DeepSeek V4 Pro vs Flash:哪個適合生產環境?
比較 DeepSeek V4 Pro 與 V4 Flash 的生產應用:能力取捨、延遲、成本,以及哪個版本最適合您的工作負載。

DeepSeek 發布了 V4,但不是單一模型,而是兩個版本:V4-Pro 擁有 1.6T 總參數量,激活參數 49B;V4-Flash 擁有 284B 總參數量,激活參數 13B。兩者均共享 100 萬 token 的上下文視窗,均採用 MIT 授權開放權重,均使用相同的 API 介面。
這一點至關重要,因為決策不再是「要不要用 DeepSeek」,而是哪個版本應該放在哪個端點後面。而正確答案很少是「所有地方都用 Pro」。
本文是為 AI 產品團隊和工程負責人所寫的選型指南,幫助他們正確分配工作負載。如果你讀過我之前關於 DeepSeek V4 API 開發者功能的文章,那是單模型時代的內容。這篇是分層版本。
以下所有數據截至發布日期。任何無法對照官方文件驗證的內容均有明確標注。
DeepSeek V4 Pro 與 Flash 概覽
各版本定位(來自官方預覽)
根據 DeepSeek 在 Hugging Face 上的 V4-Pro 模型卡,這種分層是有意為之的——它們不是同一個模型的不同規模。Flash 是獨立訓練的,並非從 Pro 蒸餾而來。
DeepSeek 官方的表述:
- V4-Pro — 豐富的世界知識超越開源模型,在數學/STEM/編程方面具備世界級推理能力,在 agentic 任務上表現最強。
- V4-Flash — 推理能力「接近」Pro,在簡單 agent 任務上與 Pro 表現相當,但在複雜任務上較弱。服務成本更低,響應更快。
「簡單 vs. 複雜」這個區別就是整個決策的核心。DeepSeek 直接告訴了你 Flash 的短板在哪裡,不要忽視這一點。
共同特性(100 萬上下文、思考模式、API 相容性)
兩者完全相同的特性:
- 100 萬 token 上下文視窗,由 DeepSeek 的混合注意力架構(CSA + HCA)實現。根據 Hugging Face 卡片,Pro 在 100 萬上下文下每 token 只需 V3.2 的 27% FLOPs 和 10% KV 快取。
- 三種推理強度模式 — 非思考、思考(高)和 Think Max。API 標誌相同,行為表現相同。
- OpenAI 相容的 Chat Completions API 和 Anthropic 協議支援。相同的
base_url,只需更換模型 ID。 - 兩者權重均為 MIT 授權,來自官方倉庫。
如果你在兩者之間遷移,整合介面不會改變,只有模型 ID 和費用會變。
能力差異
兩者在特定評測類別上存在分歧——模式足夠一致,可以從中建立路由規則。
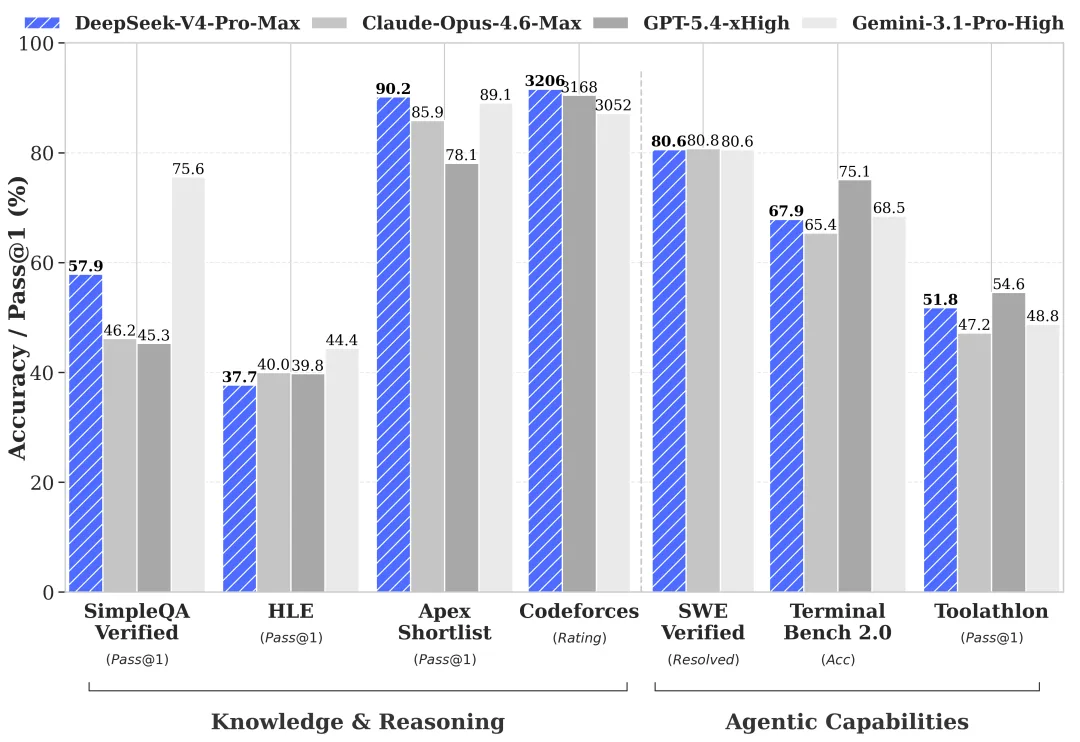
世界知識:Pro 領先,Flash 落後(來自官方基準測試——需驗證)
DeepSeek 自家的預覽基準測試(來自其 HF 卡片和技術報告)顯示,Pro/Flash 的差距在大多數評測類別上較小,但在幾個特定領域差距明顯:
| 基準測試 | V4-Pro | V4-Flash | 差距 |
|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 1.3 |
| LiveCodeBench | 93.5 | 91.6 | 1.9 |
| SWE-Verified | 80.6 | 79 | 1.6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57.9 | 34.1 | 23.8 |
| Terminal Bench 2.0 | 67.9 | 56.9 | 11 |
數據由 DeepSeek 提供。目前尚無第三方複現——在生產環境採用前需要驗證。但差距的形態才是信號,而非精確數字。
SimpleQA-Verified 測試的是事實召回,Terminal Bench 2.0 測試的是多步驟工具使用。Flash 在這兩項上都有明顯下滑,與 DeepSeek 明確表述的一致:簡單任務沒問題,複雜 agent 工作負載較弱。
簡單任務上的推理能力持平
在編程、數學和有界推理方面,差距縮小至 1-3 個百分點。LiveCodeBench 和 MMLU-Pro 上 Flash 與 Pro 非常接近。對於典型產品中的大多數推理調用——對話輪次、一次性生成、程式碼補全、摘要——Flash 不會讓用戶感受到任何降級。
這就是 Flash 價值主張的核心:它不是精簡版 Pro,而是一個獨立訓練的模型,恰好在基準測試分佈的中段接近 Pro 的水準。
高複雜度工作負載上的 Agent 任務分化
長時序、多工具、多跳類別是兩者分道揚鑣的地方。Terminal Bench 2.0 和 Toolathlon 是相關評測。Terminal Bench 上 11 個百分點的差距不是可以歸因於評測雜訊的邊際誤差。
如果你的產品是一個運行 30 步循環、帶有文件系統和 shell 訪問的編程 agent,或者是一個每次查詢協調 5 個以上工具調用的研究 agent,Flash 將更頻繁地在難以調試的地方失敗。這不是因為 Flash 不好——而是因為這正是 DeepSeek 專為 Pro 構建的工作負載。
生產環境決策框架
選型不是「哪個更好」,而是「哪個符合這個工作負載形態」。三個默認規則效果不錯。
何時選擇 Pro(agentic 編程、長時序推理、企業評估)
以下任意條件成立時,Pro 是正確選擇:
- 你正在運行多步驟 agent 循環(Claude Code 風格、OpenCode 或任何帶有工具使用 + 規劃 + 每輪驗證的場景)。
- 你的任務需要對大量長尾實體進行準確的事實召回——23 個百分點的 SimpleQA 差距預示著真實的幻覺差異。
- 你在做企業評估,錯誤答案的業務成本比每 token 成本高出幾個數量級。
- 你需要在真正的 100 萬 token 上下文中進行長時序推理——Pro 在 100 萬上下文下的效率數據是其架構優勢所在。
何時選擇 Flash(高 QPS 分類、摘要、聊天體驗)
Flash 不是預算選項,而是在以下情況下的正確選項:
- 你在運行高 QPS 分類、標記或提取——延遲和每次調用成本優先於質量邊際。
- 摘要和翻譯——有界的單次任務,Flash 1-2 個百分點的基準差距對用戶不可見。
- 互動式聊天體驗——首 token 延遲比答案質量的第 99 百分位更重要,而 Flash 明顯更快。
- 嵌入相鄰工作:查詢改寫、意圖分類、相關性評分。
在這些場景下選擇 Pro 會為毫無感知收益的輸出 token 多花 10 倍費用,這比把 Flash 用於 agent 循環更糟糕。
混合路由:Flash 默認,Pro 兜底
對於大多數產品,正確的架構既不是非此即彼,而是兩者結合,加上一個路由器:
- 默認將所有請求路由到 Flash。
- 在一個或多個明確觸發條件下升級到 Pro:工具調用失敗、置信度閾值未達到、多輪 agent 進入已知困難階段、用戶標記答案有誤。
- 記錄升級率。 如果 <5% 的請求升級,說明 Flash 已能覆蓋你的工作負載。如果 >30%,說明你在 Pro 領域,路由器只是額外開銷。
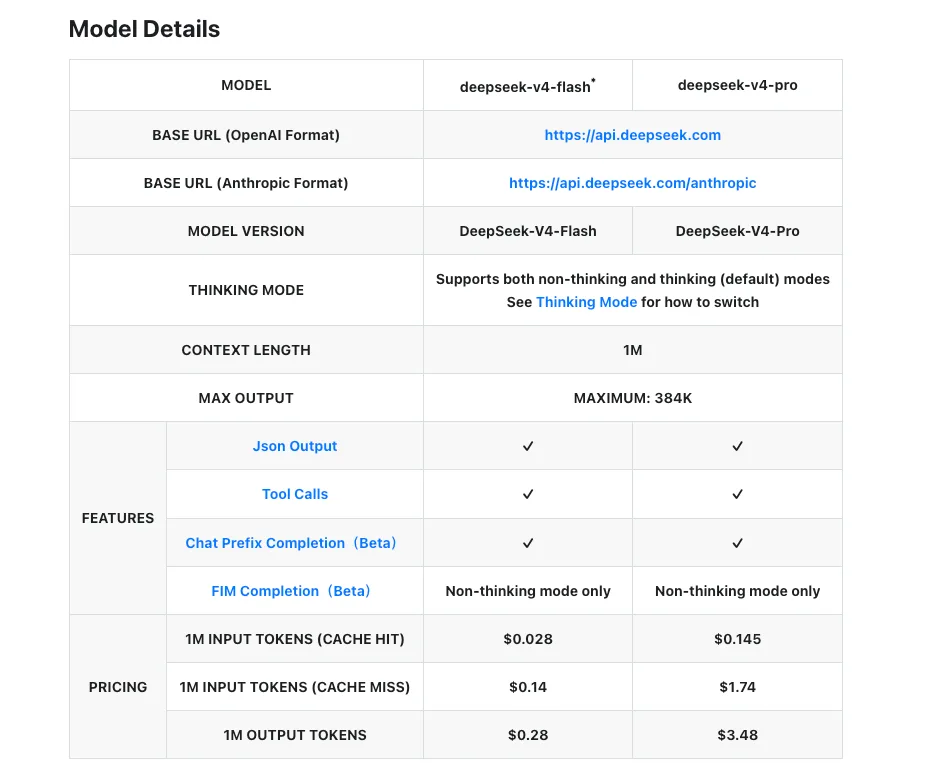
這之所以可行,是因為 Pro 和 Flash 共享 API 介面和推理模式標誌。在大多數客戶端中,會話中途切換只需一行代碼的改動。DeepSeek 官方定價文件確認兩個模型 ID 是同屬一家,而非隔離的端點。
成本與延遲權衡(截至發布日期)
以下數據來自 DeepSeek 官方定價頁面,截至 2026 年 4 月 24 日。
| V4-Flash | V4-Pro | |
|---|---|---|
| 輸入(快取未命中) | $0.14 / M tok | $1.74 / M tok |
| 輸入(快取命中) | $0.028 / M tok | $0.145 / M tok |
| 輸出 | $0.28 / M tok | $3.48 / M tok |
| 上下文視窗 | 100 萬 token | 100 萬 token |
| 最大輸出 | 384K token | 384K token |
兩個層級的輸入/輸出比率在快取未命中率下大約為 12 倍輸入、12 倍輸出。快取命中的經濟效益會進一步擴大差距——任何帶有長期穩定系統提示(agent 工具模式、RAG 上下文、少樣本示例)的場景,輸入端可節省 80-92%。根據 Simon Willison 的定價比較,V4-Flash 目前比 GPT-5.4 Nano 更便宜,V4-Pro 在輸出成本上低於所有前沿閉源模型。
延遲說明:截至撰文時,DeepSeek 尚未發布 V4 各層級的官方延遲數據。第三方報告顯示 Flash 服務速度明顯快於 Pro,但我無法指向官方基準測試——待預覽穩定後需驗證。
局限性與待驗證事項
這是預覽版本。在投入生產流量前需要注意以下幾點:
- 基準測試複現。 以上所有數據均來自 DeepSeek 自家技術報告。Arena 風格排行榜剛開始記錄 V4 結果,目前尚無獨立的 SWE-Bench Pro 或 Terminal Bench 測試結果。
- 多模態:尚不支援。 V4 兩個變體均為純文字。DeepSeek 表示多模態正在開發中,目前無時間表。
- 商業背景。 彭博社對此次發布的報導指出,V4 發布之際 DeepSeek 正面臨持續的地緣政治審查,部分非中國部署存在限制。在通過官方 API 路由用戶數據前,請確認你的合規狀況;如果這是個問題,自託管開放權重是更乾淨的方案。
- 預覽穩定性。 「預覽」標籤在 V4-Flash 模型卡上也有明確標注。API 行為和定價預計會有變動。
- 棄用視窗。
deepseek-chat和deepseek-reasonerID 將於 2026 年 7 月 24 日退役。它們目前路由到 V4-Flash。如果你在使用這些 ID,你已經在享受 Flash 質量而不自知——請明確遷移。
我的數據到此為止,持續關注中。等第三方評測跟上後會更新。
常見問題

我可以在對話中途切換 Pro 和 Flash 嗎?
可以。兩者共享相同的 API 介面和 OpenAI 相容格式。切換只需修改請求體中的模型 ID。對話歷史(每次調用時作為參數傳入)在兩者之間是可移植的。
兩者都支援 reasoning_effort 嗎?
支援。根據官方模型卡,V4-Pro 和 V4-Flash 均支援相同的三種推理強度模式——非思考、思考和 Think Max。模式之間不影響定價;計費基於生成的 token 數量,Think Max 只是生成更多 token。
Claude Code 風格的 agent 循環哪個版本更好?
Pro。Terminal Bench 2.0 的差距(67.9 vs 56.9)是多步驟 shell/工具循環最直接的代理指標,差距達 11 個百分點。Flash 可以處理簡單 agent 任務,但一個串接 10 個以上工具調用的循環恰好命中了 Flash 退步最明顯的類別。DeepSeek 自己的定位語言明確指出——「在簡單 Agent 任務上與 Pro 相當」,而非所有 agent 任務。
兩者的商業使用條款?
根據官方 Hugging Face 倉庫,兩者均在 MIT 授權下發布,允許商業使用、修改和再發行。權重可自託管。對於託管 API 使用,DeepSeek 自身的服務條款在此之上適用——請根據你的部署地區進行確認。
定價結構相同還是不同?
結構相同,費率不同。兩者均有輸入、快取命中輸入和輸出分級。兩者均支援對重複前綴的快取折扣。Pro 與 Flash 費率之間的比例一致——Pro 每輸出 token 的成本大約貴 12 倍。截至撰文時,官方文件中沒有基於方案或承諾用量的定價。
往期文章:
