GPT-5.5 與 GPT-5.4 生產團隊對比指南
從生產角度比較 GPT-5.5 與 GPT-5.4:可用性、推出時程、遷移準備程度,以及各模型當前的適用場景。

嗨,我是 Dora。OpenAI 於 2026 年 4 月 23 日發布了 GPT-5.5。距離 GPT-5.4 推出不到兩個月。API 延遲一天開放,於 4 月 24 日以 OpenAI 所稱「不同的安全保障機制」正式上線。如果你今天正在 GPT-5.4 上運行程式碼代理,問題不在於 GPT-5.5 是否更聰明。基準測試已經證明它確實如此。問題在於你特定的 API 工作負載是否能獲得足夠收益,值得本週就進行遷移。
我寫這篇文章,是因為我曾經面對過這樣的抉擇。相同的情境,不同的模型版本號。誠實的答案是:這取決於三件你可以在一個下午內驗證的事,以及一件目前完全無法驗證的事。
本文就是要教你如何分辨兩者的差異。

GPT-5.5 與 GPT-5.4 一覽
可用性與推出差異
GPT-5.5 於 4 月 23 日在 ChatGPT 和 Codex 上為 Plus、Pro、Business 及 Enterprise 方案上線。API 於 4 月 24 日跟進開放。根據 OpenAI GPT-5.5 官方發布公告,定價為每 100 萬輸入 token $5、每 100 萬輸出 token $30,上下文視窗為 100 萬 token。GPT-5.5 Pro 則為每 100 萬 $30/$180。
GPT-5.4 仍保留在費率表上。你可以在 OpenAI 官方 API 定價頁面確認兩者。GPT-5.4 標準版為 $2.50 輸入 / $15 輸出。因此表面上的價格差距為 2 倍。
OpenAI 的說法是 GPT-5.5 在每項任務中使用的 token 數量更少,尤其是 Codex 工作負載,因此實際成本差距比費率表顯示的要小。這是合理的說法。但這也是一個你必須用自己的實際流量來驗證的說法,才能把預算押在上面。
官方聲明與推論的差異
已有來源佐證的聲明:定價、與 GPT-5.4 相當的每 token 延遲、100 萬上下文、API 服務的安全保障差異。OpenAI 聲明但值得仔細閱讀的內容:代理程式碼編寫能力的提升、Terminal-Bench 2.0 得分 82.7%、MRCR v2 長上下文檢索的大幅躍進。
流傳的推論:GPT-5.5「很快」將在大多數生產工作負載中取代 GPT-5.4。OpenAI 並未這樣表示。GPT-5.4 並未被棄用。不要針對一個尚未出現在文件中的日落計劃。
當我閱讀 TechCrunch 對 GPT-5.5 發布的報導時,我在這裡停頓了一下——其框架大量強調「超級應用程式」的野心,那是一個策略故事,而不是遷移的觸發條件。
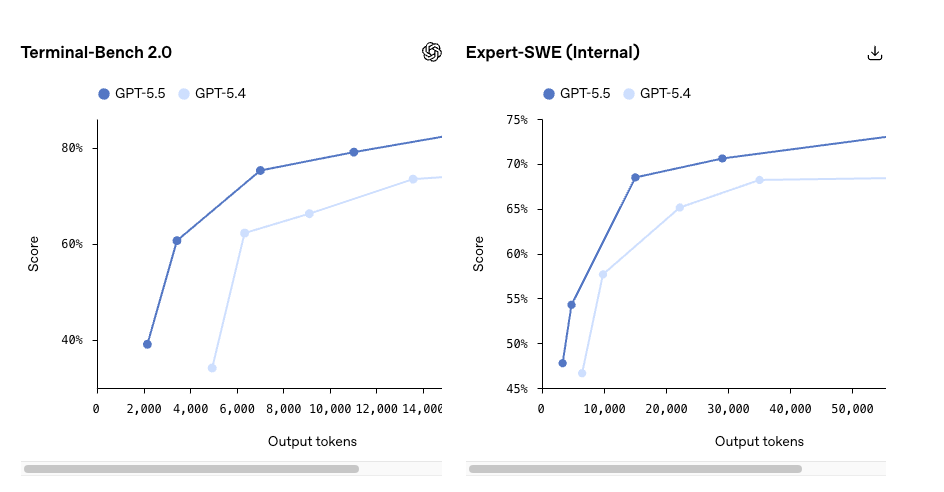
GPT-5.5 表現更強的領域
代理程式碼編寫與電腦操作能力聲明
OpenAI 發布的基準測試差距是真實數字,但它們是 OpenAI 自己的評估。請將其視為方向性指標,而非基準事實。
- Terminal-Bench 2.0:82.7%(GPT-5.5)vs 75.1%(GPT-5.4)
- SWE-Bench Pro:58.6% vs OpenAI 先前報告的 55–57% 範圍
- OSWorld-Verified(電腦操作):78.7%
- MRCR v2 長上下文檢索(512K–1M):74.0% vs 36.6%
最後這項數據才是我真正會關注的。長上下文檢索提升 37 個百分點,是那種能改變什麼可行、而不只是什麼更快的差距。 如果你的工作負載經常超過 256K token——整個程式碼庫、多小時的代理追蹤、完整文件集——這就是升級理由變得真實的地方。
如果你的工作負載是短上下文聊天補全和結構化輸出,以上這些都不適用於你。表現優於預期,但只是略微。
效率與工作流程影響
OpenAI 的說法是 GPT-5.5 在等效 Codex 任務中使用的輸出 token 大約減少 40%。如果這在你的流量上成立,2 倍費率表增幅將壓縮至約 20% 的實際增幅。這對遷移成本計算來說是有意義的差異。
這也意味著你不能信任現有的成本預測。Token 計費方式改變了。在進行推算之前,先用真實工作負載跑一週。
為何 GPT-5.4 今天仍可能是更好的 API 選擇
這並非乾淨升級的三個原因。
其一:拒絕行為。 OpenAI 在 GPT-5.5 中採用了更強的安全保障套件——他們稱之為迄今最強的一套。完整內容在 GPT-5.5 系統卡中。對大多數團隊來說,這是看不見的。但對於在政策邊界附近運行雙重用途、安全性或代理工作負載的團隊,拒絕範圍已經改變,而且改變的方式在系統卡中並未完全列舉。在假設行為一致之前,先把你現有的提示集跑一遍。
其二:工具穩定性。 工具呼叫 schema、推理強度下的結構化輸出行為、並行工具呼叫——這些介面在模型世代之間往往會有漂移。你針對 GPT-5.4 調整的合約不保證繼續有效。重播生產流量比閱讀文件能更快找出差異。
其三:突發負載下的成本可預測性。 GPT-5.5「更少 token」的說法是群體平均值。個別工作負載各有差異。如果你的流量有長尾情況——偶爾陷入長推理鏈的代理——你可能會遇到平均值中不會出現的成本峰值。GPT-5.4 有一個你的財務團隊已經接受的可預測成本形態。
這些都不意味著永遠不要遷移。意思是不要在公告當下就遷移。

團隊的實用決策框架
四個問題,依序回答:
- 你的工作負載受長上下文限制嗎? 如果你經常執行超過 200K token 的提示,且檢索品質是你的瓶頸,GPT-5.5 現在可能值得認真測試。MRCR v2 的差距不是那種你可以忽略的數字。
- 你的工作負載是代理式/多步驟/Codex 風格嗎? 值得進行並行 A/B 測試。在你用實際任務測量 token 消耗之前,不值得進行完整遷移。40% 減少是合理的說法。但這也是一個需要用你的數據、而非 OpenAI 數據來驗證的說法。
- 你的工作負載是短上下文聊天或單次生成嗎? 繼續使用 GPT-5.4。價格增幅是真實的,而這些任務的能力差距很小。閱讀基準測試類別後,此假設得到驗證——收益集中在長程和電腦操作評估上,而非短輪次。
- 你目前是否有生產事故或容量問題? 不要在緊急情況下遷移。新模型 + 新安全保障 + 新 token 計費,是三個同時發生的變化。在並行分支上運行比較。
無論屬於哪個類別,在切換前都需要驗證的事項:你的提示語料庫上的拒絕行為、工具呼叫 schema 一致性(查看 OpenAI API 文件中的 GPT-5.5 模型頁面)、你的路由層端對端延遲,以及基於真實流量的一週成本預測。不是合成數據,是真實流量。

常見問題
團隊現在應該從 GPT-5.4 切換嗎?
預設情況下不應該。如果你受長上下文限制或運行多步驟代理堆疊,則可以切換。否則,進行兩週的並行測試,根據你的指標比較,然後再決定。「越新越好」的反射思維讓許多團隊花費了我不想計算的金錢。
GPT-5.5 今天可以用於生產環境嗎?
可以。API 自 2026 年 4 月 24 日起已上線,有文件記載的定價和速率限制。「可用」和「適合你的工作負載」是不同的問題。第一個問題已有定論。第二個問題需要你自己回答。
遷移前團隊應該測試什麼?
你的提示集上的拒絕行為。代表性任務(非合成任務)的 token 消耗。工具呼叫 schema 和結構化輸出一致性。你真實並發情況下的延遲。一週正常流量的成本。如果其中任何一項出現問題,就先停在原地,直到問題解決。
什麼時候繼續使用 GPT-5.4 是更好的選擇?
短上下文工作負載。穩定、調整良好的生產系統。成本敏感的工作負載,其中 2 倍費率表增幅無法被你特定流量的 token 效率所抵消。正處於發布週期中的團隊。沒有資源重新驗證拒絕行為的團隊。GPT-5.4 並未被棄用。 留下來是個有效的選擇,而非延遲的遷移。
結論
對生產團隊而言,GPT-5.5 與 GPT-5.4 的答案並非單一答案。這是一個偽裝成模型問題的工作負載問題。長上下文和代理工作負載有真實理由立即進行測試。短上下文工作負載有真實理由等待。中間的所有人都有理由進行並行比較,讓數據來決定。
我的數據就到這裡為止。我引用的基準測試大多是 OpenAI 自己的數據。Token 效率聲明是合理的,但尚未在他們的評估之外得到驗證。安全保障的差異將以系統卡無法預測的方式在生產環境中浮現。
用你的流量自己跑一週。那會告訴你比我說的任何話都更多的信息。
等發布後的行為穩定了,還會有更多內容。
相關文章:
- GPT-5.5 for Builders: API Capabilities, Pricing, and When to Upgrade
- GPT-5 Model Versions Explained: Differences, Use Cases, and Migration Paths
- GPT-5.4 vs GPT-5.3: What Changed for Developers and API Workloads
- Agentic Workflow Patterns: Tool Wiring, Pitfalls, and Real-World Tradeoffs
- DeepSeek V4 Pro vs Flash: Cost, Speed, and Performance Trade-offs





