视频换脸详解:工作原理 + API 指南
深入解析视频换脸的底层工作原理,以及如何通过 API 调用。涵盖完整处理流程、输入要求和常见失败模式。

你好,我是 Dora。说实话——第一次尝试调用视频换脸 API 时,我得到的响应看起来几乎是正确的。脸换上去了,但时间偏差了半秒。光照效果让主体看起来隐隐发光,像一个廉价的鬼魂。
这就是视频换脸技术的问题所在。从外表看似乎很简单——**把 A 的脸换到 B 的身体上,**完事——但一旦你超越演示片段,尝试构建真实产品时,就会意识到底层有多少复杂的运转环节。理解这些环节,是输出效果精良与让用户倒胃口之间的关键差距。
本指南将介绍视频换脸的实际工作原理、现有的不同方法、API 在执行任何有意义操作之前需要什么,以及如何处理那些迟早会找上门来的失败模式。
视频换脸实际上做了什么
让我把这个问题说清楚,因为很多解释文章跳过了真正重要的部分。
视频换脸不是滤镜。 它不是覆盖在画面上的遮罩。它在相当深层的层面上所做的事情是:检测视频每一帧中的人脸,映射其几何结构,提取源脸的身份特征,然后将源脸身份融合到目标人物的面部结构上,同时保留目标人物的动作、光照和表情。
这是三个独立问题依次发生的过程。
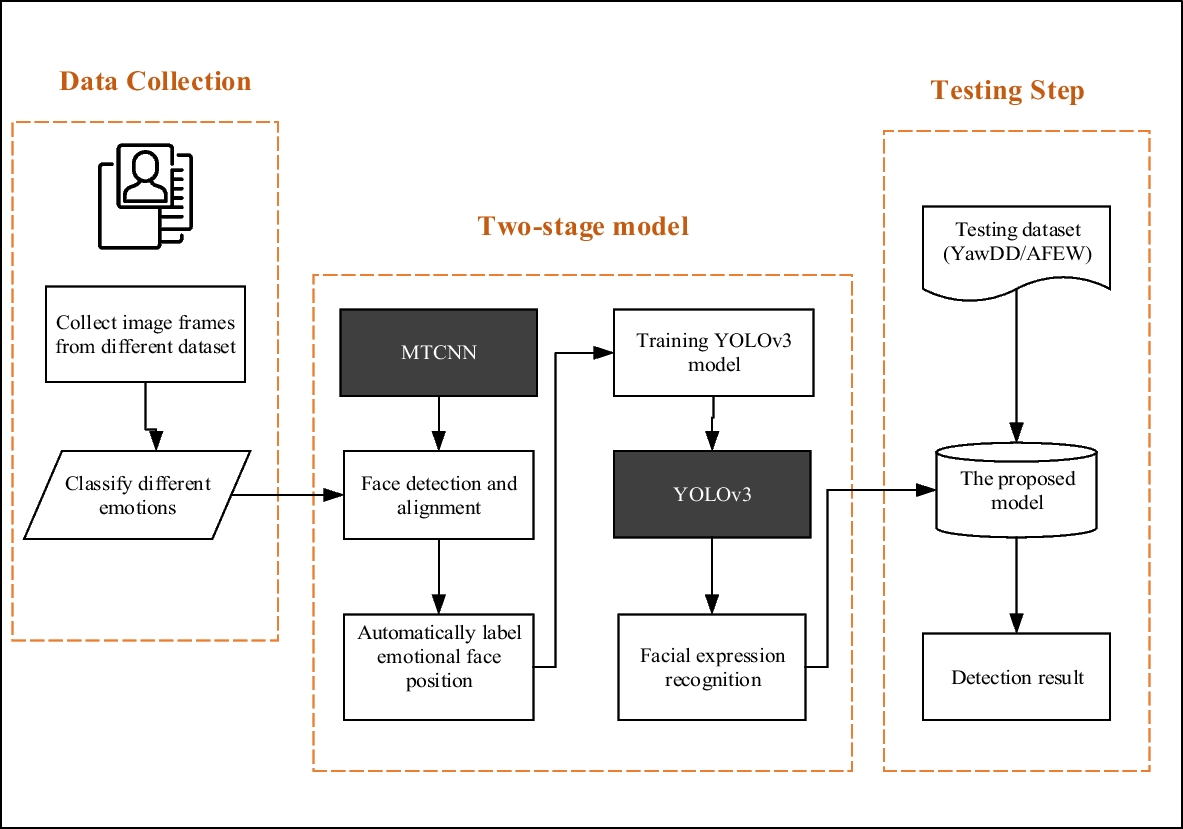
检测 → 对齐 → 融合流水线
检测是模型在帧中找到人脸的步骤。这听起来很简单,但并不简单。被遮挡的人脸、以大角度转向的人脸或快速移动的人脸都会导致检测失败。大多数生产系统使用多任务级联卷积网络的变体——你可以在这篇人脸检测深度学习指南中了解基础 MTCNN 方法——尽管更新的架构已在早期基准上显著改进。
对齐是大多数人不会想到的步骤,但它确实至关重要。一旦检测到人脸,模型就会识别面部关键点——眼睛、鼻尖、嘴角——并用它们将人脸归一化到规范的位置和比例。没有这一步,换脸效果就像是有人以略微错误的角度贴上一张脸,然后希望没人注意到。但他们总会注意到的。
融合是实际身份转换发生的地方。模型获取源脸的身份特征,将其投影到目标脸的几何结构上,然后将结果合成回帧中。现代方法使用生成对抗网络(GAN)来实现这一点——一个生成融合面孔的生成器和一个评估真实性的判别器——这就是为什么了解基于 GAN 的深度伪造生成工作原理在你开始调试输出之前是非常有用的背景知识。
输出质量实际意味着什么
有一件事让我早期感到困惑:换脸输出中的”质量”不是一个数字。 它至少是三件独立的事情。
身份保真度——输出结果实际上看起来像源脸,而不仅仅是两者的模糊平均值?
时间一致性——脸在帧间看起来是否相同,还是会出现细微闪烁?
照片真实感——结果看起来是否融入了场景,还是像是合成上去的?
你可以有出色的身份保真度但糟糕的时间一致性。你也可以有精美的照片真实感但较差的身份转换。大多数 API 提供在这些指标之间权衡的设置或质量档次。了解哪个对你的用例最重要,会让你少走很多弯路。
视频换脸方法的类型
并非所有视频换脸模型的工作方式都相同。类似的架构差异存在于现代 AI 视频生成模型(如 Seedance 2.0)中,不同方法对时间一致性和运动建模的处理方式差异很大。在选择工具或 API 之前,有两个重要的维度需要了解。
逐帧模型 vs. 时序感知模型
逐帧模型独立处理视频的每一帧。它们通常更快且更易于实现,但它们没有考虑到视频是一系列相关图像这一事实。结果是:帧间出现细微闪烁,尤其是在人脸边缘或低光照条件下。
时序感知模型在处理帧时会了解前后帧的内容——本质上是理解运动并在整个片段中保持一致性。类似的权衡出现在领先 AI 视频模型的对比中,稳定性和运动真实感是主要差异化因素——本质上是理解运动并在整个片段中保持一致性。输出更流畅、更稳定,但这些模型更重且更慢。对于超过几秒钟或用于近距离观看的内容,时序感知模型值得付出延迟代价。
我的切身体会:如果你是在做原型或生成缩略图,逐帧就够了。如果你在构建人们会在全尺寸屏幕上观看的东西,你会为闪烁效果感到后悔。
单脸 vs. 多脸
单脸模型更简单,对其特定任务通常质量更高。如果你的用例涉及帧中一张清晰可见的脸——这涵盖了大多数生产场景——这是正确的起点。
多脸模型可以检测并替换单帧中的多张脸。它们适用于合唱团拍摄、群体画面,或你无法完全控制输入视频的场景。代价是它们计算量更大,且更容易出现错误的人脸分配——即模型把错误的脸换到了错误的身体上。在发送一段四人视频后得到意外超现实的结果之前,值得了解这一点。
调用 API 之前:你需要什么
这是大多数人浪费时间的地方。不是因为 API 很难,而是因为输入要求比文档通常说明的更具体。
输入要求(格式、分辨率、片段长度)
大多数视频换脸 API 期望:
- 视频格式:使用 H.264 编码的 MP4 是最安全的默认选项。一些 API 也接受 WebM 或 MOV,但 H.264/MP4 是支持最广泛的。
- 分辨率:720p 是获得可接受换脸质量的实际最低要求。1080p 为模型提供更多面部细节。低于 480p,大多数模型开始产生明显的伪影——人脸区域简单来说没有足够的像素进行干净的融合。
- 片段长度:许多 API 将同步处理限制在 30–60 秒。较长的片段需要通过 webhook 回调进行异步任务提交。在设计请求处理架构之前,了解你的片段属于哪个类别。
- 源图像:对于你要换入的人脸,单张光线充足的正面照片通常就足够了。一些模型也接受视频源,但光线均匀的清晰静态图像通常能产生更一致的身份转换。
人脸角度和光照限制
在这里快速做个现实检查:模型不是魔法。
人脸角度:大多数模型在距正面视角约 30–35 度以内效果良好。超过这个范围,你开始失去关键点精度,这会级联导致对齐错误,进而产生融合伪影。侧脸通常不受支持或产生无法使用的输出。如果你的源素材中主体经常背向镜头,请相应降低质量预期。
光照:强烈的方向性光照——侧光照射的脸、在眼睛处产生深阴影的强烈顶部光照——对融合步骤来说更难令人信服地处理。模型需要协调源脸的光照与目标帧的光照,两者差异越大,接缝就越明显。
我不是说要避免昏暗的画面。我的意思是:如果你在生成源素材且对其有任何控制权,均匀的光照将显著改善你的输出效果。
API 工作流程分步说明
让我们进入实践环节。以下是视频换脸 API 调用的典型流程。
身份验证
几乎每个生产 API 都使用 Bearer Token 认证。你将在注册时收到一个 API 密钥,并将其作为请求头传入:
Authorization: Bearer YOUR_API_KEY这是标准做法,与 OWASP REST 安全备忘录中的安全指南一致。从一开始就值得做的几件事:
- 将 API 密钥存储为环境变量,永远不要硬编码在代码库中
- 设置密钥轮换——大多数 API 允许你在不丢失账户访问权限的情况下重新生成密钥
- 如果可用,使用仅具有你的集成实际需要的权限的作用域密钥
发送请求
典型的请求体大致如下:
{
"source_image_url": "https://your-storage.com/source-face.jpg",
"target_video_url": "https://your-storage.com/target-video.mp4",
"output_format": "mp4",
"quality": "high"
}一些 API 通过 multipart form-data 直接接受二进制文件上传。其他 API 只接受指向公开可访问文件的 URL。仔细查阅你的 API 文档——这是静默失败的常见来源,API 返回 200 但什么都没处理,因为文件 URL 无法访问。
对于较长的片段,你通常会收到任务 ID 而不是直接收到输出:
{
"job_id": "fswap_a3b92f",
"status": "processing",
"estimated_time_seconds": 45
}输出处理
轮询任务状态端点或配置 webhook 以在处理完成时接收结果。响应将包含处理后视频的下载 URL。这些 URL 通常有时间限制——在过期窗口内将输出下载并存储到你自己的存储中,过期时间通常为 1–24 小时,具体取决于服务商。
不要因为状态显示已完成就认为输出是完美的。始终抽查几帧。状态完成意味着流水线运行没有崩溃,并不意味着换脸效果看起来很好。
对于生产系统,围绕这些异步模式构建稳健的 REST API 集成——适当的错误处理、重试逻辑、webhook 验证——将为你省去日后痛苦的调试过程。

常见失败模式及修复方法
这里才是真正实战的地方。以下三种情况我都遇到过。
运动卡顿
表现形式: 换脸后的面孔在帧间抖动或”弹跳”,这个问题与**创作者修复 AI 生成视频中闪烁和抖动的指南**中讨论的问题非常相似。
原因: 逐帧处理没有时间平滑。每一帧都被独立求解,因此关键点检测中的微小变化会产生不一致性。
修复: 如果可用,切换到时序感知模型。如果你被锁定在逐帧 API 中,一些服务商提供后处理稳定化处理——在你的选项中寻找这一功能。或者,在将输入视频发送到 API 之前,用运动稳定化进行预处理也有帮助。
身份漂移
表现形式: 输出的脸逐渐看起来越来越不像源脸,而更像源脸和目标脸的混合——或者就是一个看起来普普通通的陌生人。
原因: 通常是源图像质量问题。如果源脸照片分辨率低、光照差或以非正面角度拍摄,模型就无法提取可靠的身份特征。它会用能推断出的任何内容来填补空缺,这往往会向目标脸方向漂移。
修复: 使用更高质量的源图像。正面、均匀光照,人脸区域至少 512×512 像素。根据我的经验,这一个改变能解决大约 80% 的身份漂移案例。
光照不匹配
表现形式: 换脸后的面孔看起来像是”贴上去的”——脸部的光照方向或色温与周围场景不匹配。
原因: 融合模型尝试协调光照,但能做的有限。源图像和目标视频之间光照差异过大,会给合成步骤带来挑战。
修复方法:
- 如果你能控制源图像,在与目标画面相似的光照条件下拍摄
- 一些 API 提供明确的光照归一化作为参数——开启它
- 对于严重的不匹配,对输出进行调色后处理可以帮助将脸部更令人信服地融入场景
那么,结论是什么?
视频换脸是一项当你理解它需要什么才能成功时,真正强大的技术。大多数质量问题并不神秘——它们可以追溯到输入质量、针对用例的模型选择,以及对流水线能做什么和不能做什么的现实预期。把这些做对了,你就会少花很多时间去调试那些在演示中看起来不错但在生产环境中崩溃的输出结果。





