DeepSeek V4 Pro vs Flash: Welche Version für den Produktiveinsatz?
Vergleich von DeepSeek V4 Pro und V4 Flash für den Produktiveinsatz: Leistungsabwägungen, Latenz, Kosten und welche Version zu Ihrem Workload passt.

DeepSeek hat V4 als zwei Modelle veröffentlicht, nicht als eines: V4-Pro mit 1,6 Billionen Gesamtparametern und 49 Milliarden aktivierten, und V4-Flash mit 284 Milliarden Gesamtparametern und 13 Milliarden aktivierten. Beide teilen sich ein Kontextfenster von 1 Million Token. Beide sind Open Weights unter MIT. Beide werden über dieselbe API-Oberfläche bereitgestellt.
Das ist wichtig, weil die Entscheidung nicht mehr „DeepSeek nutzen oder nicht” lautet. Es geht darum, welches der beiden Modelle hinter welchem Endpunkt eingesetzt wird. Und die richtige Antwort lautet selten „einfach überall Pro verwenden.”
Dies ist ein Auswahleitfaden für KI-Produktteams und Engineering Leads, die Workloads korrekt routen möchten. Wer meinen früheren Artikel über DeepSeek V4-Features für API-Entwickler gelesen hat: Das war die Ära des Einzelmodells. Das hier ist die gestufte Version.
Alle nachfolgenden Zahlen entsprechen dem Stand zum Veröffentlichungsdatum. Alles, was ich nicht gegen offizielle Dokumentation verifizieren kann, ist explizit gekennzeichnet.
DeepSeek V4 Pro vs. Flash auf einen Blick
Positionierung der einzelnen Versionen (gemäß offiziellem Preview)
Gemäß DeepSeeks eigenem V4-Pro-Modellblatt auf Hugging Face ist die Aufteilung beabsichtigt – es sind nicht dasselbe Modell in unterschiedlichen Größen. Flash wird separat trainiert, nicht aus Pro destilliert.
DeepSeeks eigene Beschreibung:
- V4-Pro – reichhaltiges Weltwissen, das offene Modelle übertrifft, erstklassiges Reasoning in Mathematik/MINT/Coding, stärkstes Modell für agentische Aufgaben.
- V4-Flash – Reasoning „nähert sich deutlich” Pro an, vergleichbare Leistung zu Pro bei einfachen Agenten-Aufgaben, schwächer bei komplexen. Günstiger zu betreiben, schnellere Antworten.
Die Unterscheidung „einfach vs. komplex” ist die eigentliche Entscheidungsgrundlage. DeepSeek sagt direkt, wo Flash nachlässt. Das sollte man nicht ignorieren.
Gemeinsame Features (1M Kontext, Thinking-Modus, API-Kompatibilität)
Features, die bei beiden identisch sind:
- 1-Million-Token-Kontextfenster bei beiden Varianten, ermöglicht durch DeepSeeks hybride Attention-Architektur (CSA + HCA). Laut der Hugging-Face-Karte benötigt Pro nur 27 % der FLOPs pro Token und 10 % des KV-Cache im Vergleich zu V3.2 bei 1M Kontext.
- Drei Reasoning-Effort-Modi – Non-Thinking, Thinking (High) und Think Max. Gleicher API-Flag, gleiches Verhalten.
- OpenAI-kompatible Chat-Completions-API und Anthropic-Protokoll-Unterstützung. Gleiche
base_url, nur die Modell-ID austauschen. - MIT-Lizenz für die Gewichte beider Modelle, gemäß den offiziellen Repositories.
Bei einer Migration zwischen den beiden bleibt die Integrationsoberfläche identisch. Nur die Modell-ID und die Rechnung ändern sich.
Fähigkeitsunterschiede
Die Divergenz zeigt sich bei bestimmten Eval-Kategorien – und das Muster ist konsistent genug, um daraus eine Routing-Regel abzuleiten.
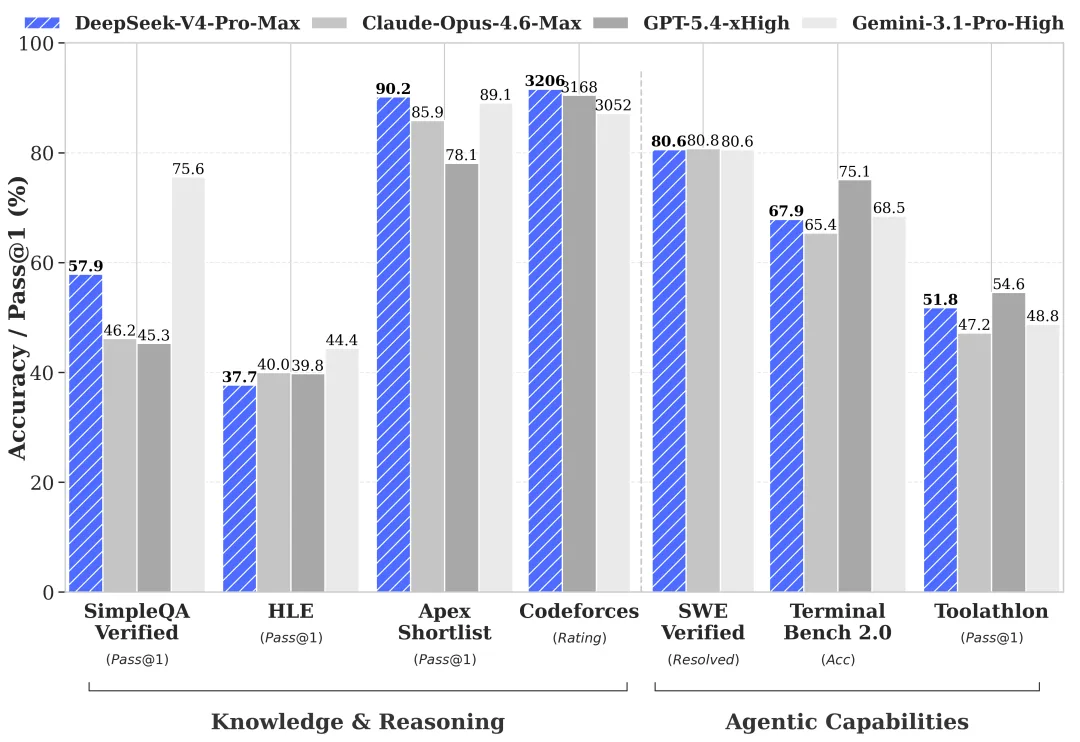
Weltwissen: Pro führt, Flash liegt dahinter (gemäß offiziellen Benchmarks – Verifikation erforderlich)
DeepSeeks eigene Preview-Benchmarks, zusammengefasst aus ihrer HF-Karte und dem technischen Bericht, zeigen: Der Pro/Flash-Abstand ist bei den meisten Eval-Kategorien gering – aber an einigen Stellen deutlich ausgeprägt:
| Benchmark | V4-Pro | V4-Flash | Abstand |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Zahlen von DeepSeek gemeldet. Keine Drittanbieter-Replikation existiert zum jetzigen Zeitpunkt – Verifikation erforderlich vor Produktionsübernahme. Das Muster des Abstands ist das Signal, nicht die genauen Ziffern.
SimpleQA-Verified testet faktisches Abrufen. Terminal Bench 2.0 ist mehrstufige Tool-Nutzung. Flash fällt bei beiden spürbar zurück. Das stimmt mit dem überein, was DeepSeek in klarer Sprache gesagt hat: einfache Aufgaben gut, komplexe Agenten-Workloads schwächer.
Reasoning-Parität bei einfachen Aufgaben
Bei Coding, Mathematik und begrenztem Reasoning schließt sich der Abstand auf 1–3 Punkte. LiveCodeBench und MMLU-Pro zeigen Flash in Reichweite von Pro. Für die meisten Inference-Aufrufe in einem typischen Produkt – Chat-Turn, One-Shot-Generierung, Code-Vervollständigung, Zusammenfassung – ist Flash in keiner Weise ein Rückschritt, den Nutzer bemerken würden.
Das ist der Kern des Flash-Wertversprechens: Es ist kein abgespecktes Pro. Es ist ein separat trainiertes Modell, das zufällig nah an Pro in der Mitte der Benchmark-Verteilung landet.
Agenten-Aufgaben: Divergenz bei hochkomplexen Workloads
Die Kategorie mit langem Horizont, mehreren Tools und mehreren Hops ist der Trennpunkt. Terminal Bench 2.0 und Toolathlon sind die relevanten Evals. Der 11-Punkte-Abstand bei Terminal Bench lässt sich nicht als Eval-Rauschen abtun.
Wer ein Coding-Agenten betreibt, der eine 30-Schritte-Schleife mit Dateisystem- und Shell-Zugriff ausführt, oder einen Recherche-Agenten, der pro Anfrage 5+ Tool-Calls orchestriert, wird bei Flash häufiger an schwer debuggbaren Stellen scheitern. Nicht weil Flash schlecht ist – sondern weil das genau der Workload ist, für den DeepSeek Pro gebaut hat.
Produktions-Entscheidungsrahmen
Die Auswahl ist nicht „welches ist besser”. Es ist „welches passt zu dieser Workload-Form”. Drei Standardregeln funktionieren gut.
Wann Pro wählen (agentisches Coding, Langzeit-Reasoning, Enterprise-Eval)
Pro ist die richtige Wahl, wenn eines der Folgenden zutrifft:
- Eine mehrstufige Agenten-Schleife wird betrieben (Claude Code-Stil, OpenCode, alles mit Tool-Nutzung + Planung + Verifikation pro Turn).
- Die Aufgabe erfordert präzises faktisches Abrufen über einen langen Schwanz von Entitäten – der 23-Punkte-SimpleQA-Abstand prognostiziert reale Halluzinationsunterschiede.
- Enterprise-Eval, bei der die Geschäftskosten einer falschen Antwort die Token-Kosten um Größenordnungen übersteigen.
- Langzeit-Reasoning über einen vollständigen 1-Millionen-Token-Kontext – Pros Effizienzwerte bei 1M Kontext sind die Architektur-Geschichte hier.
Wann Flash wählen (High-QPS-Klassifikation, Zusammenfassung, Chat-UX)
Flash ist nicht die Budget-Option. Es ist die richtige Option, wenn:
- High-QPS-Klassifikation, Tagging oder Extraktion betrieben wird – Latenz und Kosten pro Aufruf dominieren über die Qualitätsmarge.
- Zusammenfassung und Übersetzung – begrenzte, einschrittige Aufgaben, bei denen Flashs 1-2-Punkte-Benchmark-Delta für Nutzer unsichtbar ist.
- Interaktive Chat-UX – die First-Token-Latenz ist wichtiger als das 99. Perzentil der Antwortqualität, und Flash ist merklich schneller.
- Embedding-ähnliche Arbeit: Query-Rewriting, Intent-Klassifikation, Relevanz-Scoring.
Pro hier einzusetzen verschwendet das 10-fache bei Output-Token ohne wahrnehmbaren Gewinn. Das ist eine schlechtere Entscheidung als Flash für eine Agenten-Schleife zu nutzen.
Hybrides Routing: Flash als Standard, Pro als Fallback
Für die meisten Produkte ist die richtige Architektur weder das eine noch das andere – sondern beides, mit einem Router:
- Jede Anfrage standardmäßig an Flash weiterleiten.
- Zu Pro eskalieren bei einem oder mehreren expliziten Auslösern: Tool-Call-Fehler, verpasste Konfidenzschranke, Multi-Turn-Agent betritt eine bekannte schwierige Phase, Nutzer markiert eine Antwort als falsch.
- Eskalationsrate protokollieren. Wenn <5 % der Anfragen eskalieren, deckt Flash den Workload ab. Wenn >30 %, befindet man sich im Pro-Territorium und der Router ist nur Overhead.
Das funktioniert nur, weil Pro und Flash die API-Oberfläche und den Reasoning-Mode-Flag teilen. Das Wechseln zwischen beiden in einer laufenden Session ist eine Ein-Zeilen-Änderung in den meisten Clients. Die offiziellen DeepSeek-Preisdokumente bestätigen, dass die Modell-IDs Geschwister sind, keine isolierten Endpunkte.
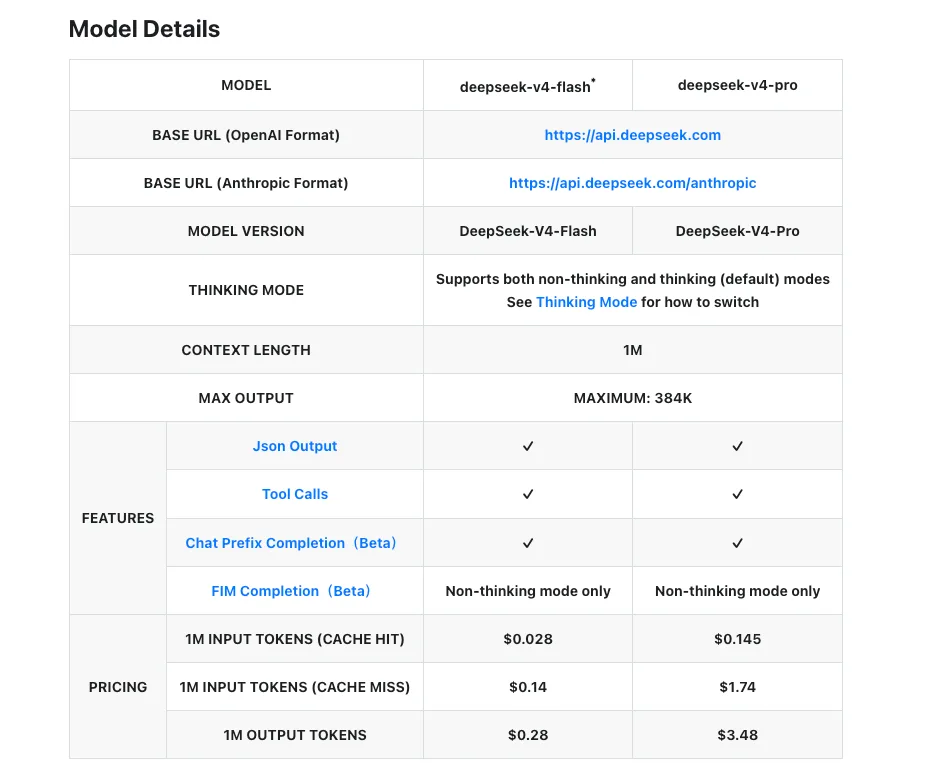
Kosten- und Latenz-Kompromisse (Stand: Veröffentlichungsdatum)
Nachstehende Zahlen stammen von DeepSeeks offizieller Preisseite vom 24. April 2026.
| V4-Flash | V4-Pro | |
|---|---|---|
| Eingabe (Cache-Miss) | 0,14 $ / M Tok | 1,74 $ / M Tok |
| Eingabe (Cache-Hit) | 0,028 $ / M Tok | 0,145 $ / M Tok |
| Ausgabe | 0,28 $ / M Tok | 3,48 $ / M Tok |
| Kontextfenster | 1M Token | 1M Token |
| Maximale Ausgabe | 384K Token | 384K Token |
Latenz-Hinweis: DeepSeek hat zum Zeitpunkt des Verfassens keine offiziellen Latenz-Zahlen pro Tier für V4 veröffentlicht. Drittanbieter-Berichte deuten darauf hin, dass Flash merklich schneller als Pro ausliefert, aber ich kann auf keine offizielle Benchmark verweisen – Verifikation erforderlich, sobald sich das Preview stabilisiert hat.
Einschränkungen und was noch verifiziert werden muss
Dies ist ein Preview-Release. Vor dem Weiterleiten von Produktions-Traffic zu beachten:
- Benchmark-Replikation. Alle obigen Zahlen stammen aus DeepSeeks eigenem technischen Bericht. Arena-Style-Leaderboards beginnen gerade erst, V4-Ergebnisse zu protokollieren. Noch keine unabhängigen SWE-Bench Pro- oder Terminal Bench-Durchläufe.
- Multimodal: noch nicht. Beide V4-Varianten sind textbasiert. DeepSeek hat angekündigt, dass Multimodal in Arbeit ist; kein Zeitplan dokumentiert.
- Kommerzieller Kontext. Bloombergs Berichterstattung über die Veröffentlichung stellt fest, dass V4 inmitten anhaltender geopolitischer Überprüfung von DeepSeek erscheint, und einige nicht-chinesische Deployments unterliegen Einschränkungen. Compliance-Position prüfen, bevor Nutzerdaten über die offizielle API geleitet werden; Self-Hosting der Open Weights ist der saubere Weg, falls das ein Problem ist.
- Preview-Stabilität. Das „Preview”-Label ist auch auf der V4-Flash-Modellkarte explizit. API-Verhalten und Preise werden sich voraussichtlich noch ändern.
- Deprecation-Fenster. Die
deepseek-chat- unddeepseek-reasoner-IDs werden am 24. Juli 2026 eingestellt. Sie routen derzeit zu V4-Flash. Wer diese IDs verwendet, nutzt bereits Flash-Qualität, ohne es zu wissen – explizit migrieren.
Das ist der Stand meiner Daten. Ich beobachte weiter und werde aktualisieren, sobald unabhängige Evals aufholen.
FAQ

Kann ich mitten in einem Gespräch zwischen Pro und Flash wechseln?
Ja. Beide teilen dieselbe API-Oberfläche und dasselbe OpenAI-kompatible Format. Der Wechsel ist eine Modell-ID-Änderung im Request-Body. Der Gesprächsverlauf (wie er in jedem Aufruf übergeben wird) ist zwischen beiden portierbar.
Unterstützen beide reasoning_effort?
Ja. Sowohl V4-Pro als auch V4-Flash unterstützen dieselben drei Reasoning-Effort-Modi – Non-Thinking, Thinking und Think Max – gemäß den offiziellen Modellkarten. Die Preisgestaltung ändert sich zwischen den Modi nicht; abgerechnet wird nach generierten Token, und Think Max generiert schlicht mehr.
Welche Version ist besser für Claude Code–ähnliche Agenten-Schleifen?
Pro. Der Terminal Bench 2.0-Abstand (67,9 vs. 56,9) ist der direkteste Näherungswert für mehrstufige Shell-/Tool-Schleifen, und das ist ein 11-Punkte-Unterschied. Flash funktioniert bei einfachen Agenten-Aufgaben, aber eine Schleife, die 10+ Tool-Calls verkettet, trifft genau die Kategorie, in der Flash am stärksten zurückfällt. DeepSeeks eigene Positionierungssprache sagt dies explizit – „vergleichbar mit Pro bei einfachen Agenten-Aufgaben”, nicht bei allen.
Kommerzielle Nutzungsbedingungen für beide?
Beide werden unter der MIT-Lizenz gemäß den offiziellen Hugging-Face-Repositories veröffentlicht, die kommerzielle Nutzung, Modifikation und Weitergabe erlaubt. Gewichte sind selbst hostbar. Für die gehostete API-Nutzung gelten DeepSeeks eigene Nutzungsbedingungen zusätzlich – diese für die jeweilige Deployment-Region prüfen.
Sind die Preisstrukturen identisch oder unterschiedlich?
Gleiche Struktur, unterschiedliche Sätze. Beide haben Eingabe-, Cache-Hit-Eingabe- und Ausgabe-Stufen. Beide unterstützen Cache-Rabatte auf wiederholte Präfixe. Das Verhältnis zwischen Pro- und Flash-Sätzen ist konsistent – Pro ist bei der Ausgabe pro Token etwa 12× teurer. Kein Plan-Tier oder commit-basiertes Pricing in den offiziellen Dokumenten zum Zeitpunkt des Verfassens.
Frühere Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten