GPT-5.5 vs GPT-5.4 para Equipes de Produção
Compare GPT-5.5 vs GPT-5.4 sob uma perspectiva de produção: disponibilidade, cronograma de lançamento, prontidão para migração e onde cada modelo se encaixa hoje.

Olá, sou Dora. A OpenAI lançou o GPT-5.5 em 23 de abril de 2026. Menos de dois meses após o GPT-5.4. A API ficou retida por um dia, depois foi aberta em 24 de abril com o que a OpenAI chamou de “salvaguardas diferentes”. Se você está rodando um agente de codificação no GPT-5.4 hoje, a questão não é se o GPT-5.5 é mais inteligente. Os benchmarks já dizem que sim. A questão é se a sua carga de trabalho de API específica é do tipo que se beneficia o suficiente para justificar uma migração esta semana.
Estou escrevendo isso como alguém que já teve que tomar essa decisão antes. Mesma situação, número de modelo diferente. A resposta honesta é que depende de três coisas que você pode verificar em uma tarde, e uma coisa que ainda não pode verificar de forma alguma.
Este artigo é sobre como distinguir a diferença.

GPT-5.5 vs GPT-5.4 em Resumo
Disponibilidade e diferenças de lançamento
O GPT-5.5 entrou em operação em 23 de abril no ChatGPT e no Codex para os planos Plus, Pro, Business e Enterprise. A API seguiu em 24 de abril. Conforme o post oficial de lançamento do GPT-5.5 da OpenAI, o preço é $5 por 1M de tokens de entrada e $30 por 1M de tokens de saída, com uma janela de contexto de 1M. O GPT-5.5 Pro está em $30/$180 por 1M.
O GPT-5.4 permanece na tabela de preços. Você pode confirmar ambos na página oficial de preços da API da OpenAI. O GPT-5.4 padrão roda a $2,50 de entrada / $15 de saída. Portanto, a diferença de preço principal é de 2x na superfície.
O próprio enquadramento da OpenAI é que o GPT-5.5 usa menos tokens por tarefa, especialmente em cargas de trabalho do Codex, então a lacuna de custo efetivo é mais estreita do que a tabela de preços sugere. É uma afirmação razoável. É também uma afirmação que você precisa verificar no seu próprio tráfego antes de apostar um orçamento nisso.
O que é declarado oficialmente vs inferido
Declarado, com fontes: preços, paridade de latência por token vs GPT-5.4, contexto de 1M, o delta de salvaguarda no serviço de API. Declarado pela OpenAI mas vale ler com atenção: os ganhos em codificação agêntica, a pontuação no Terminal-Bench 2.0 de 82,7%, o salto na recuperação de contexto longo no MRCR v2.
Inferido e circulando: que o GPT-5.5 substituirá o GPT-5.4 na maioria das cargas de trabalho de produção “em breve”. A OpenAI não disse isso. O GPT-5.4 não está sendo descontinuado. Não planeje contra um encerramento que não está na documentação.
Fiz uma pausa quando li a cobertura do TechCrunch sobre o lançamento do GPT-5.5 — o enquadramento se apoia fortemente na ambição de “super app”, que é uma história de estratégia, não um gatilho de migração.
Onde o GPT-5.5 Parece Mais Forte
Afirmações sobre codificação agêntica e uso do computador
Os deltas de benchmark que a OpenAI publicou são números reais, mas são avaliações da própria OpenAI. Tome-os como direcionais, não como verdade absoluta.
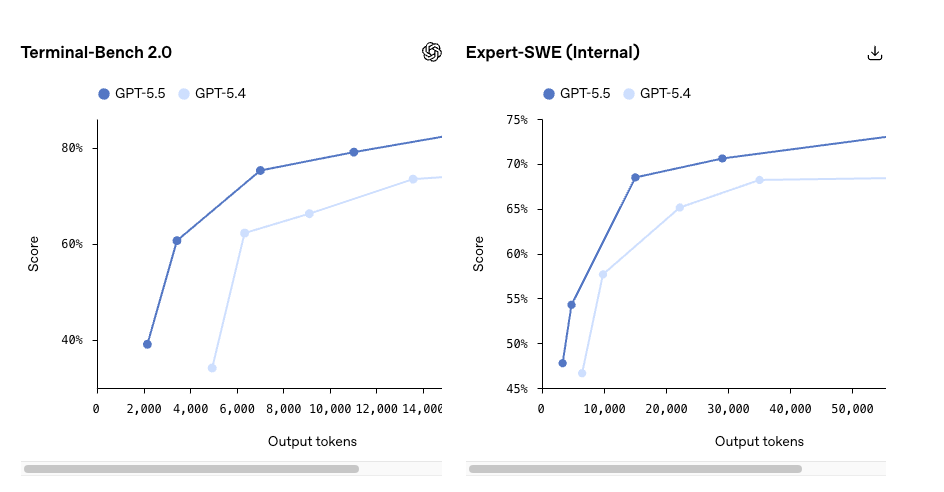
- Terminal-Bench 2.0: 82,7% (GPT-5.5) vs 75,1% (GPT-5.4)
- SWE-Bench Pro: 58,6% vs o intervalo anteriormente reportado de 55–57% da OpenAI
- OSWorld-Verified (uso do computador): 78,7%
- MRCR v2 recuperação de contexto longo (512K–1M): 74,0% vs 36,6%
Esse último é o que eu realmente prestaria atenção. Um salto de 37 pontos na recuperação de contexto longo é o tipo de delta que muda o que é viável, não apenas o que é mais rápido. Se a sua carga de trabalho rotineiramente ultrapassa 256K tokens — bases de código inteiras, rastros de agentes de várias horas, conjuntos completos de documentos — é aqui que a história da atualização se torna real.
Se a sua carga de trabalho são completamentos de chat de contexto curto e saídas estruturadas, nada disso se aplica a você. Melhor do que o esperado, mas apenas ligeiramente.
Implicações de eficiência e fluxo de trabalho
A afirmação da OpenAI é que o GPT-5.5 usa aproximadamente 40% menos tokens de saída para tarefas equivalentes do Codex. Se isso se confirmar no seu tráfego, o aumento de 2x na tabela de preços se comprime para algo como um aumento efetivo de 20%. Isso é uma diferença significativa na matemática de migração.
Também significa que você não pode confiar nas suas projeções de custo existentes. A contabilidade de tokens muda. Execute uma carga de trabalho real por uma semana antes de extrapolar.
Por Que o GPT-5.4 Ainda Pode Ser a Melhor Escolha de API Hoje
Três razões pelas quais esta não é uma atualização limpa.
Um: comportamento de recusa. A OpenAI lançou o GPT-5.5 com um conjunto de salvaguardas mais forte — eles chamam de o conjunto mais robusto até hoje. O quadro completo está no system card do GPT-5.5. Para a maioria das equipes, isso é invisível. Para equipes que executam cargas de trabalho de uso duplo, segurança ou agênticas próximas às bordas de política, a superfície de recusa mudou, e mudou de formas que o system card não enumera completamente. Execute seu conjunto de prompts existente através dele antes de assumir paridade de comportamento.
Dois: estabilidade de ferramentas. Esquemas de chamada de ferramentas, comportamento de saída estruturada sob esforço de raciocínio, chamadas de ferramentas paralelas — essas superfícies tendem a se desviar entre gerações de modelos. O contrato que você ajustou no GPT-5.4 não é garantido. Você encontrará os deltas mais rapidamente reproduzindo o tráfego de produção do que lendo a documentação.
Três: previsibilidade de custo sob carga irregular. A afirmação de “menos tokens” do GPT-5.5 é uma média populacional. Cargas de trabalho individuais variam. Se o seu tráfego tem caudas longas — agentes que ocasionalmente se perdem em longas cadeias de raciocínio — você pode ter picos de custo que não aparecem na média. O GPT-5.4 tem um formato de custo previsível que o seu time financeiro já aceitou.
Nada disso significa ficar para sempre. Significa não migrar no anúncio.

Um Framework Prático de Decisão para Equipes
Quatro perguntas, nesta ordem:
- A sua carga de trabalho é limitada por contexto longo? Se você rotineiramente executa prompts acima de 200K tokens e a qualidade de recuperação é o seu teto, o GPT-5.5 provavelmente vale um teste sério agora. O delta do MRCR v2 não é o tipo de número que você ignora.
- A sua carga de trabalho é agêntica / multi-etapas / estilo Codex? Vale um A/B paralelo. Não vale uma migração completa até que você tenha medido o consumo de tokens nas suas tarefas reais. A redução de 40% é plausível. É também uma afirmação que precisa dos seus dados, não dos da OpenAI.
- A sua carga de trabalho é chat de contexto curto ou geração de disparo único? Fique no GPT-5.4. O aumento de preço é real e o delta de capacidade nessas tarefas é pequeno. Hipótese confirmada ao ler as categorias de benchmark — os ganhos se concentram em avaliações de longo horizonte e uso do computador, não em turnos curtos.
- Você tem um incidente de produção atual ou problema de capacidade? Não migre durante um incêndio. Novo modelo + novas salvaguardas + nova contabilidade de tokens são três mudanças de uma vez. Execute a comparação em um branch paralelo.
Coisas a verificar antes de qualquer mudança, independentemente da categoria: comportamento de recusa no seu corpus de prompts, paridade de esquema de chamada de ferramentas (verifique a página do modelo GPT-5.5 na documentação da API da OpenAI), latência de ponta a ponta na sua camada de roteamento e uma projeção de custo de uma semana com tráfego real. Não sintético. Tráfego real.

FAQ
As equipes devem migrar do GPT-5.4 agora?
Não por padrão. Migre se você estiver limitado por contexto longo ou executando uma pilha de agentes multi-etapas. Caso contrário, execute um teste paralelo por duas semanas, compare nas suas métricas e então decida. O reflexo de “mais novo é melhor” custou mais dinheiro a mais equipes do que eu quero contar.
O GPT-5.5 é utilizável em produção hoje?
Sim. A API está ativa desde 24 de abril de 2026, com preços e limites de taxa documentados. “Utilizável” e “apropriado para a sua carga de trabalho” são perguntas diferentes. A primeira está resolvida. A segunda é sua para responder.
O que as equipes devem testar antes de migrar?
Comportamento de recusa no seu conjunto de prompts. Consumo de tokens em tarefas representativas (não sintéticas). Paridade de esquema de chamada de ferramentas e saída estruturada. Latência na sua concorrência real. Custo ao longo de uma semana completa de tráfego normal. Se algum desses quebrar, fique onde está até que não quebrem mais.
Quando ficar no GPT-5.4 é a melhor decisão?
Cargas de trabalho de contexto curto. Sistemas de produção estáveis e bem ajustados. Cargas de trabalho sensíveis a custo onde o aumento de 2x na tabela de preços não é compensado pela eficiência de tokens no seu tráfego específico. Equipes no meio de um ciclo de lançamento. Equipes sem largura de banda para revalidar o comportamento de recusa. O GPT-5.4 não está sendo descontinuado. Ficar é uma decisão válida, não uma migração adiada.
Conclusão
A resposta para GPT-5.5 vs GPT-5.4 para equipes de produção não é uma resposta única. É uma questão de carga de trabalho disfarçada de questão de modelo. Cargas de trabalho de contexto longo e agênticas têm uma razão real para testar agora. Cargas de trabalho de contexto curto têm uma razão real para esperar. Todos no meio têm uma razão para executar a comparação paralela e deixar os dados decidirem.
É onde meus dados terminam. Os benchmarks que estou citando são principalmente da própria OpenAI. A afirmação de eficiência de tokens é plausível, mas não verificada fora das avaliações deles. O delta de salvaguarda surgirá em produção de formas que o system card não prevê.
Execute você mesmo no seu tráfego por uma semana. Isso vai te dizer mais do que qualquer coisa que eu possa dizer.
Mais informações quando o comportamento pós-lançamento se estabilizar.
Posts Anteriores:
- GPT-5.5 para Construtores: Capacidades da API, Preços e Quando Atualizar
- Versões do Modelo GPT-5 Explicadas: Diferenças, Casos de Uso e Caminhos de Migração
- GPT-5.4 vs GPT-5.3: O Que Mudou para Desenvolvedores e Cargas de Trabalho de API
- Padrões de Fluxo de Trabalho Agêntico: Fiação de Ferramentas, Armadilhas e Trade-offs do Mundo Real
- DeepSeek V4 Pro vs Flash: Trade-offs de Custo, Velocidade e Desempenho
Artigos relacionados

Claude Fable 5 Chegou: 80,3% no SWE-Bench Pro, Preço 2× do Opus 4.8, Gratuito até 22 de junho

Como Escolher uma API de Mídia com IA para Apps Codex (2026)

API Hunyuan 3D: O Que os Desenvolvedores Precisam Saber

Hunyuan 3D vs Hyper3D vs Pixal3D

Construindo Aplicativos de Vídeo com IA Usando Agentes de Codificação
