GPT Image 2 im Jahr 2026: Lohnt sich die Integration?
Ein entwicklerorientierter Leitfaden zu GPT Image 2 mit Informationen zu API-Zugang, Preisgestaltung, Ratenlimits, Bearbeitungsunterstützung und ob es für Produktions-Workflows bereit ist.

Hier ist Dora. Ich verbrachte das Wochenende nach dem Launch damit, gpt-image-2 in einen Workflow einzubinden, den ich bereits mit dem Vorgängermodell betrieben hatte. Gleiche Prompts, gleiche Referenzbilder, gleiche Batch-Größen. Es ging nicht darum, beeindruckt zu sein – sondern darum herauszufinden, was sich tatsächlich ändert, wenn man die Modell-ID austauscht. Ich bin Dora, und das ist die Art von Arbeit, die ich erledige, bevor ich dem Team etwas empfehle.
Nach drei Tagen habe ich genug, um es aufzuschreiben. Nicht genug für ein Urteil, aber genug, um zu markieren, was Builder überprüfen sollten, bevor sie integrieren.
Dieser Beitrag richtet sich an Menschen, die bereits Bilder über eine API ausliefern. Wenn du evaluierst, ob du gpt-image-2 in einen Produktions-Workflow aufnehmen solltest – neben allem, was du gerade verwendest – dann ist hier, was ich mir gewünscht hätte, dass mir jemand sagt. Das Modell ist real, die API ist live, und die Rate Limits werden dich überraschen, wenn du die Docs nicht zuerst liest.
Was GPT Image 2 ist und was OpenAI offiziell veröffentlicht hat
Bestätigte Modell-IDs, Endpoints und Launch-Zeitpunkt
OpenAI hat gpt-image-2 am 21. April 2026 zusammen mit dem verbraucherorientierten Rebranding zu „ChatGPT Images 2.0” gelauncht. Die Modell-ID ist gpt-image-2, mit dem aktuellen Snapshot festgelegt als gpt-image-2-2026-04-21 gemäß der offiziellen GPT Image 2 Modellseite. Es läuft über v1/images/generations, v1/images/edits, v1/responses und v1/chat/completions.
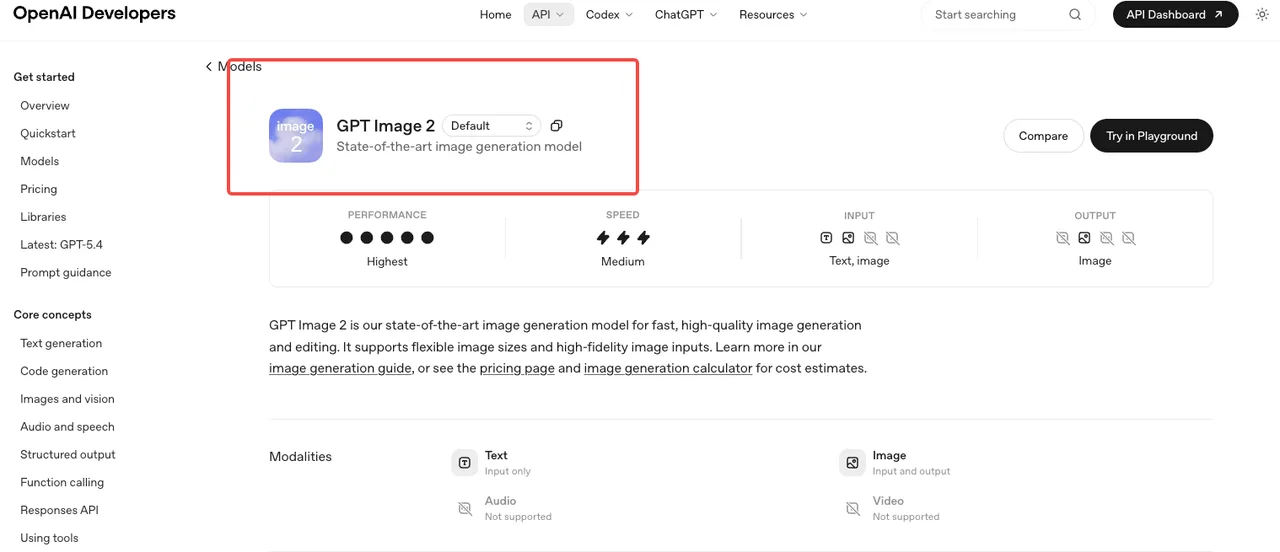 Das ist die verifizierte Oberfläche. Alles, was früheren API-Zugang behauptet, war entweder A/B-Test-Traffic innerhalb von ChatGPT oder Spekulation. Verwende die Snapshot-ID im Produktionscode – der Alias wird fortgeschrieben, wenn OpenAI eine neue Version veröffentlicht, und das ist kein Verhalten, das du mitten in einem Batch haben möchtest.
Das ist die verifizierte Oberfläche. Alles, was früheren API-Zugang behauptet, war entweder A/B-Test-Traffic innerhalb von ChatGPT oder Spekulation. Verwende die Snapshot-ID im Produktionscode – der Alias wird fortgeschrieben, wenn OpenAI eine neue Version veröffentlicht, und das ist kein Verhalten, das du mitten in einem Batch haben möchtest.
Was sich gegenüber früheren GPT-Image-Modellen geändert hat
Für Builder sind zwei Dinge wichtig. Erstens ist gpt-image-2 das erste OpenAI-Bildmodell mit eingebautem Reasoning – was sie „Thinking Mode” nennen, dokumentiert in der Ankündigung zur Einführung von ChatGPT Images 2.0. Vor der Generierung kann das Modell das Layout planen, das Web nach Referenzen durchsuchen und Outputs selbst prüfen. Zweitens hat sich das Text-Rendering so weit verbessert, dass Mixed-Script-Layouts – die Art, die bei jedem früheren kommerziellen Modell scheiterten – jetzt verwendbare Ergebnisse liefern, wie im GPT Image-Eintrag auf Wikipedia zur Modell-Linie bestätigt.
Ich habe beides getestet. Der Reasoning-Modus ist real. Er ist auch langsamer.
Warum GPT Image 2 für Produktionsteams relevant ist
Editing-Support, flexible Größen und Workflow-Implikationen
Die API bietet sowohl Generation als auch Edits, was bedeutet, dass du ein Referenzbild und eine Anweisung in einem einzigen Aufruf übergeben kannst – keine separate Inpainting-Pipeline. Der offizielle Leitfaden zur Bildgenerierung behandelt Größe, Qualität, Format, Komprimierung und Hintergrundoptionen.
Ein Detail, das mich erwischt hat: Transparente Hintergründe werden derzeit nicht über die Responses-Bildgenerierungsoption unterstützt. Ich bemerkte es am zweiten Tag, mitten in einem Batch, bei dem ich Parität mit dem Vorgängermodell angenommen hatte. Das Output kam mit einer weißen Füllung statt Alpha zurück. Der gesamte Batch war für den nachgelagerten Compositing-Schritt unbrauchbar. Wenn deine Pipeline auf Alpha-Output angewiesen ist, überprüfe dies gegen deinen tatsächlichen Code-Pfad, bevor du Modelle tauschst. Ich verlor eine Stunde dafür, plus die Credits für den fehlgeschlagenen Batch.
Für Teams, die mehrstufige Asset-Workflows betreiben – generieren, bearbeiten, verfeinern, exportieren – spart die einheitliche Oberfläche einen echten Übergabepunkt. Nicht weil jeder Schritt schneller ist, sondern weil es eine Integration weniger zu warten gibt. Weniger bewegliche Teile in der Produktion bedeutet weniger Stellen, an denen später Dinge kaputtgehen.
Fragen zu Qualität, Latenz und Rollout, die Teams stellen sollten
Die Geschwindigkeit ist laut OpenAIs eigenem Modell-Card „medium”. In der Praxis fügt der Thinking Mode spürbare Latenz hinzu – in Ordnung für einmalige Marketing-Assets, schmerzhaft für Batch-Jobs. Der Nicht-Thinking-Modus ist näher am gpt-image-1.5-Bereich.
Die Entscheidung ist nicht „immer Thinking Mode verwenden, weil er klüger ist”. Es ist „Thinking Mode verwenden, wenn das Layout wichtig ist, überspringen, wenn Geschwindigkeit wichtig ist”. Für einen Mockup mit Text und räumlichen Einschränkungen kaufen die extra Sekunden ein verwendbares Ergebnis beim ersten Versuch. Für einen Batch von Hintergrundvariationen möchtest du den schnelleren Pfad.
Ich habe nicht genug Batches durchgeführt, um eine saubere Latenz-Zahl zu liefern. Drei Tage reichen nicht. Was ich bestätigen kann: Cold-Path-Anfragen auf Tier 1 werden schnell gedrosselt. Die Obergrenze von 5 Bildern pro Minute klingt großzügig, bis fehlgeschlagene Retries und parallele Testläufe in dieselbe Quote hineinfresssen. Das ist kein Modellproblem. Das ist ein Tier-Problem, und es beeinflusst, ob dies speziell für dich produktionsreif ist.
Was Builder vor der Integration überprüfen müssen
Preise, Rate Limits und nicht unterstützte Funktionen
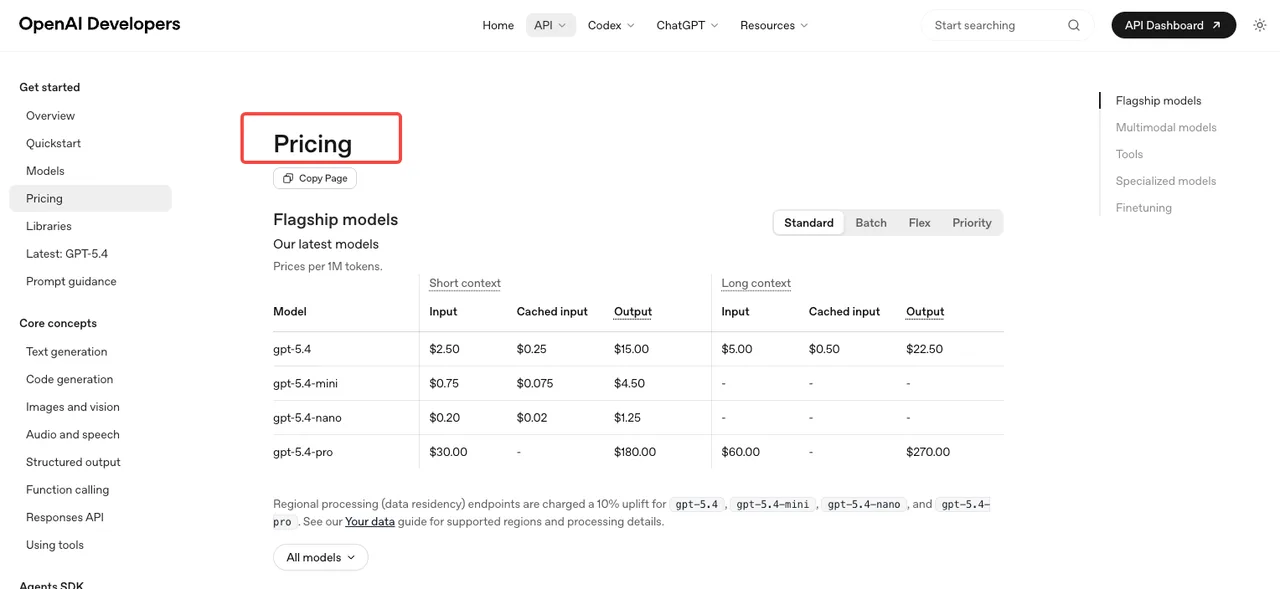
Token-basierte Preise gemäß der OpenAI-Preisseite: Image-Input kostet $8 pro Million Tokens, gecachter Image-Input $2, Image-Output $30. Text-Input ist $5, gecacht $1,25, Text-Output $10. Das Batch-Tier halbiert diese Preise. Pro-Bild-Schätzungen im Rechner landen bei etwa $0,006 (niedrige Qualität), $0,053 (mittel) und $0,211 (hoch) für 1024×1024.
Rate Limits sind der Bereich, in dem Teams überrascht werden. Tier 1 begrenzt auf 5 Bilder pro Minute. Tier 2 springt auf 20, Tier 3 auf 50, Tier 5 auf 250 – aber Tier 5 zu erreichen erfordert $1.000 ausgegeben und ein 30 Tage altes Konto, wie im OpenAI Rate Limits Guide dokumentiert. Wenn dein Produkt stoßweisen Traffic erwartet, plane den Tier-Aufstieg bevor du launchst.
Operative Fragen für den Produktionseinsatz
Fünf Dinge, die ich gegen deinen eigenen Workflow überprüfen würde, bevor du integrierst:
- Benötigt deine Pipeline transparente Hintergründe (aktuell nicht über das Responses-Tool unterstützt)
- Was ist dein Peak-Bilder-pro-Minute unter realistischer Last
- Führst du Edits mit Referenzbildern aus (diese fügen Image-Input-Tokens hinzu – schätze nicht nur vom Output her)
- Profitiert deine Prompt-Strategie vom Reasoning-Modus, oder reicht Non-Thinking aus
- Was passiert, wenn eine Generierung fehlschlägt – retry, Fallback oder Queue
Die REST-Bildgenerierungs-API-Referenz dokumentiert Request/Response-Formen. Lies sie, bevor du deinen Wrapper schreibst.
Wann GPT Image 2 eine starke Wahl ist und wann nicht
Starke Wahl: Produkte, bei denen Text im Bild erscheint (UI-Mockups, Infografiken, Menüs, Social Graphics mit Text), lokalisierte Kampagnen in nicht-lateinischen Schriften, Workflows, die von einer einzigen API für sowohl Generation als auch Editing profitieren, und Teams, die bereits in der OpenAI-Abrechnungsbeziehung sind.
Schwächere Wahl derzeit: Hochvolumen-Batch-Pipelines auf Tier-1- oder Tier-2-Konten, Produkte, die transparente Hintergründe über das Responses-Tool benötigen, latenzempfindliche Anwendungen, bei denen der Thinking-Mode-Overhead wichtig ist, und Teams, deren bestehendes Modell bereits gut kalibriert ist und bei denen der Wechselkostenvorteil die marginale Qualitätsverbesserung überwiegt.
Das ist keine „Verwende es oder falle zurück”-Situation. Es ist eine „Überprüfe es gegen deine eigenen Einschränkungen”-Situation. Das Modell ist gut. Ob es gut für dich ist, hängt von den fünf obigen Fragen ab.
FAQ
Ist GPT Image 2 in der OpenAI API verfügbar?
Ja. Die Modell-ID ist gpt-image-2, mit Snapshot gpt-image-2-2026-04-21. Es ist über die Standard-Bildgenerierung, Image-Edits und Responses-Endpoints zugänglich. Der Free-Tier wird nicht unterstützt – du benötigst ein bezahltes Konto, mit Rate Limits, die nach Usage-Tier skalieren.
Für welche Bildaufgaben ist GPT Image 2 am besten geeignet?
Alles, was Text im Bild beinhaltet (Menüs, Mockups, Infografiken, mehrsprachige Grafiken), referenzgesteuerte Edits und Layouts, die räumliches Reasoning erfordern. Das Text-Rendering ist das praktisch bedeutsamste Upgrade. Für rein fotorealistische Generierung ohne Text ist der Gewinn gegenüber gpt-image-1.5 geringer.
Welche Einschränkungen sollten Teams zuerst prüfen?
Drei konkrete: Transparente Hintergründe werden nicht über die Responses-Bildgenerierungsoption unterstützt, Tier 1 begrenzt die Generierung auf 5 Bilder pro Minute, und der Reasoning-Modus fügt Latenz hinzu. Ebenfalls prüfenswert – Streaming, Function Calling und strukturierte Outputs werden auf der Modellseite als nicht unterstützt aufgeführt.
Ist es für den Hochvolumen-Produktionseinsatz bereit?
Es kann sein, aber nicht mit einem frischen Konto. Tier 3 (50 Bilder/min) zu erreichen erfordert $100 ausgegeben und ein mindestens 7 Tage altes Konto. Tier 5 (250 Bilder/min) benötigt $1.000 ausgegeben und eine 30-tägige Kontohistorie. Wenn du hohe Parallelität von Tag eins benötigst, plane den Tier-Aufstieg oder nutze einen Anbieter mit höheren gepoolten Limits.
Wie verhält sich die Preisgestaltung im Vergleich zu GPT Image 1.5?
gpt-image-2 verwendet Token-basierte Abrechnung: Image-Input $8/M, Image-Output $30/M. Pro-Bild-Schätzungen (1024×1024) liegen bei etwa $0,006 niedrige Qualität, $0,053 mittel, $0,211 hoch. Edits mit Referenzbildern fügen Image-Input-Tokens hinzu, sodass die Kosten höher sind als reine Output-Schätzungen vermuten lassen. Führe deine tatsächliche Arbeitslast durch den Rechner, bevor du Parität mit 1.5 annimmst.
Fazit
Drei Tage Tests reichen nicht aus, um ein Urteil über die langfristige Zuverlässigkeit zu fällen. Sie reichen aus, um zu sagen, dass das Modell real ist, die API stabil ist und die Integrationsfragen größtenteils operativer Natur sind, nicht technischer – Preisstufen, Rate Limits, fehlende Features, von denen dein Workflow möglicherweise abhängt. Führe ein kleines Pilotprojekt mit deinen tatsächlichen Prompts und deiner tatsächlichen Parallelität durch, bevor du dich festlegst. Das ist alles, was ich von hier aus bestätigen kann. Den Rest musst du in deiner eigenen Umgebung überprüfen.
Nächste Woche folgt eine Fortsetzung mit Batch-Latenz-Zahlen, sobald ich genug Daten habe, um ihnen zu vertrauen.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten