GPT-5.5 与 GPT-5.4 生产团队对比分析
从生产角度对比 GPT-5.5 与 GPT-5.4:可用性、推出时间、迁移准备情况,以及每个模型当前的适用场景。

你好,我是 Dora。OpenAI 于 2026 年 4 月 23 日发布了 GPT-5.5,距 GPT-5.4 发布不到两个月。API 推迟了一天,于 4 月 24 日开放,OpenAI 称其采用了”不同的安全措施”。如果你今天正在用 GPT-5.4 跑 coding agent,问题不在于 GPT-5.5 是否更聪明——基准测试已经给出了答案。问题在于你的具体 API 工作负载是否值得在本周进行迁移。
我写这篇文章,是因为我之前也做过同样的决策,只是模型编号不同。说实话,答案取决于三件你可以在一个下午验证的事,以及一件目前完全无法验证的事。
这篇文章就是帮你看清如何分辨。

GPT-5.5 与 GPT-5.4 速览
可用性与发布差异
GPT-5.5 于 4 月 23 日在 ChatGPT 和 Codex 上向 Plus、Pro、Business 和 Enterprise 用户上线,API 于 4 月 24 日跟进。根据 OpenAI 官方 GPT-5.5 发布公告,定价为每 100 万输入 token $5、每 100 万输出 token $30,支持 100 万 token 上下文窗口。GPT-5.5 Pro 定价为每 100 万 $30/$180。
GPT-5.4 仍在定价列表中。你可以在 OpenAI 官方 API 定价页面确认两者的价格。GPT-5.4 标准版为输入 $2.50 / 输出 $15。因此表面价格差距是 2 倍。
OpenAI 的说法是,GPT-5.5 每个任务消耗的 token 更少,尤其在 Codex 工作负载中,因此实际成本差距比定价表看起来要小。这是一个合理的说法,但你必须在自己的实际流量上加以验证,才能将预算押注于此。
官方声明与推断信息
有来源的官方声明:定价、与 GPT-5.4 相比每 token 的延迟持平、100 万上下文、API 服务中的安全措施差异。OpenAI 有声明但需仔细阅读的内容:智能编码增益、Terminal-Bench 2.0 得分 82.7%、MRCR v2 上的长上下文检索跳跃。
流传的推断:GPT-5.5 将”很快”在大多数生产工作负载中取代 GPT-5.4。OpenAI 并没有这么说。GPT-5.4 没有被弃用。不要基于一个尚未出现在文档中的日落计划来制定策略。
我在读到 TechCrunch 对 GPT-5.5 发布的报道时停下来思考了一下——那篇报道的框架侧重于”超级应用”的雄心,这是一个战略故事,而不是迁移的触发点。
GPT-5.5 的明显优势
智能编码与计算机使用声明
OpenAI 发布的基准测试差值是真实数字,但它们是 OpenAI 自己的评估。将其视为方向性参考,而非确定性结论。
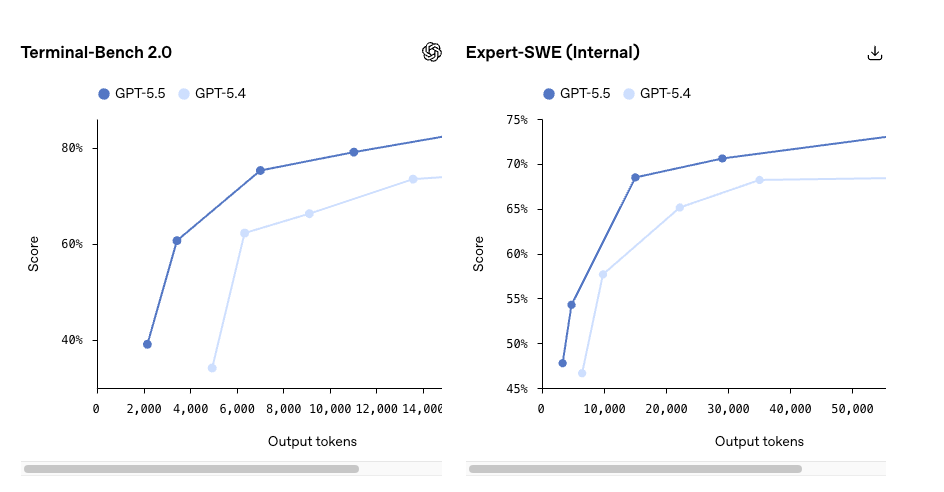
- Terminal-Bench 2.0:82.7%(GPT-5.5)vs 75.1%(GPT-5.4)
- SWE-Bench Pro:58.6% vs OpenAI 此前报告的 55–57% 区间
- OSWorld-Verified(计算机使用):78.7%
- MRCR v2 长上下文检索(512K–1M):74.0% vs 36.6%
最后这个数字才是我真正会关注的。长上下文检索提升 37 个百分点,是那种改变可行性、而不仅仅是速度的差距。 如果你的工作负载经常超过 256K token——整个代码库、多小时的 agent 轨迹、完整文档集——这正是升级理由变得真实的地方。
如果你的工作负载是短上下文对话补全和结构化输出,上述内容对你完全不适用。比预期好一些,但只是略好。
效率与工作流影响
OpenAI 声称 GPT-5.5 在等效 Codex 任务中大约减少 40% 的输出 token。如果这在你的流量上成立,2 倍的定价增幅将压缩到大约 20% 的实际增幅。这对迁移决策来说是一个有意义的差异。
这也意味着你无法信任现有的成本预测。token 计算方式变了。在外推之前,先用真实工作负载跑一周。
为什么今天 GPT-5.4 可能仍是更好的 API 选择
这不是一次简单升级,有三个原因。
原因一:拒绝行为。 OpenAI 为 GPT-5.5 配备了更强的安全措施套件——他们称之为迄今为止最强的一套。完整内容见 GPT-5.5 系统卡。对大多数团队来说这是无感的。但对于在政策边界附近运行双用途、安全或智能体工作负载的团队,拒绝面已经发生了变化,而且变化方式系统卡并没有完整列举。在假设行为一致之前,先用你现有的 prompt 集跑一遍。
原因二:工具稳定性。 工具调用 schema、推理过程中的结构化输出行为、并行工具调用——这些接口在模型代际之间往往会漂移。你在 GPT-5.4 上精调过的契约不一定能延续。通过回放生产流量,你会比读文档更快地发现差异。
原因三:突发负载下的成本可预测性。 GPT-5.5”更少 token”的说法是一个总体平均值。个别工作负载会有差异。如果你的流量有长尾——偶尔会陷入长推理链的 agent——你可能会遇到平均值中看不到的成本峰值。GPT-5.4 的成本曲线是可预测的,你的财务团队已经接受了这一点。
这些都不是说永远不迁移,而是说不要在发布公告当天就迁移。

团队实用决策框架
按顺序回答四个问题:
- 你的工作负载是否受长上下文限制? 如果你经常运行超过 200K token 的 prompt,且检索质量是你的瓶颈,GPT-5.5 现在就值得认真测试。MRCR v2 的差值不是可以忽视的数字。
- 你的工作负载是否是智能体/多步骤/Codex 风格? 值得做并行 A/B 测试。但在测量你实际任务的 token 消耗之前,不值得全面迁移。40% 的减少是合理的,但这个说法需要你自己的数据,而不是 OpenAI 的数据。
- 你的工作负载是短上下文对话或单次生成? 留在 GPT-5.4 上。价格增幅是真实的,而这类任务的能力差距很小。读一读基准测试类别就能确认这个假设——收益集中在长链和计算机使用评估上,而不是短对话轮次上。
- 你当前是否有生产事故或容量问题? 不要在救火时迁移。新模型 + 新安全措施 + 新 token 计算,一次三个变量。在并行分支上跑对比测试。
无论属于哪种情况,切换前都需要验证的事项:你 prompt 语料库上的拒绝行为、工具调用 schema 一致性(查阅 OpenAI API 文档中的 GPT-5.5 模型页面)、路由层的端到端延迟,以及基于真实流量的一周成本预测。不是合成流量,是真实流量。

常见问题
团队现在应该从 GPT-5.4 切换吗?
默认情况下不应该。如果你受长上下文限制或运行多步骤 agent 栈,则可以切换。否则,先做两周的并行测试,在你的指标上进行比较,然后再决定。“越新越好”的反射已经让太多团队花了太多冤枉钱。
GPT-5.5 现在可以在生产中使用吗?
可以。API 自 2026 年 4 月 24 日起已上线,定价和速率限制均有文档记录。“可以使用”和”适合你的工作负载”是两个不同的问题。前者已有定论,后者需要你自己回答。
迁移前团队应该测试什么?
你的 prompt 集上的拒绝行为。具有代表性任务(非合成任务)上的 token 消耗。工具调用 schema 和结构化输出的一致性。在你真实并发量下的延迟。正常流量一整周的成本。如果任何一项不达标,就保持现状直到达标为止。
什么时候留在 GPT-5.4 上是更好的选择?
短上下文工作负载。稳定、调优完善的生产系统。对成本敏感的工作负载,其中 2 倍的定价增幅无法被你特定流量上的 token 效率抵消。处于发布周期中的团队。没有带宽重新验证拒绝行为的团队。GPT-5.4 不会被弃用。 留下来是一个有效的选择,而不是延迟的迁移。
结论
GPT-5.5 与 GPT-5.4 对生产团队来说没有单一答案。这是一个披着模型问题外衣的工作负载问题。长上下文和智能体工作负载现在有充分理由进行测试。短上下文工作负载有充分理由等待。中间的所有人都有理由跑并行对比,让数据来决定。
这就是我的数据边界。我引用的基准测试大多来自 OpenAI 自己。token 效率声明是合理的,但在他们的评估之外尚未经过验证。安全措施的差异将以系统卡无法预测的方式在生产中浮现。
用你自己的流量跑一周。那会告诉你比我说的任何话都更多的信息。
更多内容将在发布后行为稳定后陆续更新。
往期文章:





