GPT-5.5 vs GPT-5.4 para Equipos en Producción
Compara GPT-5.5 vs GPT-5.4 desde una perspectiva de producción: disponibilidad, tiempos de implementación, preparación para migración y dónde encaja cada modelo hoy.

Hola, soy Dora. OpenAI lanzó GPT-5.5 el 23 de abril de 2026. Menos de dos meses después de GPT-5.4. La API se retrasó un día, luego se abrió el 24 de abril con lo que OpenAI llamó “salvaguardas diferentes”. Si hoy estás ejecutando un agente de codificación en GPT-5.4, la pregunta no es si GPT-5.5 es más inteligente. Los benchmarks ya dicen que sí. La pregunta es si tu carga de trabajo específica en la API es del tipo que se beneficia lo suficiente como para justificar una migración esta semana.
Escribo esto como alguien que ha tenido que tomar esta decisión antes. Misma situación, número de modelo diferente. La respuesta honesta es que depende de tres cosas que puedes verificar en una tarde, y una cosa que todavía no puedes verificar en absoluto.
Este artículo trata sobre cómo distinguir la diferencia.

GPT-5.5 vs GPT-5.4 de un vistazo
Diferencias de disponibilidad y despliegue
GPT-5.5 entró en funcionamiento el 23 de abril en ChatGPT y Codex para los niveles Plus, Pro, Business y Enterprise. La API siguió el 24 de abril. Según la publicación oficial de lanzamiento de GPT-5.5 de OpenAI, el precio es $5 por 1M tokens de entrada y $30 por 1M tokens de salida, con una ventana de contexto de 1M. GPT-5.5 Pro se sitúa en $30/$180 por 1M.
GPT-5.4 permanece en la tarifa. Puedes confirmar ambos en la página oficial de precios de la API de OpenAI. El estándar GPT-5.4 corre a $2.50 de entrada / $15 de salida. Así que la diferencia de precio nominal es 2x en la superficie.
La postura de OpenAI es que GPT-5.5 utiliza menos tokens por tarea, especialmente en cargas de trabajo de Codex, por lo que la brecha de coste efectivo es más estrecha de lo que sugiere la tarifa. Es una afirmación razonable. También es una afirmación que tienes que verificar en tu propio tráfico antes de apostar un presupuesto por ello.
Lo que se declara oficialmente vs lo que se infiere
Declarado, con fuentes: precios, paridad de latencia por token respecto a GPT-5.4, contexto de 1M, el delta de salvaguardas en el servicio de API. Declarado por OpenAI pero que vale la pena leer con atención: las ganancias en codificación agéntica, la puntuación en Terminal-Bench 2.0 del 82,7%, el salto en recuperación de contexto largo en MRCR v2.
Inferido y circulando: que GPT-5.5 reemplazará a GPT-5.4 en la mayoría de las cargas de trabajo de producción “pronto”. OpenAI no ha dicho eso. GPT-5.4 no está siendo deprecado. No planifiques en función de una discontinuación que no está en la documentación.
Hice una pausa cuando leí la cobertura de TechCrunch sobre el lanzamiento de GPT-5.5 — el enfoque se inclina fuertemente hacia la ambición de “super app”, que es una historia de estrategia, no un desencadenante de migración.
Dónde GPT-5.5 parece más fuerte
Afirmaciones sobre codificación agéntica y uso de computadora
Los deltas de benchmark que OpenAI publicó son números reales, pero son las evaluaciones propias de OpenAI. Tómalos como indicativos, no como verdad absoluta.
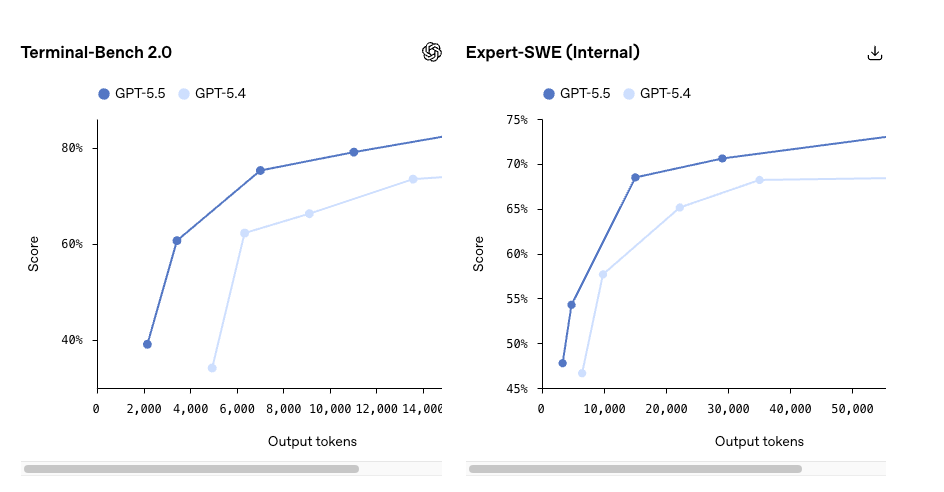
- Terminal-Bench 2.0: 82,7% (GPT-5.5) vs 75,1% (GPT-5.4)
- SWE-Bench Pro: 58,6% vs el rango previamente reportado por OpenAI de 55–57%
- OSWorld-Verified (uso de computadora): 78,7%
- Recuperación de contexto largo MRCR v2 (512K–1M): 74,0% vs 36,6%
Este último es el que yo realmente prestaría atención. Un salto de 37 puntos en recuperación de contexto largo es el tipo de delta que cambia lo que es factible, no solo lo que es más rápido. Si tu carga de trabajo supera rutinariamente los 256K tokens — bases de código completas, trazas de agentes de varias horas, conjuntos completos de documentos — aquí es donde la historia de actualización se vuelve real.
Si tu carga de trabajo son completaciones de chat de contexto corto y salidas estructuradas, nada de eso aplica para ti. Mejor de lo esperado, pero solo ligeramente.
Implicaciones de eficiencia y flujo de trabajo
La afirmación de OpenAI es que GPT-5.5 usa aproximadamente un 40% menos de tokens de salida para tareas equivalentes en Codex. Si eso se mantiene en tu tráfico, el aumento 2x en la tarifa se comprime a algo así como un aumento efectivo del 20%. Esa es una diferencia significativa en el cálculo de migración.
También significa que no puedes confiar en tus proyecciones de costes existentes. La contabilidad de tokens cambia. Ejecuta una carga de trabajo real durante una semana antes de extrapolar.
Por qué GPT-5.4 podría seguir siendo la mejor opción de API hoy
Tres razones por las que esto no es una actualización limpia.
Una: comportamiento de rechazo. OpenAI lanzó GPT-5.5 con un conjunto de salvaguardas más fuerte — lo llaman el conjunto más sólido hasta la fecha. El panorama completo está en la tarjeta de sistema de GPT-5.5. Para la mayoría de los equipos esto es invisible. Para los equipos que ejecutan cargas de trabajo de doble uso, seguridad o agénticas cerca de los límites de política, la superficie de rechazo ha cambiado, y cambió de maneras que la tarjeta de sistema no enumera completamente. Ejecuta tu conjunto de prompts existente a través de ella antes de asumir paridad de comportamiento.
Dos: estabilidad del tooling. Los esquemas de llamadas a herramientas, el comportamiento de salida estructurada bajo esfuerzo de razonamiento, las llamadas paralelas a herramientas — estas superficies tienden a derivar entre generaciones de modelos. El contrato que has ajustado con GPT-5.4 no está garantizado que se mantenga. Encontrarás los deltas más rápido reproduciendo el tráfico de producción que leyendo documentación.
Tres: previsibilidad de costes bajo carga con ráfagas. La afirmación de “menos tokens” de GPT-5.5 es un promedio poblacional. Las cargas de trabajo individuales varían. Si tu tráfico tiene colas largas — agentes que ocasionalmente se extienden en largas cadenas de razonamiento — puedes tener picos de coste que no aparecen en el promedio. GPT-5.4 tiene una forma de coste predecible que tu equipo de finanzas ya ha aceptado.
Nada de esto significa quedarse para siempre. Significa no migrar con el anuncio.

Un marco de decisión práctico para equipos
Cuatro preguntas, en este orden:
- ¿Tu carga de trabajo está limitada por el contexto largo? Si regularmente ejecutas prompts de más de 200K tokens y la calidad de recuperación es tu techo, GPT-5.5 probablemente vale la pena probarlo seriamente ahora. El delta de MRCR v2 no es el tipo de número que puedes ignorar.
- ¿Tu carga de trabajo es agéntica / multi-paso / estilo Codex? Vale la pena un A/B paralelo. No vale la pena una migración completa hasta que hayas medido el consumo de tokens en tus tareas reales. La reducción del 40% es plausible. También es una afirmación que necesita tus datos, no los de OpenAI.
- ¿Tu carga de trabajo es chat de contexto corto o generación de un solo disparo? Quédate en GPT-5.4. El aumento de precio es real y el delta de capacidad en estas tareas es pequeño. Hipótesis confirmada al leer las categorías de benchmark — las ganancias se concentran en evaluaciones de horizonte largo y uso de computadora, no en turnos cortos.
- ¿Tienes un incidente de producción actual o un problema de capacidad? No migres durante un incendio. Nuevo modelo + nuevas salvaguardas + nueva contabilidad de tokens son tres cambios a la vez. Ejecuta la comparación en una rama paralela.
Cosas a verificar antes de cualquier cambio, independientemente de la categoría: comportamiento de rechazo en tu corpus de prompts, paridad de esquema de llamadas a herramientas (consulta la página del modelo GPT-5.5 en los docs de la API de OpenAI), latencia de extremo a extremo en tu capa de enrutamiento, y una proyección de costes de una semana con tráfico real. No sintético. Tráfico real.

Preguntas frecuentes
¿Deberían los equipos cambiar de GPT-5.4 ahora?
No por defecto. Cambia si estás limitado por el contexto largo o ejecutas una pila de agentes multi-paso. De lo contrario, ejecuta una prueba paralela durante dos semanas, compara con tus métricas, luego decide. El reflejo de “lo más nuevo es mejor” ha costado más dinero a más equipos del que quiero contar.
¿Es GPT-5.5 utilizable en producción hoy?
Sí. La API ha estado activa desde el 24 de abril de 2026, con precios y límites de velocidad documentados. “Utilizable” y “apropiado para tu carga de trabajo” son preguntas diferentes. La primera está resuelta. La segunda es tuya para responder.
¿Qué deberían probar los equipos antes de migrar?
Comportamiento de rechazo en tu conjunto de prompts. Consumo de tokens en tareas representativas (no sintéticas). Paridad de esquema de llamadas a herramientas y salida estructurada. Latencia en tu concurrencia real. Coste durante una semana completa de tráfico normal. Si alguno de estos falla, quédate donde estás hasta que no lo hagan.
¿Cuándo es quedarse en GPT-5.4 la mejor decisión?
Cargas de trabajo de contexto corto. Sistemas de producción estables y bien ajustados. Cargas de trabajo sensibles al coste donde el aumento 2x en la tarifa no se compensa con la eficiencia de tokens en tu tráfico específico. Equipos en medio de un ciclo de lanzamiento. Equipos sin ancho de banda para revalidar el comportamiento de rechazo. GPT-5.4 no está siendo deprecado. Quedarse es una decisión válida, no una migración retrasada.
Conclusión
La respuesta a GPT-5.5 vs GPT-5.4 para equipos de producción no es una respuesta única. Es una pregunta de carga de trabajo disfrazada de pregunta de modelo. Las cargas de trabajo de contexto largo y agénticas tienen una razón real para probar ahora. Las cargas de trabajo de contexto corto tienen una razón real para esperar. Todos los que están en el medio tienen una razón para ejecutar la comparación paralela y dejar que los datos decidan.
Ahí es donde terminan mis datos. Los benchmarks que cito son en su mayoría los propios de OpenAI. La afirmación de eficiencia de tokens es plausible pero no verificada fuera de sus evaluaciones. El delta de salvaguardas surgirá en producción de maneras que la tarjeta de sistema no predice.
Ejecútalo tú mismo en tu tráfico durante una semana. Eso te dirá más que cualquier cosa que yo diga.
Más información una vez que el comportamiento posterior al lanzamiento se estabilice.
Publicaciones anteriores:
- GPT-5.5 para constructores: capacidades de API, precios y cuándo actualizar
- Versiones del modelo GPT-5 explicadas: diferencias, casos de uso y rutas de migración
- GPT-5.4 vs GPT-5.3: qué cambió para desarrolladores y cargas de trabajo de API
- Patrones de flujo de trabajo agéntico: conexión de herramientas, trampas y compromisos del mundo real
- DeepSeek V4 Pro vs Flash: compromisos de coste, velocidad y rendimiento
Artículos relacionados

Claude Fable 5 ya está disponible: 80,3% en SWE-Bench Pro, precios 2× Opus 4.8, gratis hasta el 22 de junio

Cómo elegir una API de medios de IA para aplicaciones Codex (2026)

API de Hunyuan 3D: Lo que los desarrolladores deben saber

Hunyuan 3D vs Hyper3D vs Pixal3D

Construyendo Aplicaciones de Video con IA Usando Agentes de Codificación
