GPT Image 2 en 2026 : Vaut-il la peine d'être intégré ?
Un guide orienté développeurs sur GPT Image 2 couvrant l'accès à l'API, la tarification, les limites de débit, la prise en charge de l'édition et sa maturité pour les workflows de production.

Dora ici. J’ai passé le week-end après le lancement à intégrer gpt-image-2 dans un workflow que j’avais déjà en production avec le modèle précédent. Mêmes prompts, mêmes images de référence, mêmes tailles de lots. L’objectif n’était pas d’être impressionnée — il s’agissait de comprendre ce qui change réellement quand on modifie l’identifiant du modèle. Je suis Dora, et c’est exactement ce que je fais avant de recommander quoi que ce soit à l’équipe.
Après trois jours, j’ai suffisamment d’éléments à consigner. Pas assez pour rendre un verdict, mais assez pour signaler ce que les développeurs doivent vérifier avant d’intégrer.
Cet article s’adresse à ceux qui diffusent déjà des images via une API. Si vous évaluez l’opportunité d’ajouter gpt-image-2 à un workflow en production — en parallèle de ce que vous utilisez actuellement — voici ce que j’aurais aimé qu’on me dise. Le modèle est réel, l’API est en ligne, et les limites de débit vous surprendront si vous ne lisez pas la documentation au préalable.
Ce qu’est GPT Image 2 et ce qu’OpenAI a officiellement publié
Identifiants de modèle confirmés, endpoints et calendrier de lancement
OpenAI a lancé gpt-image-2 le 21 avril 2026, en parallèle du rebranding grand public “ChatGPT Images 2.0”. L’identifiant du modèle est gpt-image-2, avec le snapshot actuel épinglé sous gpt-image-2-2026-04-21 selon la page officielle du modèle GPT Image 2. Il fonctionne via v1/images/generations, v1/images/edits, v1/responses et v1/chat/completions.
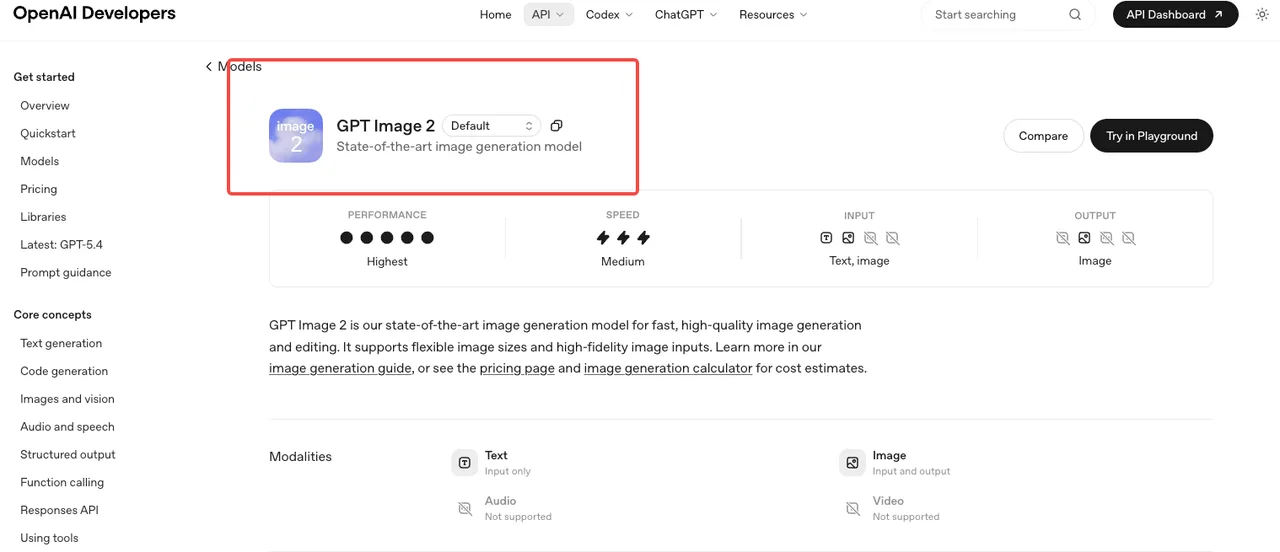 C’est la surface vérifiée. Tout ce qui prétendait offrir un accès API anticipé était soit du trafic de test A/B au sein de ChatGPT, soit de la spéculation. Utilisez l’identifiant de snapshot dans votre code de production — l’alias se mettra à jour quand OpenAI publiera une nouvelle version, et ce n’est pas un comportement que vous souhaitez voir changer en plein milieu d’un traitement par lot.
C’est la surface vérifiée. Tout ce qui prétendait offrir un accès API anticipé était soit du trafic de test A/B au sein de ChatGPT, soit de la spéculation. Utilisez l’identifiant de snapshot dans votre code de production — l’alias se mettra à jour quand OpenAI publiera une nouvelle version, et ce n’est pas un comportement que vous souhaitez voir changer en plein milieu d’un traitement par lot.
Ce qui a changé par rapport aux modèles GPT Image précédents
Deux éléments importent pour les développeurs. Premièrement, gpt-image-2 est le premier modèle d’image d’OpenAI intégrant le raisonnement — ce qu’ils appellent le “mode de réflexion”, documenté dans l’annonce d’introduction de ChatGPT Images 2.0. Avant de générer, le modèle peut planifier la mise en page, rechercher des références sur le web et vérifier ses propres sorties. Deuxièmement, le rendu de texte s’est suffisamment amélioré pour que les mises en page multi-scripts — celles qui cassaient tous les modèles commerciaux précédents — produisent désormais des résultats utilisables, comme confirmé dans l’entrée GPT Image sur Wikipedia couvrant la lignée du modèle.
J’ai testé les deux. Le mode raisonnement est réel. Il est aussi plus lent.
Pourquoi GPT Image 2 est important pour les équipes en production
Support d’édition, tailles flexibles et implications pour les workflows
L’API expose à la fois la génération et l’édition, ce qui signifie que vous pouvez transmettre une image de référence et une instruction en un seul appel — sans pipeline d’inpainting séparé. Le guide officiel de génération d’images couvre les options de taille, qualité, format, compression et arrière-plan.
Un détail qui m’a posé problème : les arrière-plans transparents ne sont actuellement pas pris en charge via l’option image-generation de l’outil Responses. Je l’ai découvert le deuxième jour, à mi-chemin d’un lot où j’avais supposé une parité avec le modèle précédent. La sortie est revenue avec un remplissage blanc au lieu d’un canal alpha. L’ensemble du lot était inutilisable pour l’étape de compositing en aval. Si votre pipeline dépend d’une sortie alpha, vérifiez cela par rapport à votre chemin de code réel avant de changer de modèle. J’ai perdu une heure là-dessus, plus les crédits pour le lot échoué.
Pour les équipes qui gèrent des workflows d’assets en plusieurs étapes — générer, éditer, affiner, exporter — la surface unifiée évite un vrai transfert. Pas parce que chaque étape est plus rapide, mais parce qu’il y a une intégration de moins à maintenir. Moins de composants mobiles en production signifie moins d’endroits où les choses cassent par la suite.
Questions sur la qualité, la latence et le déploiement que les équipes devraient poser
La vitesse est “moyenne”, selon la fiche du modèle d’OpenAI elle-même. En pratique, le mode de réflexion ajoute une latence notable — acceptable pour des assets marketing ponctuels, pénible pour les traitements par lot. Le mode sans réflexion se rapproche du territoire gpt-image-1.5.
La décision n’est pas “toujours utiliser le mode de réflexion parce qu’il est plus intelligent.” C’est “utiliser le mode de réflexion quand la mise en page importe, l’ignorer quand la vitesse prime.” Pour une maquette avec du texte et des contraintes spatiales, les secondes supplémentaires vous donnent un résultat utilisable dès le premier essai. Pour un lot de variations d’arrière-plan, vous voulez le chemin le plus rapide.
Je n’ai pas effectué suffisamment de lots pour donner un chiffre de latence précis. Trois jours ne suffisent pas. Ce que je peux confirmer : les requêtes en chemin froid sur le Niveau 1 sont rapidement limitées. Le plafond de 5 images par minute semble généreux jusqu’à ce que les tentatives échouées et les exécutions de tests parallèles entament le même quota. Ce n’est pas un problème de modèle. C’est un problème de niveau, et cela détermine si c’est prêt pour la production dans votre cas spécifique.
Ce que les développeurs doivent vérifier avant l’intégration
Tarification, limites de débit et fonctionnalités non prises en charge
Tarification basée sur les tokens selon la page de tarification OpenAI : l’entrée d’image est à $8 par million de tokens, l’entrée d’image en cache à $2, la sortie d’image à $30. L’entrée de texte est à $5, en cache à $1,25, la sortie de texte à $10. Le niveau batch divise ces tarifs par deux. Les estimations par image publiées dans la calculatrice se situent autour de $0,006 (basse qualité), $0,053 (moyenne) et $0,211 (haute) pour du 1024×1024.
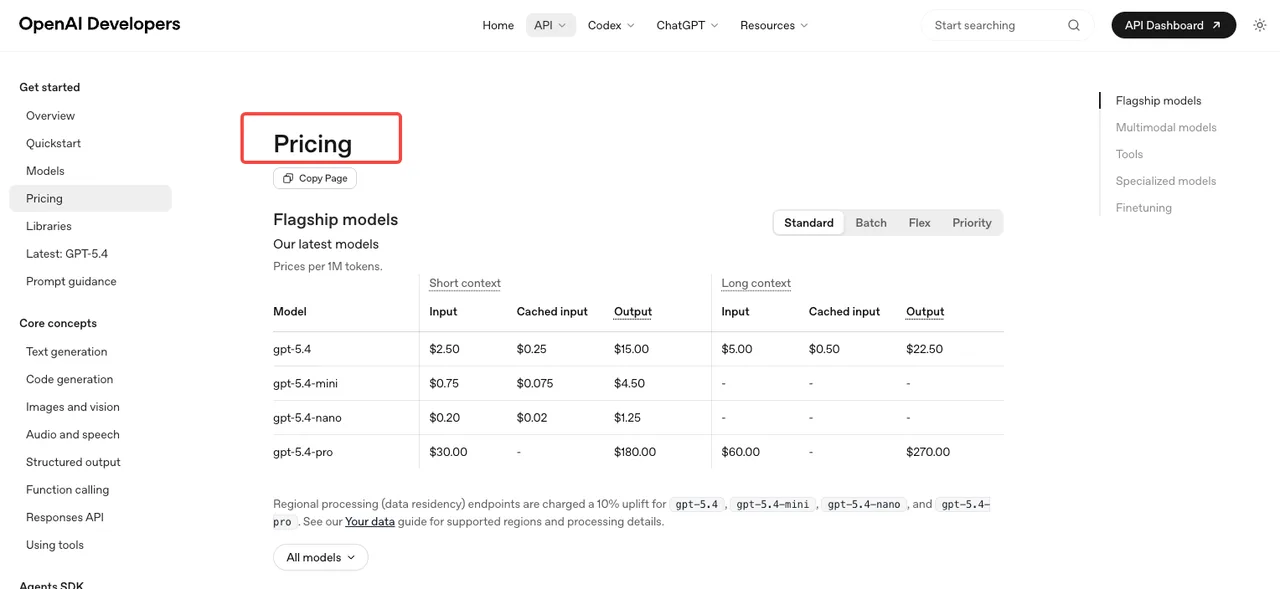
Les limites de débit sont ce qui surprend les équipes. Le Niveau 1 est plafonné à 5 images par minute. Le Niveau 2 passe à 20, le Niveau 3 à 50, le Niveau 5 à 250 — mais atteindre le Niveau 5 exige $1 000 dépensés et un compte vieux d’au moins 30 jours, comme documenté dans le guide des limites de débit OpenAI. Si votre produit s’attend à du trafic en rafale, planifiez la montée en niveau avant le lancement.
Questions opérationnelles pour l’utilisation en production
Cinq points à vérifier par rapport à votre propre workflow avant l’intégration :
- Votre pipeline a-t-il besoin d’arrière-plans transparents (actuellement non pris en charge via l’outil Responses)
- Quel est votre pic d’images par minute sous une charge réaliste
- Exécutez-vous des éditions avec des images de référence (celles-ci ajoutent des tokens d’entrée d’image — n’estimez pas uniquement à partir de la sortie)
- Votre stratégie de prompt bénéficie-t-elle du mode de raisonnement, ou le mode sans réflexion est-il suffisant
- Que se passe-t-il quand une génération échoue — réessayez-vous, basculez-vous sur un modèle de secours, ou mettez-vous en file d’attente
La référence API REST de génération d’images documente les formes de requête/réponse. Lisez-la avant d’écrire votre wrapper.
Quand GPT Image 2 est particulièrement adapté et quand il ne l’est pas
Particulièrement adapté : produits où du texte apparaît dans l’image (maquettes d’interface, infographies, menus, visuels pour les réseaux sociaux avec du texte), campagnes localisées en scripts non latins, workflows bénéficiant d’une API unique pour la génération et l’édition, et équipes déjà dans la relation de facturation OpenAI.
Moins adapté pour l’instant : pipelines de traitement par lot à haut volume sur des comptes de Niveau 1 ou Niveau 2, produits nécessitant des arrière-plans transparents via l’outil Responses, applications sensibles à la latence où la surcharge du mode de réflexion est problématique, et équipes dont le modèle existant est déjà bien calibré et où le coût de migration dépasse le gain de qualité marginal.
Ce n’est pas une situation “utilisez-le ou prenez du retard”. C’est une situation “vérifiez par rapport à vos propres contraintes”. Le modèle est bon. S’il est bon pour vous dépend des cinq questions ci-dessus.
FAQ
GPT Image 2 est-il disponible dans l’API OpenAI ?
Oui. L’identifiant du modèle est gpt-image-2, avec le snapshot gpt-image-2-2026-04-21. Il est accessible via les endpoints standard de génération d’images, d’édition d’images et Responses. Le niveau gratuit n’est pas pris en charge — vous avez besoin d’un compte payant, avec des limites de débit qui s’adaptent selon le niveau d’utilisation.
Pour quelles tâches d’image GPT Image 2 est-il le mieux adapté ?
Tout ce qui implique du texte dans l’image (menus, maquettes, infographies, visuels multilingues), les éditions guidées par référence, et les mises en page nécessitant un raisonnement spatial. Le rendu de texte est l’amélioration la plus significative en pratique. Pour une génération purement photoréaliste sans texte, le gain par rapport à gpt-image-1.5 est plus modeste.
Quelles limitations les équipes doivent-elles vérifier en premier ?
Trois concrètes : les arrière-plans transparents ne sont pas pris en charge via l’option image-generation de l’outil Responses, le Niveau 1 plafonne la génération à 5 images par minute, et le mode de raisonnement ajoute de la latence. À vérifier également — le streaming, les appels de fonctions et les sorties structurées sont listés comme non pris en charge sur la page du modèle.
Est-il prêt pour une utilisation en production à haut volume ?
Ça peut l’être, mais pas avec un compte tout neuf. Atteindre le Niveau 3 (50 images/min) nécessite $100 dépensés et un compte d’au moins 7 jours. Le Niveau 5 (250 images/min) exige $1 000 dépensés et 30 jours d’historique de compte. Si vous avez besoin d’une haute concurrence dès le premier jour, planifiez la progression de niveau ou utilisez un fournisseur avec des limites mutualisées plus élevées.
Comment la tarification se compare-t-elle à GPT Image 1.5 ?
gpt-image-2 utilise une facturation par token : entrée d’image $8/M, sortie d’image $30/M. Les estimations par image (1024×1024) se situent autour de $0,006 en basse qualité, $0,053 en moyenne, $0,211 en haute. Les éditions avec des images de référence ajoutent des tokens d’entrée d’image, donc le coût est plus élevé que les estimations basées uniquement sur la sortie ne le suggèrent. Faites passer votre charge de travail réelle dans la calculatrice avant de supposer une parité avec la version 1.5.
Conclusion
Trois jours de tests ne suffisent pas pour rendre un verdict sur la fiabilité à long terme. C’est suffisant pour dire que le modèle est réel, que l’API est stable, et que les questions d’intégration sont avant tout opérationnelles plutôt que techniques — niveaux de tarification, limites de débit, fonctionnalités manquantes dont votre workflow pourrait dépendre. Faites un petit pilote avec vos prompts réels et votre concurrence réelle avant de vous engager. C’est tout ce que je peux confirmer d’ici. Le reste, vous devrez le vérifier dans votre propre environnement.
Suite la semaine prochaine avec des chiffres de latence par lot une fois que j’aurai suffisamment de données pour y faire confiance.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir