del 24 de julio?
Después del 24 de julio de 2026, 15:59 UTC, las solicitudes que usen deepseek-chat o deepseek-reasoner fallan. El aviso oficial dice que ambos nombres serán “completamente retirados e inaccesibles”. No hay ninguna extensión anunciada.
¿Es deepseek-v4-flash un reemplazo directo de deepseek-chat?
Para cargas de trabajo sin pensamiento, mayormente sí — mismo nivel de velocidad, misma clase de precios, mismo endpoint. Las salidas difieren ligeramente porque los pesos subyacentes son diferentes, así que vuelve a ejecutar tus evaluaciones. Para cargas de trabajo de pensamiento, necesitas añadir el parámetro extra_body de pensamiento explícitamente.
¿Cómo preservo el comportamiento del reasoner?
Usa deepseek-v4-flash con el modo de pensamiento habilitado si quieres quedarte en el mismo nivel de cómputo (esto coincide con lo que deepseek-reasoner ya estaba haciendo). Usa deepseek-v4-pro con pensamiento habilitado si quieres una mejora de calidad. Ambos requieren extra_body={"thinking": {"type": "enabled"}}.
¿Cambiará mi estructura de facturación?
El modelo de facturación por token es el mismo. Las tarifas difieren — Flash es más barato que las tarifas antiguas de deepseek-chat, Pro es más caro pero actualmente con descuento. El precio de caché-hit ahora es el 10% de las tarifas estándar. Vigila la inflación de tokens de salida en modo de pensamiento.
¿Puedo probar ambas versiones antigua y nueva en paralelo?
Sí. Tanto los nombres de modelos heredados como los nuevos funcionan simultáneamente hasta el 24 de julio. Usa un feature flag para enrutar un porcentaje del tráfico a V4 y compara. Este es el camino de migración de menor riesgo.
Si despliegas a producción mañana, el movimiento más seguro es el más pequeño: intercambia primero deepseek-chat → deepseek-v4-flash, deja las cargas de trabajo de razonamiento para el final, y no toques V4-Pro hasta que lo hayas evaluado contra tu conjunto de evaluación real. La fecha límite es real, pero también quedan tres meses — hay tiempo para hacer esto con cuidado. Los equipos que sufran a finales de julio serán los que lo trataron como un PR de una línea y se saltaron la revisión de regresión. No seas esos equipos.
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber