GPT Image 2 em 2026: Vale a Pena Integrar?
Um guia voltado para desenvolvedores sobre o GPT Image 2, cobrindo acesso à API, preços, limites de taxa, suporte a edição e se está pronto para fluxos de trabalho em produção.

Dora aqui. Passei o fim de semana após o lançamento integrando o gpt-image-2 a um fluxo de trabalho que já estava rodando com o modelo anterior. Mesmos prompts, mesmas imagens de referência, mesmos tamanhos de lote. O objetivo não era me impressionar — era descobrir o que realmente muda quando você troca o ID do modelo. Sou Dora, e é esse tipo de coisa que faço antes de recomendar qualquer coisa para a equipe.
Três dias depois, tenho o suficiente para registrar. Não o suficiente para dar um veredito, mas o suficiente para apontar o que os desenvolvedores devem verificar antes de integrar.
Este artigo é para quem já publica imagens por uma API. Se você está avaliando se deve adicionar o gpt-image-2 a um fluxo de produção — junto com o que já está usando — aqui está o que eu gostaria que alguém me dissesse. O modelo é real, a API está ativa, e os limites de taxa vão te surpreender se você não ler a documentação primeiro.
O Que É o GPT Image 2 e O Que a OpenAI Lançou Oficialmente
IDs de modelo confirmados, endpoints e timing do lançamento
A OpenAI lançou o gpt-image-2 em 21 de abril de 2026, junto com a reformulação de marca “ChatGPT Images 2.0” voltada ao consumidor. O ID do modelo é gpt-image-2, com o snapshot atual fixado como gpt-image-2-2026-04-21 conforme a página oficial do modelo GPT Image 2. Ele funciona através de v1/images/generations, v1/images/edits, v1/responses e v1/chat/completions.
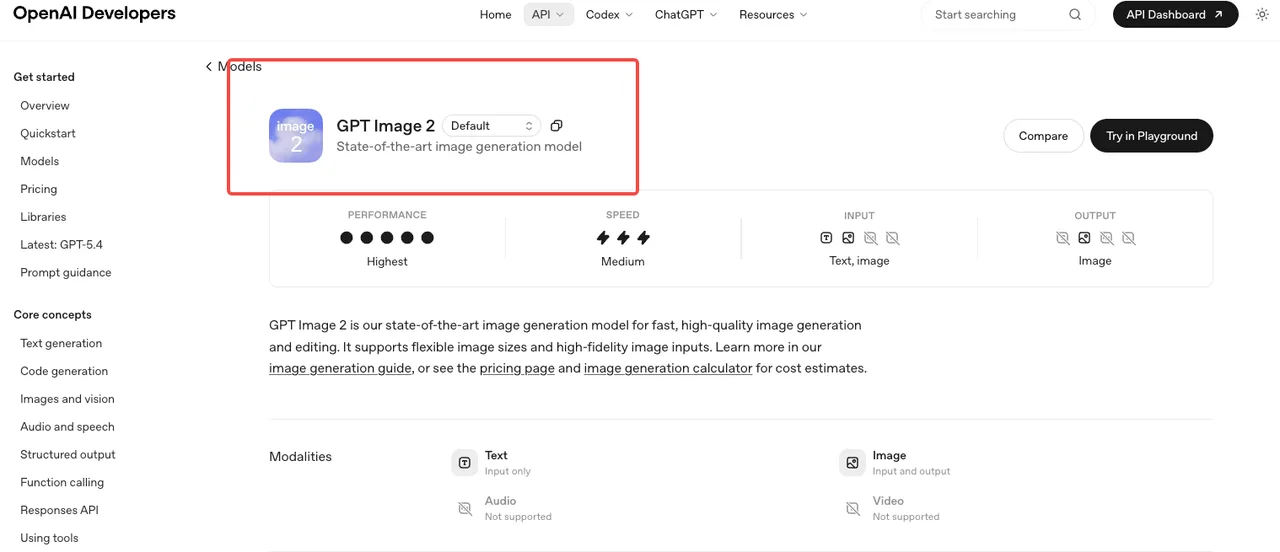 Essa é a superfície verificada. Qualquer coisa que alegue acesso antecipado à API era ou tráfego de teste A/B dentro do ChatGPT ou especulação. Use o ID do snapshot no código de produção — o alias avançará quando a OpenAI publicar uma nova versão, e esse não é um comportamento que você quer mudando no meio de um lote.
Essa é a superfície verificada. Qualquer coisa que alegue acesso antecipado à API era ou tráfego de teste A/B dentro do ChatGPT ou especulação. Use o ID do snapshot no código de produção — o alias avançará quando a OpenAI publicar uma nova versão, e esse não é um comportamento que você quer mudando no meio de um lote.
O Que Mudou em Relação aos Modelos GPT Image Anteriores
Duas coisas importam para os desenvolvedores. Primeiro, o gpt-image-2 é o primeiro modelo de imagem da OpenAI com raciocínio integrado — o que eles chamam de “modo de pensamento”, documentado no anúncio de introdução do ChatGPT Images 2.0. Antes de gerar, o modelo pode planejar o layout, buscar referências na web e verificar os resultados automaticamente. Segundo, a renderização de texto melhorou o suficiente para que layouts com múltiplos scripts — o tipo que quebrava todos os modelos comerciais anteriores — agora produzam resultados utilizáveis, conforme confirmado na entrada do GPT Image na Wikipedia cobrindo a linhagem do modelo.
Testei os dois. O modo de raciocínio é real. Também é mais lento.
Por Que o GPT Image 2 Importa para Equipes em Produção
Suporte a edição, tamanhos flexíveis e implicações para o fluxo de trabalho
A API expõe tanto geração quanto edição, o que significa que você pode passar uma imagem de referência e uma instrução em uma única chamada — sem pipeline separado de inpainting. O guia oficial de geração de imagens cobre tamanho, qualidade, formato, compressão e opções de fundo.
Um detalhe que me pegou de surpresa: fundos transparentes não são suportados atualmente através da opção de ferramenta de geração de imagens do Responses. Percebi isso no segundo dia, no meio de um lote onde eu havia assumido paridade com o modelo anterior. A saída voltou com preenchimento branco em vez de canal alpha. O lote inteiro ficou inutilizável para a etapa de composição posterior. Se seu pipeline depende de saída com canal alpha, verifique isso no seu caminho de código real antes de trocar os modelos. Perdi uma hora com isso, mais os créditos do lote com falha.
Para equipes que executam fluxos de trabalho de assets em múltiplas etapas — gerar, editar, refinar, exportar — a superfície unificada economiza uma integração real. Não porque cada etapa seja mais rápida, mas porque há uma integração a menos para manter. Menos partes móveis em produção significa menos lugares onde as coisas quebram depois.
Qualidade, latência e questões de implantação que as equipes devem considerar
A velocidade é “média”, segundo o próprio model card da OpenAI. Na prática, o modo de pensamento adiciona latência perceptível — aceitável para assets de marketing pontuais, problemático para tarefas em lote. O modo sem pensamento fica mais próximo do território do gpt-image-1.5.
A decisão não é “sempre use o modo de pensamento porque é mais inteligente.” É “use o modo de pensamento quando o layout importa, pule-o quando a velocidade importa.” Para um mockup com texto e restrições espaciais, os segundos extras resultam em um resultado utilizável na primeira tentativa. Para um lote de variações de fundo, você quer o caminho mais rápido.
Não executei lotes suficientes para fornecer um número limpo de latência. Três dias não são suficientes. O que posso confirmar: requisições no caminho frio no Nível 1 são limitadas rapidamente. O teto de 5 imagens por minuto parece generoso até que tentativas com falha e execuções de teste paralelas consumam a mesma cota. Esse não é um problema do modelo. É um problema de nível, e isso determina se isso é adequado para produção especificamente para você.
O Que os Desenvolvedores Precisam Verificar Antes da Integração
Preços, limites de taxa e funcionalidades não suportadas
Preços baseados em tokens conforme a página de preços da OpenAI: entrada de imagem custa $8 por milhão de tokens, entrada de imagem em cache $2, saída de imagem $30. Entrada de texto é $5, em cache $1,25, saída de texto $10. O nível de lote reduz esses valores pela metade. Estimativas por imagem publicadas na calculadora ficam em torno de $0,006 (baixa qualidade), $0,053 (média) e $0,211 (alta) para 1024×1024.
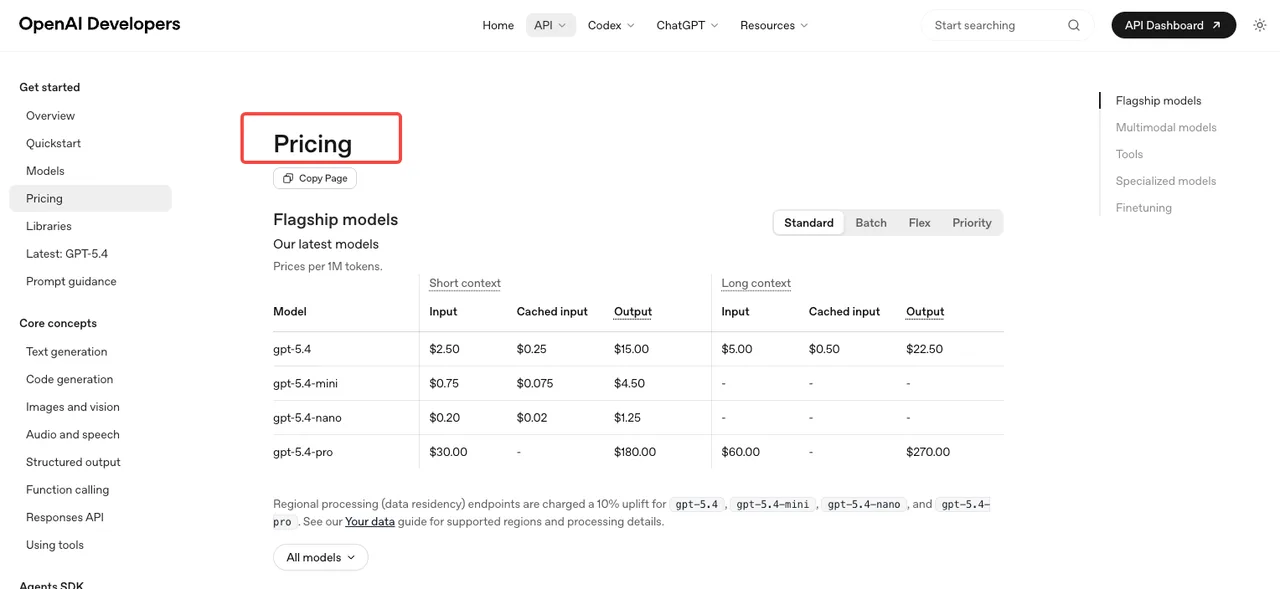
Os limites de taxa são onde as equipes são pegas de surpresa. O Nível 1 limita a 5 imagens por minuto. O Nível 2 salta para 20, o Nível 3 para 50, o Nível 5 para 250 — mas chegar ao Nível 5 requer $1.000 gastos e uma conta com 30 dias de idade, conforme documentado no guia de limites de taxa da OpenAI. Se seu produto espera tráfego em rajadas, planeje a progressão de nível antes de lançar.
Questões operacionais para uso em produção
Cinco coisas que eu verificaria em relação ao seu próprio fluxo de trabalho antes da integração:
- Se seu pipeline precisa de fundos transparentes (atualmente não suportado via ferramenta Responses)
- Qual é o seu pico de imagens por minuto sob carga realista
- Se você está executando edições com imagens de referência (essas adicionam tokens de entrada de imagem — não estime apenas pela saída)
- Se sua estratégia de prompt se beneficia do modo de raciocínio, ou se o modo sem pensamento é suficiente
- O que acontece quando uma geração falha — você tenta novamente, faz fallback ou coloca na fila
A referência da API REST de geração de imagens documenta os formatos de requisição/resposta. Leia-a antes de escrever seu wrapper.
Quando o GPT Image 2 É uma Boa Opção e Quando Não É
Boa opção: produtos onde texto aparece dentro da imagem (mockups de UI, infográficos, menus, gráficos sociais com texto), campanhas localizadas em scripts não-latinos, fluxos de trabalho que se beneficiam de uma única API para geração e edição, e equipes que já estão dentro do relacionamento de cobrança da OpenAI.
Opção mais fraca agora: pipelines de lote de alto volume em contas de Nível 1 ou Nível 2, produtos que exigem fundos transparentes através da ferramenta Responses, aplicações sensíveis à latência onde o overhead do modo de pensamento importa, e equipes cujo modelo existente já está bem ajustado e onde o custo de troca supera o ganho marginal de qualidade.
Esta não é uma situação de “use ou fique para trás.” É uma situação de “verifique contra suas próprias restrições.” O modelo é bom. Se é bom para você depende das cinco perguntas acima.
Perguntas Frequentes
O GPT Image 2 está disponível na API da OpenAI?
Sim. O ID do modelo é gpt-image-2, com snapshot gpt-image-2-2026-04-21. Ele é acessível através dos endpoints padrão de geração de imagens, edição de imagens e Responses. O nível gratuito não é suportado — você precisa de uma conta paga, com limites de taxa escalando por nível de uso.
Para quais tarefas de imagem o GPT Image 2 é melhor?
Qualquer coisa envolvendo texto dentro da imagem (menus, mockups, infográficos, gráficos multilíngues), edições orientadas por referência, e layouts que requerem raciocínio espacial. A renderização de texto é a melhoria mais significativa na prática. Para geração puramente fotorrealista sem texto, o ganho em relação ao gpt-image-1.5 é menor.
Quais limitações as equipes devem verificar primeiro?
Três concretas: fundos transparentes não são suportados através da opção de ferramenta de geração de imagens do Responses, o Nível 1 limita a geração a 5 imagens por minuto, e o modo de raciocínio adiciona latência. Vale também verificar — streaming, chamada de funções e saídas estruturadas estão listados como não suportados na página do modelo.
Está pronto para uso em produção de alto volume?
Pode estar, mas não em uma conta nova. Chegar ao Nível 3 (50 imagens/min) requer $100 gastos e uma conta com pelo menos 7 dias de idade. O Nível 5 (250 imagens/min) precisa de $1.000 gastos e um histórico de conta de 30 dias. Se você precisa de alta concorrência desde o primeiro dia, planeje a progressão de nível ou use um provedor com limites agrupados mais altos.
Como os preços se comparam ao GPT Image 1.5?
O gpt-image-2 usa cobrança por token: entrada de imagem $8/M, saída de imagem $30/M. Estimativas por imagem (1024×1024) ficam em torno de $0,006 baixa qualidade, $0,053 média, $0,211 alta. Edições com imagens de referência adicionam tokens de entrada de imagem, então o custo é maior do que as estimativas apenas de saída sugerem. Passe sua carga de trabalho real pela calculadora antes de assumir paridade com o 1.5.
Conclusão
Três dias de testes não são suficientes para dar um veredito sobre confiabilidade a longo prazo. São suficientes para dizer que o modelo é real, a API é estável, e as questões de integração são principalmente operacionais em vez de técnicas — níveis de preços, limites de taxa, funcionalidades ausentes das quais seu fluxo de trabalho pode depender. Execute um pequeno piloto com seus prompts reais e sua concorrência real antes de se comprometer. É tudo que posso confirmar daqui. O restante você precisará verificar em seu próprio ambiente.
Continuando na próxima semana com números de latência de lote assim que tiver dados suficientes para confiar neles.
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber