GPT Image 2(2026年版):統合する価値はあるか?
APIアクセス、料金、レート制限、編集サポート、プロダクションワークフローへの対応状況を解説する、ビルダー向けGPT Image 2完全ガイド。

こんにちは、Doraです。ローンチ後の週末を使って、既に稼働していたワークフローにgpt-image-2を組み込みました。前のモデルと同じプロンプト、同じ参照画像、同じバッチサイズで試しました。目的は感動することではなく、モデルIDを切り替えたときに何が実際に変わるのかを確認することでした。私はDoraで、チームに何かを推薦する前にこういったことを調べるのが私のスタイルです。
3日間テストして、書き留めておくだけの情報が集まりました。まだ最終的な評価を下すには不十分ですが、インテグレーション前にビルダーが確認すべき点を挙げるには十分です。
この記事は、すでにAPIを通じて画像を配信している方向けです。gpt-image-2を本番ワークフローに追加することを検討しているなら — 現在使っているものと並行して — 誰かに事前に教えてほしかったことをまとめました。モデルは実在し、APIは稼働中で、ドキュメントを読まないとレート制限に驚くことになります。
GPT Image 2とは何か、OpenAIが公式にリリースしたもの
確認済みのモデルID、エンドポイント、ローンチタイミング
OpenAIは2026年4月21日に、コンシューマー向けの「ChatGPT Images 2.0」リブランドと同時にgpt-image-2をローンチしました。モデルIDはgpt-image-2で、現在のスナップショットは公式GPT Image 2モデルページによるとgpt-image-2-2026-04-21としてピン留めされています。v1/images/generations、v1/images/edits、v1/responses、v1/chat/completionsを通じて動作します。
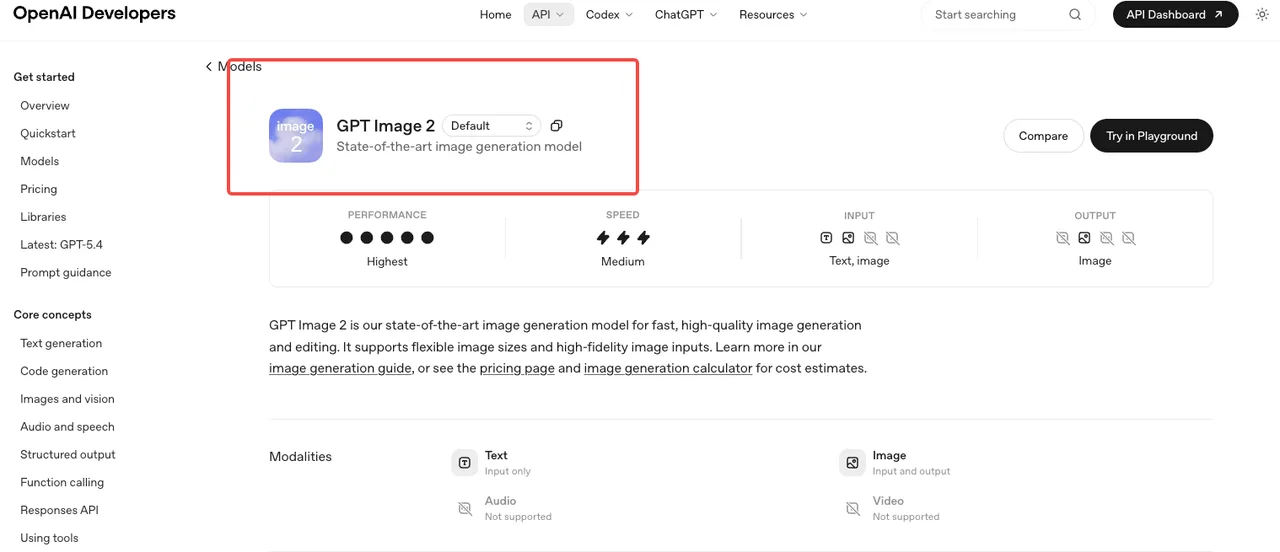 これが確認済みの仕様です。それ以前のAPIアクセスを主張するものは、ChatGPT内のA/Bテストトラフィックか推測のいずれかです。本番コードにはスナップショットIDを使用してください — エイリアスはOpenAIが新バージョンを公開するたびに更新されますが、バッチ処理の途中でその挙動が変わるのは避けたいはずです。
これが確認済みの仕様です。それ以前のAPIアクセスを主張するものは、ChatGPT内のA/Bテストトラフィックか推測のいずれかです。本番コードにはスナップショットIDを使用してください — エイリアスはOpenAIが新バージョンを公開するたびに更新されますが、バッチ処理の途中でその挙動が変わるのは避けたいはずです。
以前のGPT Imageモデルからの変更点
ビルダーにとって重要な点が2つあります。まず、gpt-image-2はリーズニングが組み込まれた最初のOpenAI画像モデルです — 彼らが「thinking mode(思考モード)」と呼ぶもので、ChatGPT Images 2.0の紹介アナウンスにドキュメント化されています。生成前に、モデルはレイアウトを計画し、参照用にウェブを検索し、出力を自己チェックできます。次に、テキストレンダリングが大幅に改善され、以前の商用モデルではすべて壊れていた混合スクリプトレイアウトが使用可能な結果を生成できるようになりました。これはモデルの系譜を扱うWikipediaのGPT Imageエントリでも確認されています。
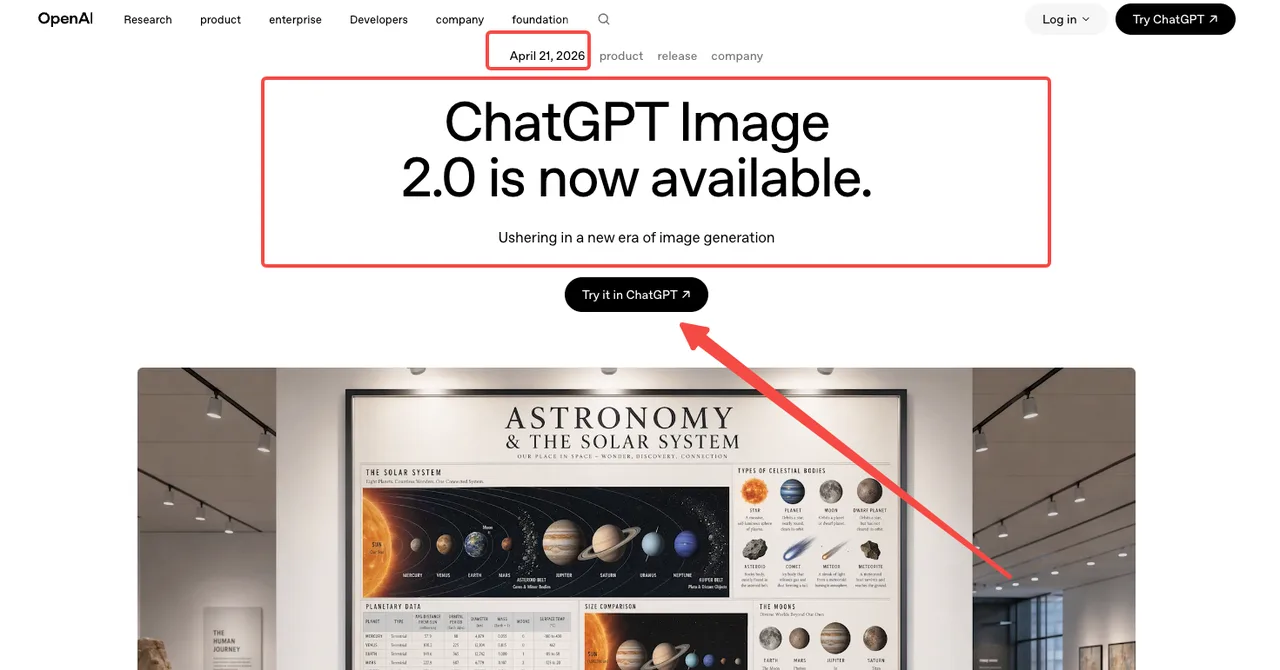
両方テストしました。リーズニングモードは本物です。ただし、遅くもあります。
なぜGPT Image 2が本番チームにとって重要か
編集サポート、柔軟なサイズ、ワークフローへの影響
APIは生成と編集の両方を公開しているため、1回のコールで参照画像と指示を渡すことができます — 別のインペインティングパイプラインは不要です。公式画像生成ガイドには、サイズ、品質、フォーマット、圧縮、背景オプションが記載されています。
私がハマった詳細が1つあります:透明背景は現在、Responsesの画像生成ツールオプションでサポートされていません。 前のモデルと同等だと思い込んでバッチ処理の途中、2日目に気づきました。出力はアルファチャンネルではなく白い塗りつぶしで返ってきました。バッチ全体が後続のコンポジット処理ステップで使用不可になりました。パイプラインがアルファ出力に依存している場合は、モデルを切り替える前に実際のコードパスで確認してください。この問題で1時間と失敗したバッチのクレジットを失いました。
マルチステップのアセットワークフロー — 生成、編集、リファイン、エクスポート — を実行しているチームにとって、統合されたサーフェスは実際にハンドオフを節約します。各ステップが速くなるからではなく、維持するインテグレーションが1つ減るからです。本番環境で可動部分が少ないということは、後で壊れる箇所も少ないということです。
チームが確認すべき品質、レイテンシ、ロールアウトの質問
スピードはOpenAI自身のモデルカードによると「medium(中程度)」です。実際には、thinking modeは顕著なレイテンシを追加します — 単発のマーケティングアセットには問題ありませんが、バッチジョブには辛いです。non-thinking modeはgpt-image-1.5に近い領域です。
判断は「賢いからthinking modeを常に使う」ではありません。「レイアウトが重要なときにthinking modeを使い、スピードが重要なときはスキップする」です。テキストと空間的制約のあるモックアップなら、余分な数秒で最初の試みから使用可能な結果が得られます。背景バリエーションのバッチなら、速いパスが欲しいでしょう。
クリーンなレイテンシの数値を出せるほどのバッチはまだ実行していません。3日間では不十分です。確認できること:Tier 1のコールドパスリクエストは素早くスロットリングされます。 毎分5枚という上限は、失敗したリトライと並行テスト実行が同じクォータを消費するまでは余裕があるように聞こえます。これはモデルの問題ではありません。ティアの問題であり、特定の環境でこれが本番対応かどうかを左右します。
インテグレーション前にビルダーが確認すべきこと
価格、レート制限、未サポート機能
OpenAI価格ページによるトークンベースの価格:画像入力は100万トークンあたり$8、キャッシュ済み画像入力$2、画像出力$30。テキスト入力は$5、キャッシュ済み$1.25、テキスト出力$10。バッチティアはこれらを半額にします。計算ツールで公表されている1枚あたりの推定値は1024×1024で約$0.006(低品質)、$0.053(中品質)、$0.211(高品質)です。
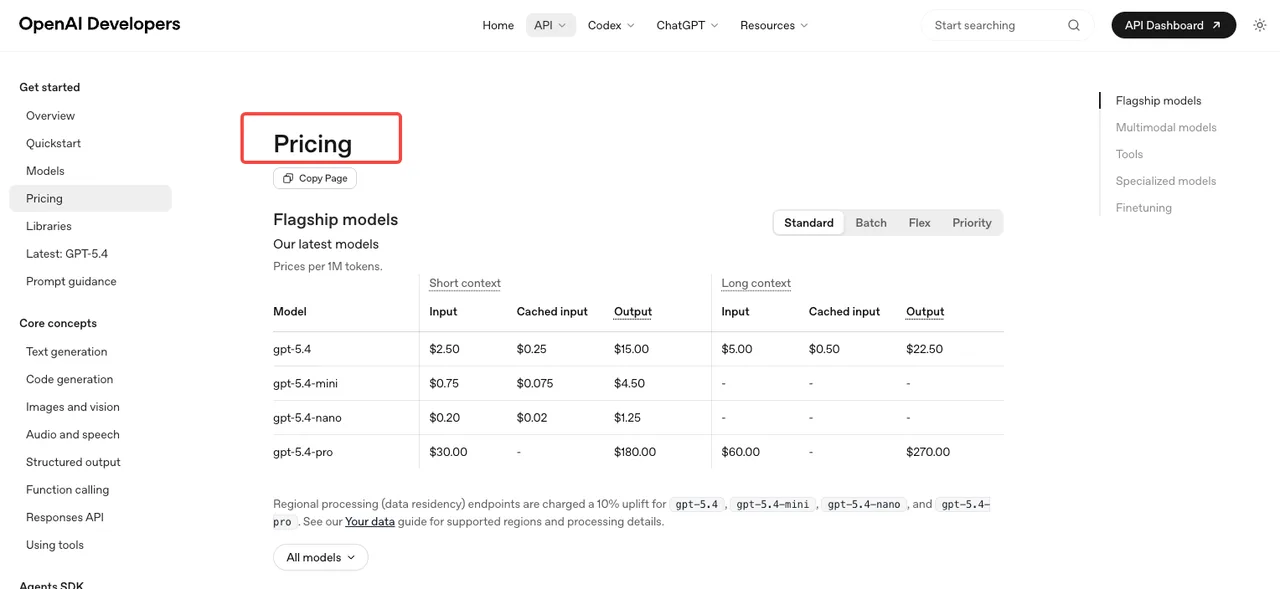
チームがよくハマるのはレート制限です。Tier 1は毎分5枚が上限です。Tier 2は20枚、Tier 3は50枚、Tier 5は250枚まで跳ね上がりますが、OpenAIレート制限ガイドにドキュメント化されているように、Tier 5に達するには$1,000の利用実績と30日以上のアカウント履歴が必要です。プロダクトがバースト的なトラフィックを想定している場合は、ローンチ前にティア上昇計画を立ててください。
本番利用のための運用上の質問
インテグレーション前に自分のワークフローで確認すべき5つの点:
- パイプラインが透明背景を必要とするか(現在Responsesツールではサポートされていない)
- 現実的な負荷でのピーク毎分画像数
- 参照画像を使った編集を実行しているか(画像入力トークンが加算されるため、出力のみの推定からコストが増える)
- プロンプト戦略がリーズニングモードの恩恵を受けるか、non-thinkingで十分か
- 生成が失敗した場合どうするか — リトライ、フォールバック、またはキュー
REST画像生成APIリファレンスにはリクエスト/レスポンスの形式が記載されています。ラッパーを書く前に読んでください。
GPT Image 2が強い適合性を示す場合とそうでない場合
強い適合性: 画像内にテキストが表示されるプロダクト(UIモックアップ、インフォグラフィック、メニュー、コピー入りのソーシャルグラフィック)、非ラテン文字のローカライズキャンペーン、生成と編集の両方に単一のAPIを活用するワークフロー、そしてすでにOpenAIの課金関係にあるチーム。
現時点での弱い適合性: Tier 1またはTier 2アカウントでの大容量バッチパイプライン、Responsesツールを通じた透明背景が必要なプロダクト、thinking modeのオーバーヘッドが影響するレイテンシ重視のアプリケーション、そして既存のモデルがすでに調整済みで切り替えコストが品質向上を上回るチーム。
これは「使わなければ取り残される」という状況ではありません。「自分の制約に対して確認する」という状況です。モデルは優れています。それがあなたにとって優れているかどうかは、上記の5つの質問次第です。
FAQ
GPT Image 2はOpenAI APIで利用できますか?
はい。モデルIDはgpt-image-2で、スナップショットはgpt-image-2-2026-04-21です。標準の画像生成、画像編集、Responsesエンドポイントを通じてアクセス可能です。Freeティアはサポートされていません — 有料アカウントが必要で、レート制限は利用ティアによってスケールします。
GPT Image 2が最も得意な画像タスクは何ですか?
画像内のテキストを含むもの(メニュー、モックアップ、インフォグラフィック、多言語グラフィック)、参照画像を使った編集、空間的推論が必要なレイアウトです。テキストレンダリングが最も実用的に重要なアップグレードです。テキストなしの純粋なフォトリアリスティックな生成では、gpt-image-1.5からの向上は小さいです。
チームが最初に確認すべき制限事項は何ですか?
具体的に3つ:Responsesの画像生成ツールオプションでは透明背景がサポートされていない、Tier 1は毎分5枚の生成が上限、リーズニングモードはレイテンシを追加します。また確認しておく価値があるのは、ストリーミング、ファンクションコーリング、構造化出力がモデルページで非サポートとして記載されている点です。
大容量の本番利用に対応していますか?
対応できますが、新規アカウントでは難しいです。Tier 3(毎分50枚)に達するには$100の利用実績とアカウント作成から少なくとも7日が必要です。Tier 5(毎分250枚)には$1,000の利用実績と30日のアカウント履歴が必要です。初日から高い並行性が必要な場合は、ティア上昇を計画するか、より高いプール制限を持つプロバイダーを使用してください。
GPT Image 1.5と比べて価格はどうですか?
gpt-image-2はトークンベースの課金を使用します:画像入力$8/M、画像出力$30/M。1枚あたりの推定値(1024×1024)は低品質で約$0.006、中品質で$0.053、高品質で$0.211です。参照画像を使った編集は画像入力トークンを追加するため、コストは出力のみの推定より高くなります。1.5との同等性を仮定する前に、実際のワークロードを計算ツールで実行してください。
まとめ
3日間のテストは長期的な信頼性について最終評価を下すには不十分です。ただ、モデルは実在し、APIは安定しており、インテグレーションの質問は技術的というより運用的なもの — 価格ティア、レート制限、ワークフローが依存する可能性のある未サポート機能 — であることは言えます。本番環境にコミットする前に、実際のプロンプトと実際の並行性に対して小規模なパイロットを実行してください。 ここから確認できるのはそれだけです。残りは自分の環境で確認する必要があります。
来週、信頼できるデータが集まった時点でバッチレイテンシの数値を続けてお届けします。
過去の投稿:





