プロダクションチームのためのGPT-5.5 vs GPT-5.4比較
GPT-5.5とGPT-5.4をプロダクションの視点から比較します:可用性、ロールアウトのタイミング、移行の準備状況、そして現時点での各モデルの適切な用途。

こんにちは、Doraです。OpenAIは2026年4月23日にGPT-5.5をリリースしました。GPT-5.4からわずか2ヶ月も経たないうちにです。APIは1日遅れで公開され、4月24日にOpenAIが「異なるセーフガード」と表現した形で提供が開始されました。現在GPT-5.4でコーディングエージェントを動かしているなら、問題はGPT-5.5が賢いかどうかではありません。ベンチマークはすでにそれを証明しています。問題は、あなたの特定のAPIワークロードが、今週マイグレーションを正当化できるほどの恩恵を受けられる種類のものかどうかです。
私はこの判断を以前にも迫られた経験者として書いています。同じ状況で、モデルの番号が違うだけです。正直に言えば、午後の時間で確認できる3つのことと、まだ全く確認できない1つのことに依存します。
この記事は、その違いを見極める方法についてです。

GPT-5.5 vs GPT-5.4 概要
提供状況とロールアウトの違い
GPT-5.5は4月23日にChatGPTおよびCodexでPlus、Pro、Business、Enterpriseの各ティアで公開されました。APIは4月24日に続きました。OpenAIのGPT-5.5公式発表によると、価格は入力100万トークンあたり$5、出力100万トークンあたり$30で、コンテキストウィンドウは100万トークンです。GPT-5.5 Proは100万トークンあたり$30/$180となっています。
GPT-5.4はレートカードに残ります。両方の詳細はOpenAIの公式APIpricing pageで確認できます。GPT-5.4標準は入力$2.50/出力$15です。つまり、表面上の価格差は2倍です。
OpenAI自身の主張は、GPT-5.5はタスクあたりのトークン数が少なく、特にCodexワークロードでそれが顕著なため、実質的なコスト差はレートカードが示すよりも小さいというものです。これは合理的な主張です。ただし、それは予算を賭ける前に自分のトラフィックで確認する必要がある主張でもあります。
公式に述べられていることと推測されること
出典付きで述べられていること:価格、GPT-5.4との1トークンあたりのレイテンシーパリティ、100万コンテキスト、API提供のセーフガードの差異。OpenAIが述べているが注意深く読む価値があること:エージェント型コーディングの向上、Terminal-Bench 2.0スコア82.7%、MRCR v2での長文コンテキスト検索の大幅改善。
推測されて広まっていること:GPT-5.5が「間もなく」ほとんどの本番ワークロードでGPT-5.4を置き換えるという話。OpenAIはそう言っていません。GPT-5.4は非推奨化されていません。ドキュメントに記載されていない廃止予定を前提に計画を立てないでください。
TechCrunchのGPT-5.5ローンチ記事を読んだ時、私は立ち止まりました。フレーミングが「スーパーアプリ」の野望に強く傾いており、それは戦略の話であって、マイグレーションのトリガーではありません。
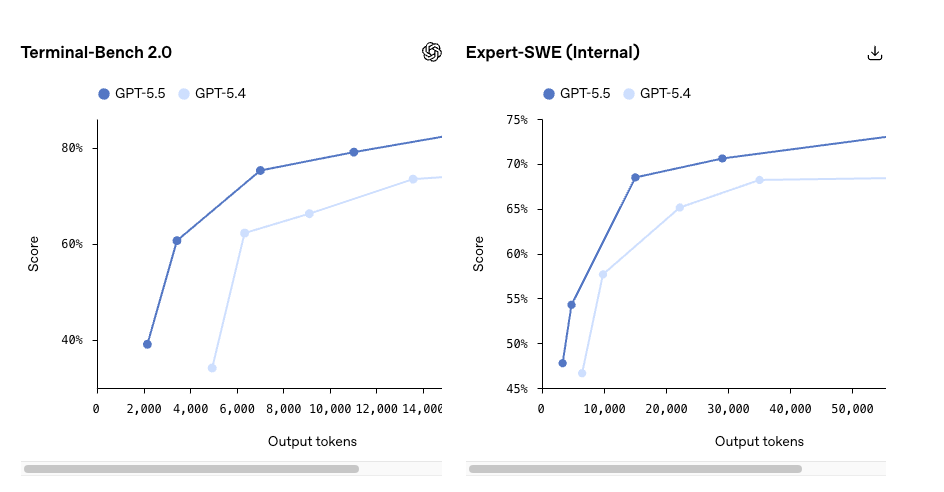
GPT-5.5が優れていると思われる点
エージェント型コーディングとコンピューター操作の主張
OpenAIが公開したベンチマークのデルタは実際の数値ですが、OpenAI自身のevalです。方向性の指標として受け取り、確定的な事実として扱わないでください。
- Terminal-Bench 2.0:82.7%(GPT-5.5)vs 75.1%(GPT-5.4)
- SWE-Bench Pro:58.6% vs OpenAIが以前報告していた55〜57%の範囲
- OSWorld-Verified(コンピューター操作):78.7%
- MRCR v2長文コンテキスト検索(512K〜1M):74.0% vs 36.6%
最後の数値が私が実際に注目するものです。長文コンテキスト検索での37ポイントの向上は、単に速くなるだけでなく、何が実現可能かを変える種類のデルタです。 ワークロードが日常的に256Kトークンを超える場合—コードベース全体、数時間のエージェントトレース、完全なドキュメントセットなど—ここでアップグレードの話が現実になります。
ワークロードが短文コンテキストのチャット補完と構造化出力であれば、それは何も関係ありません。予想よりは良いですが、わずかです。
効率とワークフローへの影響
OpenAIの主張は、GPT-5.5は同等のCodexタスクに対して約40%少ない出力トークンを使用するというものです。それがあなたのトラフィックでも成立すれば、2倍のレートカード増加は実質的に約20%の増加に圧縮されます。これはマイグレーションの計算において意味のある差異です。
それはまた、既存のコスト予測を信頼できないことも意味します。トークンの計算が変わります。外挿する前に、1週間実際のワークロードで実行してみてください。
なぜGPT-5.4が今日でもより良いAPI選択かもしれないのか
これがクリーンなアップグレードではない3つの理由。
その1:拒否動作。 OpenAIはGPT-5.5をより強力なセーフガードスイートとともにリリースしました—彼らはそれをこれまで最強のセットと呼んでいます。完全な詳細はGPT-5.5システムカードにあります。ほとんどのチームにとってこれは見えません。デュアルユース、セキュリティ、またはポリシーの境界近くでエージェント型ワークロードを実行しているチームにとっては、拒否の表面が変化しており、システムカードが完全に列挙していない方法で変化しています。動作のパリティを前提とする前に、既存のプロンプトセットを実行してみてください。
その2:ツールの安定性。 ツール呼び出しスキーマ、推論努力下での構造化出力動作、並列ツール呼び出し—これらの表面はモデル世代間でドリフトする傾向があります。GPT-5.4でチューニングした契約が保持される保証はありません。ドキュメントを読むよりも、本番トラフィックを再生する方がデルタを早く見つけられます。
その3:バースト負荷下でのコスト予測可能性。 GPT-5.5の「少ないトークン」という主張は母集団平均です。個々のワークロードは異なります。トラフィックに長い尾がある場合—エージェントが時折長い推論チェーンに陥る場合—平均には現れないコストスパイクが発生する可能性があります。GPT-5.4には、財務チームがすでに受け入れた予測可能なコスト形状があります。
これはいつまでも留まれという意味ではありません。発表でマイグレーションしないという意味です。

チームのための実用的な意思決定フレームワーク
この順序で4つの質問:
- ワークロードは長文コンテキストに縛られていますか? 200Kトークンを超えるプロンプトを定期的に実行していて、検索品質が上限であれば、GPT-5.5は今すぐ真剣にテストする価値があります。MRCR v2のデルタは無視できる数値ではありません。
- ワークロードはエージェント型/マルチステップ/Codexスタイルですか? 並列A/Bの価値はあります。実際のタスクでトークン消費量を測定するまでは、完全なマイグレーションの価値はありません。40%削減は妥当です。ただし、OpenAIのデータではなく、あなたのデータで検証が必要な主張です。
- ワークロードは短文コンテキストのチャットまたは単発生成ですか? GPT-5.4に留まってください。価格上昇は現実で、これらのタスクでの能力デルタは小さいです。ベンチマークカテゴリを読んで確認された仮説です—向上は長期的な地平線とコンピューター操作のevalに集中しており、短いターンには集中していません。
- 現在本番インシデントや容量問題がありますか? 火事の最中にマイグレーションしないでください。新しいモデル + 新しいセーフガード + 新しいトークン計算は一度に3つの変更です。並列ブランチで比較を実行してください。
カテゴリに関わらず、切り替え前に確認すべきこと:プロンプトコーパスの拒否動作、ツール呼び出しスキーマのパリティ(OpenAI APIドキュメントのGPT-5.5モデルページを確認)、ルーティングレイヤーのエンドツーエンドレイテンシー、実際のトラフィックでの1週間のコスト予測。合成ではなく、実際のトラフィックで。

よくある質問
チームは今すぐGPT-5.4から切り替えるべきですか?
デフォルトでは不要です。長文コンテキストに縛られている場合、またはマルチステップエージェントスタックを実行している場合は切り替えてください。そうでなければ、2週間並列テストを実行し、メトリクスで比較してから決定してください。「新しい方が良い」という反射は、私が数えたくないほど多くのチームに多くのお金を失わせてきました。
GPT-5.5は今日から本番で使用できますか?
はい。APIは2026年4月24日からドキュメント化された価格とレート制限で稼働しています。「使用可能」と「あなたのワークロードに適切」は別の問題です。最初の問いは解決済みです。2番目はあなたが答えるものです。
マイグレーション前にチームがテストすべきことは?
プロンプトセットの拒否動作。代表的なタスク(合成ではなく)でのトークン消費量。ツール呼び出しスキーマと構造化出力のパリティ。実際の同時実行数でのレイテンシー。通常トラフィックの1週間全体でのコスト。これらのいずれかが壊れたら、解決するまで留まってください。
GPT-5.4に留まる方が良い選択はいつですか?
短文コンテキストのワークロード。安定した、よくチューニングされた本番システム。特定のトラフィックでのトークン効率で2倍のレートカード増加が相殺されないコスト重視のワークロード。リリースサイクルの途中にいるチーム。拒否動作を再検証する余裕のないチーム。GPT-5.4は非推奨化されていません。 留まることは有効な選択であり、遅延したマイグレーションではありません。
まとめ
本番チームにとってGPT-5.5 vs GPT-5.4の答えは1つではありません。モデルの問題に見せかけたワークロードの問題です。長文コンテキストとエージェント型ワークロードには今すぐテストする本当の理由があります。短文コンテキストワークロードには待つ本当の理由があります。中間にいる人全員には、並列比較を実行してデータに決めさせる理由があります。
これが私のデータの終わりです。引用しているベンチマークはほとんどOpenAI自身のものです。トークン効率の主張は妥当ですが、彼らのevalの外では未検証です。セーフガードのデルタはシステムカードが予測しない方法で本番で表面化します。
1週間、自分のトラフィックで自分自身で実行してください。それが私が言えることよりも多くを教えてくれます。
ローンチ後の動作が落ち着いたら続報をお届けします。
関連記事:
- GPT-5.5 for Builders: API Capabilities, Pricing, and When to Upgrade
- GPT-5 Model Versions Explained: Differences, Use Cases, and Migration Paths
- GPT-5.4 vs GPT-5.3: What Changed for Developers and API Workloads
- Agentic Workflow Patterns: Tool Wiring, Pitfalls, and Real-World Tradeoffs
- DeepSeek V4 Pro vs Flash: Cost, Speed, and Performance Trade-offs





