GPT Image 2 en 2026: ¿Vale la pena integrarlo?
Una guía orientada a desarrolladores sobre GPT Image 2 que cubre el acceso a la API, precios, límites de velocidad, soporte de edición y si está listo para flujos de trabajo en producción.

Aquí está Dora. Pasé el fin de semana después del lanzamiento integrando gpt-image-2 en un flujo de trabajo que ya tenía funcionando con el modelo anterior. Las mismas instrucciones, las mismas imágenes de referencia, los mismos tamaños de lote. El objetivo no era quedar impresionada, sino descubrir qué cambia realmente cuando intercambias el ID del modelo. Soy Dora, y esto es lo que hago antes de recomendar algo al equipo.
Después de tres días, tengo suficiente para escribirlo. No suficiente para dar un veredicto, pero sí para señalar lo que los desarrolladores deberían verificar antes de integrar.
Este artículo es para personas que ya envían imágenes a través de una API. Si estás evaluando si agregar gpt-image-2 a un flujo de trabajo en producción —junto con lo que estés usando actualmente— esto es lo que me gustaría que alguien me dijera. El modelo es real, la API está activa, y los límites de tasa te sorprenderán si no lees la documentación primero.
Qué es GPT Image 2 y Qué Lanzó OpenAI Oficialmente
IDs de modelo confirmados, endpoints y momento del lanzamiento
OpenAI lanzó gpt-image-2 el 21 de abril de 2026, junto con el rebrand orientado al consumidor “ChatGPT Images 2.0”. El ID del modelo es gpt-image-2, con el snapshot actual fijado como gpt-image-2-2026-04-21 según la página oficial del modelo GPT Image 2. Funciona a través de v1/images/generations, v1/images/edits, v1/responses y v1/chat/completions.
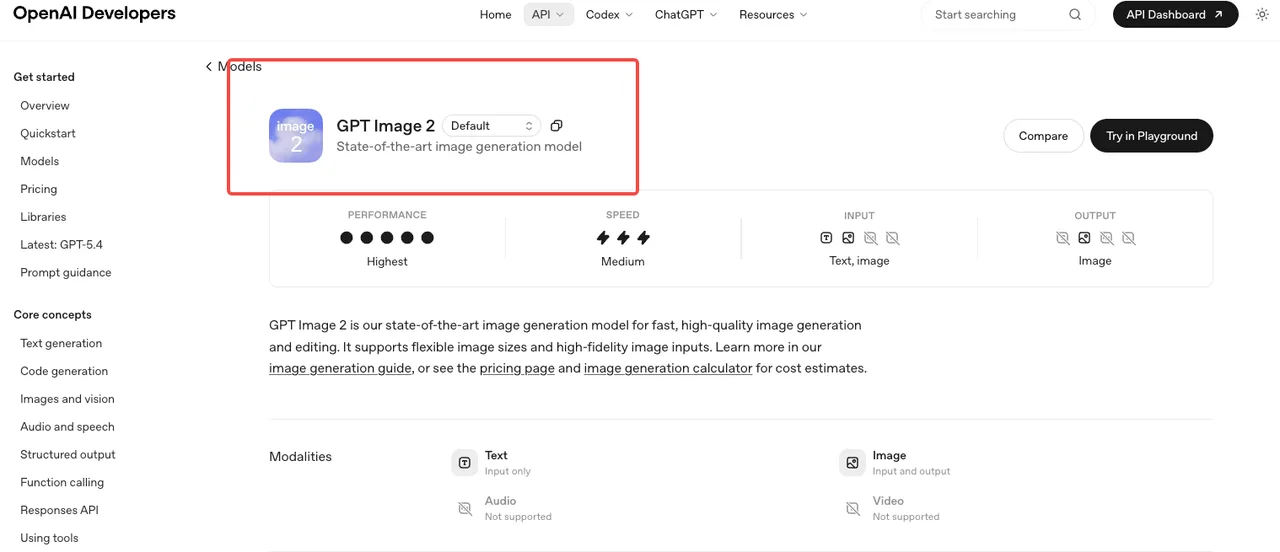 Esa es la superficie verificada. Cualquier cosa que reclame acceso anticipado a la API era tráfico de pruebas A/B dentro de ChatGPT o especulación. Usa el ID de snapshot en el código de producción — el alias avanzará cuando OpenAI publique una nueva versión, y ese no es un comportamiento que quieras que cambie a mitad de un lote.
Esa es la superficie verificada. Cualquier cosa que reclame acceso anticipado a la API era tráfico de pruebas A/B dentro de ChatGPT o especulación. Usa el ID de snapshot en el código de producción — el alias avanzará cuando OpenAI publique una nueva versión, y ese no es un comportamiento que quieras que cambie a mitad de un lote.
Qué cambió respecto a los modelos GPT Image anteriores
Dos cosas importan para los desarrolladores. Primero, gpt-image-2 es el primer modelo de imágenes de OpenAI con razonamiento integrado — lo que llaman “modo de pensamiento”, documentado en el anuncio de introducción a ChatGPT Images 2.0. Antes de generar, el modelo puede planificar el diseño, buscar referencias en la web y verificar los resultados por sí mismo. Segundo, la representación de texto mejoró lo suficiente como para que los diseños con múltiples scripts —el tipo que rompía todos los modelos comerciales anteriores— ahora produzcan resultados utilizables, según lo confirmado en la entrada de GPT Image en Wikipedia que cubre el linaje del modelo.
Probé ambos. El modo de razonamiento es real. También es más lento.
Por Qué GPT Image 2 Importa para los Equipos en Producción
Soporte de edición, tamaños flexibles e implicaciones para el flujo de trabajo
La API expone tanto generación como ediciones, lo que significa que puedes pasar una imagen de referencia y una instrucción en una sola llamada — sin necesidad de un pipeline de inpainting separado. La guía oficial de generación de imágenes cubre las opciones de tamaño, calidad, formato, compresión y fondo.
Un detalle que me causó problemas: actualmente los fondos transparentes no son compatibles con la opción de herramienta de generación de imágenes en Responses. Lo noté el segundo día, a mitad de un lote donde había asumido paridad con el modelo anterior. La salida regresó con un relleno blanco en lugar de canal alfa. Todo el lote era inutilizable para el paso de composición posterior. Si tu pipeline depende de la salida alfa, verifica esto contra tu ruta de código real antes de cambiar de modelo. Perdí una hora con esto, además de los créditos del lote fallido.
Para equipos que ejecutan flujos de trabajo de activos en múltiples pasos —generar, editar, refinar, exportar— la superficie unificada ahorra una transferencia real. No porque cada paso sea más rápido, sino porque hay una integración menos que mantener. Menos partes móviles en producción significa menos lugares donde las cosas se rompen después.
Preguntas sobre calidad, latencia y despliegue que los equipos deben hacerse
La velocidad es “media”, según la propia tarjeta del modelo de OpenAI. En la práctica, el modo de pensamiento añade latencia notable — está bien para activos de marketing individuales, pero es doloroso para trabajos en lote. El modo sin pensamiento se acerca más al territorio de gpt-image-1.5.
La decisión no es “usar siempre el modo de pensamiento porque es más inteligente”. Es “usar el modo de pensamiento cuando importa el diseño, omitirlo cuando importa la velocidad”. Para un mockup con texto y restricciones espaciales, los segundos extra te dan un resultado utilizable en el primer intento. Para un lote de variaciones de fondo, quieres la ruta más rápida.
No he ejecutado suficientes lotes para dar un número de latencia limpio. Tres días no son suficientes. Lo que puedo confirmar: las solicitudes de ruta fría en el Nivel 1 se limitan rápidamente. El límite de 5 imágenes por minuto suena generoso hasta que los reintentos fallidos y las ejecuciones de prueba en paralelo consumen la misma cuota. Ese no es un problema del modelo. Es un problema de nivel, y determina si esto está listo para producción específicamente para ti.
Lo Que los Desarrolladores Necesitan Verificar Antes de la Integración
Precios, límites de tasa y funciones no compatibles
Precios basados en tokens según la página de precios de OpenAI: la entrada de imagen cuesta $8 por millón de tokens, la entrada de imagen en caché $2, la salida de imagen $30. La entrada de texto es $5, en caché $1.25, la salida de texto $10. El nivel de lote reduce estos precios a la mitad. Las estimaciones por imagen publicadas en la calculadora rondan los $0.006 (baja calidad), $0.053 (media) y $0.211 (alta) para 1024×1024.
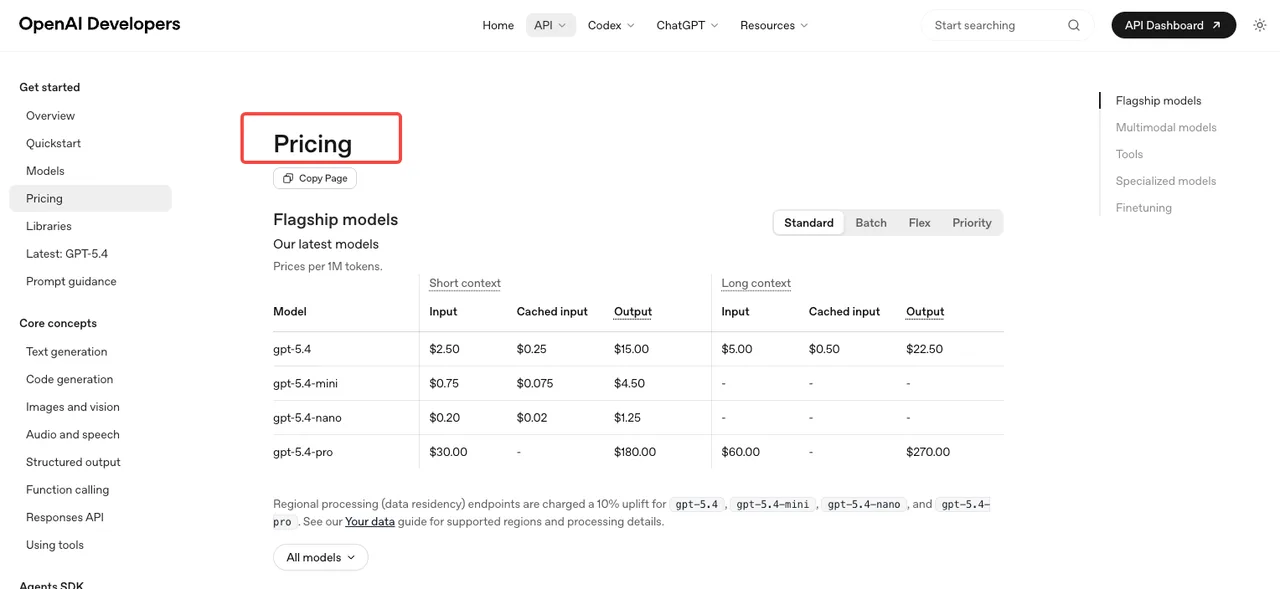
Los límites de tasa son donde los equipos se quedan atrapados. El Nivel 1 tiene un límite de 5 imágenes por minuto. El Nivel 2 sube a 20, el Nivel 3 a 50, el Nivel 5 a 250 — pero alcanzar el Nivel 5 requiere $1,000 gastados y una cuenta con al menos 30 días de antigüedad, según se documenta en la guía de límites de tasa de OpenAI. Si tu producto espera tráfico en ráfagas, planifica la progresión de nivel antes de lanzar.
Preguntas operativas para el uso en producción
Cinco cosas que verificaría contra tu propio flujo de trabajo antes de la integración:
- ¿Tu pipeline necesita fondos transparentes (actualmente no compatible a través de la herramienta Responses)?
- ¿Cuál es tu pico de imágenes por minuto bajo carga realista?
- ¿Estás ejecutando ediciones con imágenes de referencia (estas añaden tokens de entrada de imagen — no estimes solo desde la salida)?
- ¿Tu estrategia de instrucciones se beneficia del modo de razonamiento, o es suficiente sin pensamiento?
- ¿Qué ocurre cuando falla una generación — reintentes, usas un fallback o pones en cola?
La referencia de la API REST de generación de imágenes documenta las formas de solicitud/respuesta. Léela antes de escribir tu wrapper.
Cuándo GPT Image 2 Es una Buena Opción y Cuándo No
Buena opción: productos donde el texto aparece dentro de la imagen (mockups de UI, infografías, menús, gráficos para redes sociales con texto), campañas localizadas en scripts no latinos, flujos de trabajo que se benefician de una sola API para generación y edición, y equipos que ya están dentro de la relación de facturación con OpenAI.
Opción más débil por ahora: pipelines de lotes de alto volumen en cuentas de Nivel 1 o Nivel 2, productos que requieren fondos transparentes a través de la herramienta Responses, aplicaciones sensibles a la latencia donde el overhead del modo de pensamiento importa, y equipos cuyo modelo existente ya está bien ajustado y donde el costo de cambio supera la ganancia marginal de calidad.
Esta no es una situación de “úsalo o te quedarás atrás”. Es una situación de “verifica contra tus propias restricciones”. El modelo es bueno. Si es bueno para ti depende de las cinco preguntas anteriores.
Preguntas Frecuentes
¿Está disponible GPT Image 2 en la API de OpenAI?
Sí. El ID del modelo es gpt-image-2, con snapshot gpt-image-2-2026-04-21. Es accesible a través de los endpoints estándar de generación de imágenes, edición de imágenes y Responses. El nivel gratuito no está soportado — necesitas una cuenta de pago, con límites de tasa que escalan según el nivel de uso.
¿Para qué tareas de imágenes es mejor GPT Image 2?
Todo lo que involucra texto dentro de la imagen (menús, mockups, infografías, gráficos multilingües), ediciones basadas en referencias, y diseños que requieren razonamiento espacial. La representación de texto es la mejora más significativa en términos prácticos. Para la generación puramente fotorrealista sin texto, la ganancia sobre gpt-image-1.5 es menor.
¿Qué limitaciones deben verificar primero los equipos?
Tres concretas: los fondos transparentes no son compatibles a través de la opción de herramienta de generación de imágenes en Responses, el Nivel 1 limita la generación a 5 imágenes por minuto, y el modo de razonamiento añade latencia. También vale la pena verificar — el streaming, la llamada a funciones y las salidas estructuradas aparecen listados como no soportados en la página del modelo.
¿Está listo para uso en producción de alto volumen?
Puede estarlo, pero no con una cuenta recién creada. Alcanzar el Nivel 3 (50 imágenes/min) requiere $100 gastados y una cuenta con al menos 7 días de antigüedad. El Nivel 5 (250 imágenes/min) necesita $1,000 gastados y un historial de cuenta de 30 días. Si necesitas alta concurrencia desde el primer día, planifica la progresión de nivel o usa un proveedor con límites agrupados más altos.
¿Cómo se comparan los precios con GPT Image 1.5?
gpt-image-2 usa facturación por token: entrada de imagen $8/M, salida de imagen $30/M. Las estimaciones por imagen (1024×1024) rondan los $0.006 de baja calidad, $0.053 media, $0.211 alta. Las ediciones con imágenes de referencia añaden tokens de entrada de imagen, por lo que el costo es mayor de lo que sugieren las estimaciones solo de salida. Ejecuta tu carga de trabajo real en la calculadora antes de asumir paridad con la versión 1.5.
Conclusión
Tres días de pruebas no son suficientes para dar un veredicto sobre la fiabilidad a largo plazo. Sí es suficiente para decir que el modelo es real, la API es estable, y las preguntas de integración son principalmente operativas en lugar de técnicas — niveles de precios, límites de tasa, funciones faltantes de las que puede depender tu flujo de trabajo. Ejecuta un pequeño piloto contra tus instrucciones reales y tu concurrencia real antes de comprometerte. Eso es todo lo que puedo confirmar desde aquí. El resto tendrás que verificarlo en tu propio entorno.
Continúo la próxima semana con números de latencia de lotes una vez que tenga suficientes datos para confiar en ellos.
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber