GPT-5.5 vs GPT-5.4 pour les équipes en production
Comparez GPT-5.5 et GPT-5.4 sous l'angle de la production : disponibilité, calendrier de déploiement, préparation à la migration et où chaque modèle s'intègre aujourd'hui.

Bonjour, je suis Dora. OpenAI a lancé GPT-5.5 le 23 avril 2026. Moins de deux mois après GPT-5.4. L’API a été retardée d’un jour, puis ouverte le 24 avril avec ce qu’OpenAI a appelé « des protections différentes ». Si vous faites tourner un agent de codage sur GPT-5.4 aujourd’hui, la question n’est pas de savoir si GPT-5.5 est plus intelligent. Les benchmarks le confirment déjà. La question est de savoir si votre charge de travail API spécifique est du type qui bénéficie suffisamment pour justifier une migration cette semaine.
J’écris ceci en tant que quelqu’un qui a déjà dû prendre cette décision. Même situation, numéro de modèle différent. La réponse honnête est que cela dépend de trois choses que vous pouvez vérifier en une après-midi, et d’une chose que vous ne pouvez pas encore vérifier du tout.
Cet article explique comment faire la différence.

GPT-5.5 vs GPT-5.4 en un coup d’œil
Différences de disponibilité et de déploiement
GPT-5.5 est devenu disponible le 23 avril dans ChatGPT et Codex pour les niveaux Plus, Pro, Business et Enterprise. L’API a suivi le 24 avril. Selon le post officiel de lancement de GPT-5.5 par OpenAI, le tarif est de $5 par million de tokens en entrée et $30 par million de tokens en sortie, avec une fenêtre contextuelle de 1M. GPT-5.5 Pro est à $30/$180 par million.
GPT-5.4 reste au catalogue. Vous pouvez confirmer les deux sur la page officielle de tarification de l’API OpenAI. GPT-5.4 standard tourne à $2,50 en entrée / $15 en sortie. L’écart de prix affiché est donc 2x en surface.
OpenAI soutient que GPT-5.5 utilise moins de tokens par tâche, notamment dans les charges de travail Codex, de sorte que l’écart de coût effectif est plus étroit que ce que le tarif suggère. C’est une affirmation raisonnable. C’est aussi une affirmation que vous devez vérifier sur votre propre trafic avant d’engager un budget dessus.
Ce qui est officiellement déclaré vs ce qui est supposé
Déclaré, avec sources : tarification, parité de latence par token vs GPT-5.4, contexte 1M, le delta de protection sur le service API. Déclaré par OpenAI mais à lire attentivement : les gains en codage agentique, le score Terminal-Bench 2.0 de 82,7 %, le bond de récupération en contexte long sur MRCR v2.
Supposé et circulant : que GPT-5.5 remplacera GPT-5.4 dans la plupart des charges de production « bientôt ». OpenAI n’a pas dit cela. GPT-5.4 n’est pas en cours de dépréciation. Ne planifiez pas sur la base d’une fin de vie qui ne figure pas dans la documentation.
Je me suis arrêté en lisant la couverture TechCrunch du lancement de GPT-5.5 — le cadrage s’appuie fortement sur l’ambition de « super app », ce qui est une histoire de stratégie, pas un déclencheur de migration.
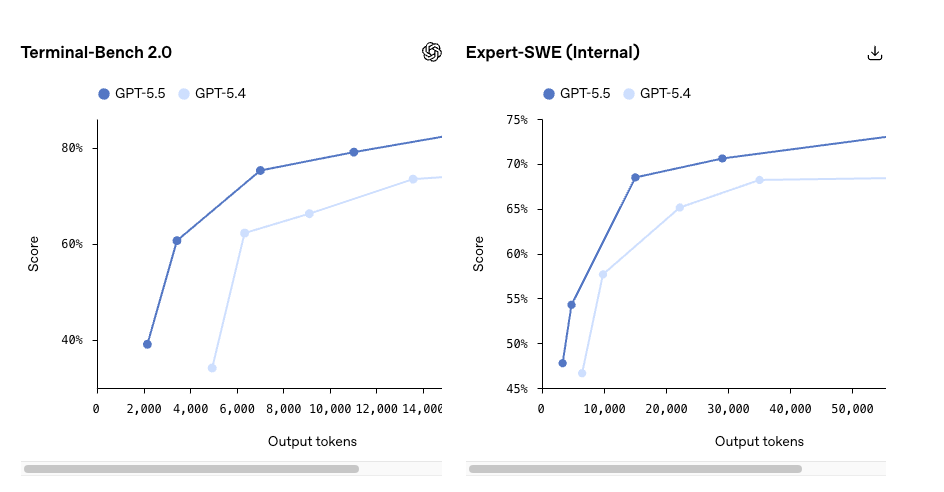
Où GPT-5.5 semble plus performant
Affirmations sur le codage agentique et l’utilisation de l’ordinateur
Les deltas de benchmark publiés par OpenAI sont de vrais chiffres, mais ce sont les propres évaluations d’OpenAI. Considérez-les comme directionnels, pas comme une vérité absolue.
- Terminal-Bench 2.0 : 82,7 % (GPT-5.5) vs 75,1 % (GPT-5.4)
- SWE-Bench Pro : 58,6 % vs la plage 55–57 % précédemment rapportée par OpenAI
- OSWorld-Verified (utilisation de l’ordinateur) : 78,7 %
- MRCR v2 récupération en contexte long (512K–1M) : 74,0 % vs 36,6 %
Ce dernier est celui auquel je prêterais vraiment attention. Un bond de 37 points en récupération de contexte long est le type de delta qui change ce qui est faisable, pas seulement ce qui est plus rapide. Si votre charge de travail dépasse régulièrement 256K tokens — bases de code entières, traces d’agents sur plusieurs heures, ensembles de documents complets — c’est là que l’histoire de la mise à niveau devient réelle.
Si votre charge de travail consiste en des complétions de chat à contexte court et des sorties structurées, rien de tout cela ne vous concerne. Mieux que prévu, mais seulement légèrement.
Efficacité et implications sur les flux de travail
OpenAI affirme que GPT-5.5 utilise environ 40 % moins de tokens de sortie pour des tâches Codex équivalentes. Si cela se confirme sur votre trafic, l’augmentation 2x du tarif affiché se comprime à quelque chose comme une augmentation effective de 20 %. C’est une différence significative dans le calcul de migration.
Cela signifie également que vous ne pouvez pas faire confiance à vos projections de coûts existantes. La comptabilité des tokens change. Faites tourner une charge de travail réelle pendant une semaine avant d’extrapoler.
Pourquoi GPT-5.4 peut encore être le meilleur choix d’API aujourd’hui
Trois raisons pour lesquelles ce n’est pas une mise à niveau simple.
Premièrement : le comportement de refus. OpenAI a livré GPT-5.5 avec une suite de protections plus robuste — ils l’appellent l’ensemble le plus solide à ce jour. Le tableau complet se trouve dans la fiche système de GPT-5.5. Pour la plupart des équipes, c’est invisible. Pour les équipes qui exécutent des charges de travail à double usage, de sécurité ou agentiques près des limites de politique, la surface de refus a changé, et elle a changé de manières que la fiche système n’énumère pas entièrement. Faites passer votre ensemble de prompts existant avant de supposer une parité de comportement.
Deuxièmement : la stabilité de l’outillage. Les schémas d’appel d’outils, le comportement des sorties structurées sous effort de raisonnement, les appels d’outils parallèles — ces surfaces ont tendance à dériver entre les générations de modèles. Le contrat que vous avez affiné sur GPT-5.4 n’est pas garanti de tenir. Vous trouverez les deltas plus rapidement en rejouant le trafic de production qu’en lisant la documentation.
Troisièmement : la prévisibilité des coûts sous charge par rafales. L’affirmation « moins de tokens » de GPT-5.5 est une moyenne de population. Les charges de travail individuelles varient. Si votre trafic a de longues queues — des agents qui s’engagent parfois dans de longues chaînes de raisonnement — vous pouvez faire face à des pics de coûts qui n’apparaissent pas dans la moyenne. GPT-5.4 a une forme de coût prévisible que votre équipe financière a déjà acceptée.
Rien de tout cela ne signifie rester indéfiniment. Cela signifie ne pas migrer sur l’annonce.

Un cadre décisionnel pratique pour les équipes
Quatre questions, dans cet ordre :
- Votre charge de travail est-elle limitée par le contexte long ? Si vous exécutez régulièrement des prompts de plus de 200K tokens et que la qualité de récupération est votre plafond, GPT-5.5 vaut probablement un test sérieux maintenant. Le delta MRCR v2 n’est pas le genre de chiffre qu’on ignore.
- Votre charge de travail est-elle agentique / multi-étapes / de type Codex ? Un A/B parallèle en vaut la peine. Pas une migration complète avant d’avoir mesuré la consommation de tokens sur vos tâches réelles. La réduction de 40 % est plausible. C’est aussi une affirmation qui nécessite vos données, pas celles d’OpenAI.
- Votre charge de travail est-elle du chat à contexte court ou de la génération en une seule passe ? Restez sur GPT-5.4. L’augmentation de prix est réelle et le delta de capacité sur ces tâches est faible. Hypothèse confirmée en lisant les catégories de benchmark — les gains se concentrent dans les évaluations à long horizon et d’utilisation de l’ordinateur, pas dans les tours courts.
- Avez-vous un incident de production en cours ou un problème de capacité ? Ne migrez pas en pleine urgence. Nouveau modèle + nouvelles protections + nouvelle comptabilité des tokens, c’est trois changements à la fois. Faites la comparaison sur une branche parallèle.
Choses à vérifier avant tout changement, quelle que soit la catégorie : comportement de refus sur votre corpus de prompts, parité de schéma d’appel d’outils (vérifiez la page du modèle GPT-5.5 dans la documentation API d’OpenAI), latence de bout en bout sur votre couche de routage, et une projection de coût sur une semaine sur du trafic réel. Pas synthétique. Du trafic réel.

FAQ
Les équipes devraient-elles passer à GPT-5.5 maintenant ?
Pas par défaut. Passez si vous êtes limité par le contexte long ou si vous exécutez une pile d’agents multi-étapes. Sinon, faites un test parallèle pendant deux semaines, comparez sur vos métriques, puis décidez. Le réflexe « plus récent est meilleur » a coûté plus d’argent à plus d’équipes que je ne veux le compter.
GPT-5.5 est-il utilisable en production aujourd’hui ?
Oui. L’API est en ligne depuis le 24 avril 2026, avec une tarification et des limites de débit documentées. « Utilisable » et « approprié pour votre charge de travail » sont des questions différentes. La première est réglée. La seconde vous appartient.
Que devraient tester les équipes avant de migrer ?
Le comportement de refus sur votre ensemble de prompts. La consommation de tokens sur des tâches représentatives (pas synthétiques). La parité de schéma d’appel d’outils et de sortie structurée. La latence à votre concurrence réelle. Le coût sur une semaine complète de trafic normal. Si l’un de ces éléments pose problème, restez où vous êtes jusqu’à ce que ce ne soit plus le cas.
Quand vaut-il mieux rester sur GPT-5.4 ?
Charges de travail à contexte court. Systèmes de production stables et bien réglés. Charges de travail sensibles aux coûts où l’augmentation 2x du tarif affiché n’est pas compensée par l’efficacité des tokens sur votre trafic spécifique. Équipes en milieu de cycle de release. Équipes sans bande passante pour revalider le comportement de refus. GPT-5.4 n’est pas en cours de dépréciation. Rester est un choix valide, pas une migration différée.
Conclusion
La réponse à GPT-5.5 vs GPT-5.4 pour les équipes en production n’est pas une réponse unique. C’est une question de charge de travail déguisée en question de modèle. Les charges de travail à contexte long et agentiques ont une vraie raison de tester maintenant. Les charges de travail à contexte court ont une vraie raison d’attendre. Tous ceux qui se trouvent au milieu ont une raison de faire la comparaison parallèle et de laisser les données décider.
C’est là que mes données s’arrêtent. Les benchmarks que je cite sont principalement ceux d’OpenAI. L’affirmation d’efficacité des tokens est plausible mais non vérifiée en dehors de leurs évaluations. Le delta de protection se manifestera en production de manières que la fiche système ne prédit pas.
Faites-le vous-même sur votre trafic pendant une semaine. Cela vous apprendra plus que tout ce que je peux dire.
Plus d’informations à venir une fois que le comportement post-lancement se stabilise.
Articles précédents :
- GPT-5.5 for Builders: API Capabilities, Pricing, and When to Upgrade
- GPT-5 Model Versions Explained: Differences, Use Cases, and Migration Paths
- GPT-5.4 vs GPT-5.3: What Changed for Developers and API Workloads
- Agentic Workflow Patterns: Tool Wiring, Pitfalls, and Real-World Tradeoffs
- DeepSeek V4 Pro vs Flash: Cost, Speed, and Performance Trade-offs
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
