Qwen3.5-Omni vs GPT-4o vs Gemini 2.5 Pro:全能模型对比
面向开发者的Qwen3.5-Omni vs GPT-4o与Gemini 2.5 Pro深度对比:音频基准测试、多语言语音、API访问、自托管及定价全面比较。
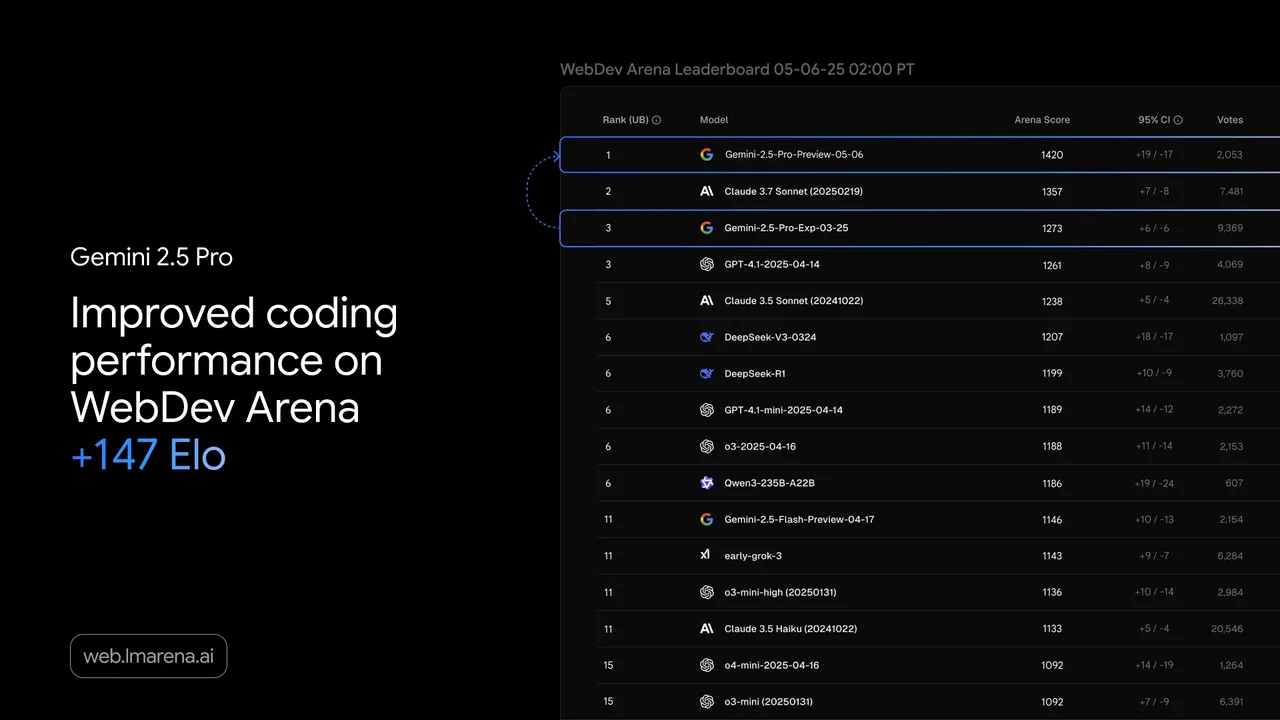
大家好!我是 Dora,像往常一样,桌上摆着一份语音智能体项目规格书,需要做出决策:选择哪个模型系列来构建。GPT-4o 是所有人默认的选择。Gemini 2.5 Pro 因其上下文窗口上限而被反复提及。然后,Qwen3.5-Omni 在三月底发布,其声称的能力让我滑屏滑到一半就停了下来——113 种识别语言、开放权重路径、分层定价、256K 上下文。我无法忽视它。
于是我深入研究了一番。这不是一篇基准测试汇总,而是一份决策指南:每个模型究竟提供什么,哪些数据经得起推敲,以及哪个模型适合你的具体构建场景。
这些模型如何定位自身
Qwen3.5-Omni:开放权重优先、自托管可行、多语言语音
Qwen3.5-Omni 是阿里巴巴的原生全模态模型——文本、音频、图像和视频输入,文本或实时语音输出,全部在一次推理调用中完成。它有三个变体:Plus(30B-A3B MoE)、Flash(更轻量的 MoE,延迟更低)和 Light(更小的密集模型,权重在 HuggingFace 上开放)。其架构为 Thinker-Talker——推理组件和语音合成组件以分离系统运行,从而在完整响应生成完毕之前即可开始流式语音输出。
最显著的差异化优势在于自托管。Plus 和 Flash 可通过 DashScope API 访问;Light 变体为开放权重。如果数据驻留、微调或规模化成本是首要考量,Qwen3.5-Omni 是本次对比中唯一具有实际自托管路径的选项。该模型支持通过 DashScope 提供的 OpenAI 兼容 API 格式,降低了已在使用 OpenAI SDK 的团队的集成难度。
GPT-4o:闭源 API、深度集成工具链、OpenAI 生态系统
GPT-4o 是 OpenAI 的旗舰多模态模型,可通过标准 Chat Completions API 和用于语音到语音工作负载的 Realtime API 访问。没有自托管路径——完全闭源。GPT-4o 在灵活性上的妥协,换来的是生态系统成熟度:函数调用、Assistants API、微调、Batch API、代码解释器、文件搜索,以及大多数团队已经集成的开发者工具链。如果你的技术栈已在 OpenAI 上运行,切换成本是真实存在的。
GPT-4o 中的音频通过两条不同路径处理:Chat Completions API(gpt-4o-audio-preview,异步)和 Realtime API(gpt-realtime,低延迟 WebSocket)。这是具有不同定价的独立端点,对语音智能体架构决策至关重要。
Gemini 2.5 Pro:Google 基础设施、原生多模态、Vertex AI 集成
Gemini 2.5 Pro 是 Google 的中高端旗舰产品,专为需要强大推理和多模态理解的任务而设计。它支持 100 万 token 的上下文窗口——是本次对比中最大的,比其他模型大四倍——可通过 Gemini Developer API 和 Vertex AI 访问。Vertex 路径是企业级路线:它与 Google Cloud IAM、数据驻留控制和 Workspace 工具集成,但也引入了 Vertex 特定的定价和锁定考量。
支持音频输入;原生实时语音输出通过 Live API(低延迟对话式)处理,而非标准的补全端点。对于已在 Google Cloud 上的团队,集成故事颇具吸引力。对于不在 Google Cloud 上的团队,Vertex 增加了 Gemini Developer API 可以避免的上手摩擦。
核心对比表
| 维度 | Qwen3.5-Omni (Plus) | GPT-4o | Gemini 2.5 Pro |
|---|---|---|---|
| 上下文窗口 | 256K tokens | 128K tokens | 1M tokens |
| 音频输入限制 | 约 10 小时连续 | 受 128K 上下文限制 | 1M 上下文约 11 小时 |
| 语音输出语言 | 36 种 | 约 6 种(预设声音) | 有限(Live API) |
| 语音识别语言 | 113 种 | 基于 Whisper(约 100 种) | 强多语言支持 |
| 自托管 | ✅ 可行(Light 开放权重;Plus/Flash 通过 API) | ❌ 不可用 | ❌ 不可用 |
| 开放权重 | ✅ Light 变体(HuggingFace) | ❌ | ❌ |
| 定价模式 | 按每次请求的输入 token 数分层 | 按 token 统一定价(音频单独计费) | 按上下文长度分层(>200K 费率更高) |
| 文本输入定价(每 1M) | 按分层定价;参见 DashScope | $2.50 | $1.25(≤200K tokens) |
| 音频输入定价 | 按模态计费;参见 DashScope | 约 $100/1M tokens(Realtime:$32/1M) | 约 $1.00/1M(Gemini 2.5 Flash 音频费率) |
| API 兼容性 | OpenAI 兼容(DashScope) | OpenAI 原生 | OpenAI 兼容(部分) |
| 免费额度 | 100 万 tokens(国际版,90 天) | 无(仅试用积分) | 慷慨的免费套餐(Google AI Studio) |
| Vertex/企业集成 | 仅限阿里云 | Azure OpenAI/企业协议 | 原生 Google Cloud/Vertex AI |
| 发布状态 | 2026 年 3 月 30 日(非常新) | GA,生产稳定 | GA,生产稳定 |
定价数据:GPT-4o 文本来自 OpenAI 定价页面;Gemini 2.5 Pro 来自 Google AI Developer 定价;Qwen3.5-Omni 来自 DashScope 定价。音频费率为近似值——进行成本建模前请务必核实。
音频和语音基准测试:对开发者意味着什么
Qwen3.5-Omni-Plus 领先的地方
阿里巴巴声称 Qwen3.5-Omni-Plus 在 215 个音频和音视频子任务上取得了 SOTA 结果,在通用音频理解、推理、识别和翻译基准测试上优于 Gemini 3.1 Pro。在多语言 ASR 方面,从上一代的 19 种语言跃升至 113 种,是对非英语优先团队最重要的核心指标。
在音视频理解方面——例如总结带环境音的视频、回答关于录制会议的问题,或为音频内容添加字幕——该模型具有专属的架构优势:Thinker 原生地将所有模态一起处理,而不是通过独立的编码器堆栈进行路由。
GPT-4o 和 Gemini 保持优势的地方
GPT-4o 的优势不在于原始音频基准测试——而在于生态系统集成。Realtime API 中的函数调用、用于持久线程的 Assistants API、针对领域数据的微调,以及已在生产环境中大规模测试过的开发者工具链。如果你正在构建需要调用外部 API、管理对话状态或与现有 OpenAI 工作流集成的语音智能体,GPT-4o 的工具成熟度是真正的差异化优势。

Gemini 2.5 Pro 的优势在于上下文和 Google 集成。对于希望在单次请求中处理数小时内容而无需分块的音频或视频分析任务,100 万 tokens 是本次对比中的实际上限。对于在 Google Cloud 上运行 Vertex AI 管道的团队,集成是原生的且合同上熟悉的。
基准测试注意事项:SOTA 数量 vs. 实际部署差距
“215 项 SOTA 结果”这一数字在影响你的决策之前值得仔细审视。关于这个数字的构建方式,有几点需要了解:
首先,SOTA 数量是跨许多子任务的聚合——各个语言对、特定音频类型、狭义的基准测试类别。一个模型可以声称数百项 SOTA,同时在对你的用例最重要的特定基准测试上(比如你的语言、你的领域词汇、你的音频质量档案)表现不佳。
其次,Qwen3.5-Omni 于今年三月底发布。撰写本文时,独立的第三方评估尚不存在。阿里巴巴引用的对比数据是由发布团队生成的,使用的是团队选择的基准测试。这不是对不诚实的指控——这是模型发布的标准做法——但在中立评估出现之前,这是应保持的适当认知立场。
第三,基准测试性能 ≠ 生产性能。口音覆盖范围、罕见词汇、背景噪音处理、特定领域术语以及真实世界的音频质量,都会以精心策划的基准测试无法捕捉的方式影响生产 ASR 质量。在做出承诺之前,请用你自己的音频样本进行测试。

多语言语音支持
113 种识别语言 vs. GPT-4o 基于 Whisper 的方案
GPT-4o 的音频识别继承自 Whisper 架构,支持大约 100 种语言,但质量参差不齐。该模型在高资源语言(英语、西班牙语、法语、普通话)上表现强劲,在低资源语言和方言上则有所退化。OpenAI 不发布每种语言的准确率详情,这使得不常见语言的质量难以提前核实。
Qwen3.5-Omni 的 113 种语言声明在范围上相似,但明确包含了该数量中的方言覆盖——这一区别对南亚、东南亚和非洲语言覆盖很重要,在这些地区,“一种语言”和”其方言”可能具有截然不同的 ASR 质量。与任何语言数量声明一样,请用你目标用户的真实样本进行测试。阿里巴巴有方言计数慷慨的历史;请据此进行校准。
36 种语音输出语言:适用于哪些市场?
36 种语言的语音输出使 Qwen3.5-Omni 在非英语 TTS 方面领先于 GPT-4o 目前的预设语音选项(主要是英语加少量其他语言)。对于构建面向拉丁美洲、东南亚或多语言欧洲市场的语音智能体的产品团队,如果相关语言已被覆盖且质量满足用例需求,36 种输出语言是一个有意义的能力差距。
Gemini 2.5 Pro 的 Live API 也支持多语言语音输出,但语言覆盖文档不够明确。在将 Qwen 或 Gemini 用于多语言 TTS 用例之前,请专门核实你目标语言的覆盖情况。
语义打断和声音克隆:差异化还是基本功能?
Qwen3.5-Omni 引入了语义打断——模型尝试区分用户真正插话与环境背景噪音。这对于嘈杂环境中的语音智能体部署是真正的用户体验改进,但它越来越成为预期的基准功能,而非差异化优势。在将其作为决策驱动因素之前,请测试它是否在你的声学环境中可靠工作。
声音克隆(上传声音样本,模型以该声音回应)可通过 API 在 Plus 和 Flash 中使用。GPT-4o 的 Realtime API 通过微调支持自定义语音,但不以同样的方式暴露直接的声音克隆。如果长对话中的语音人设一致性是产品需求,这是一个真正的能力差异。
API 访问和基础设施适配
DashScope vs. OpenAI API vs. Google Vertex:集成复杂度
对于已在使用 OpenAI SDK 的团队,DashScope 的 OpenAI 兼容端点很容易对接:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DASHSCOPE_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3-omni-flash", # 或 qwen3-omni-plus
messages=[{"role": "user", "content": "Your message here"}]
)对于多模态输入(音频、视频),你需要使用 DashScope 的原生多模态端点,其请求结构略有不同。OpenAI 兼容性主要适用于文本补全路径。在构建音频管道之前,请核实哪些端点支持哪些模态。
Google 的 Vertex AI 集成是三者中最复杂的——它需要 Google Cloud 项目设置、IAM 配置,并使用 Vertex SDK 或 Gemini Developer API,两者具有不同的认证流程和略微不同的行为。其回报是企业级访问控制、合规文档和 Google 的 SLA 框架。
自托管:只有 Qwen3.5-Omni 提供实际可行的路径
这是本次对比中结构上最显著的差异。GPT-4o 和 Gemini 2.5 Pro 是闭源权重模型——没有自托管路径,句号。如果你的用例要求数据永远不离开你自己的基础设施(某些医疗、金融或国防场景),或者你需要在模型级别对专有音频数据进行微调,只有 Qwen3.5-Omni 为你提供路径。
Light 变体在 HuggingFace 上为开放权重。Plus 和 Flash 截至 2026 年 3 月 31 日仅可通过 API 访问——这些变体的开放权重在撰写本文时尚未确认已公开发布。如果你的需求是 Plus 级别的质量加上完整的自托管,请在将架构建立在此基础上之前核实当前的开放权重状态。
对于自托管需求,vLLM 部署文档和 Qwen 团队的官方 GitHub 是设置的权威参考。
数据驻留和端点地理位置
对于中国以外的团队,DashScope 的国际版(新加坡)端点是默认选项。美国弗吉尼亚端点可用,但没有免费额度,且在撰写本文时,请在将生产流量路由到该端点之前,确认 Omni 模型的多模态(音频/视频)支持情况。
定价结构对比
输入 Token 分层 vs. 按次统一定价
三家提供商的基本定价架构各不相同:
Qwen3.5-Omni(DashScope): 基于当前请求的输入 token 数的分层定价。在单次请求内跨越分层边界会使整个请求的输入费率提高——而不仅仅是超出阈值的 token。这意味着 35K token 的音频片段和 5K token 的文本查询按不同的每 token 费率计费,即使你的月度用量相同。短请求价格便宜;长上下文音频请求比统一费率模型暗示的价格更快变贵。
GPT-4o: 文本按 token 统一定价(输入 $2.50/输出 $10.00,每 1M tokens)。音频是完全独立的计费项:Chat Completions 音频路径约 $100/1M 音频输入 tokens;Realtime API(gpt-realtime)在近期降价 20% 后为 $32/1M 音频输入和 $64/1M 音频输出。Realtime API 中的文本 token 为输入 $4.00/输出 $16.00——显著高于标准 Chat Completions 费率。
Gemini 2.5 Pro: 按上下文长度分层,但结构更简单:≤200K tokens 的提示按标准费率(输入 $1.25/输出 $10.00,每 1M tokens);>200K tokens 的提示费率翻倍。音频输入的定价高于文本——Flash 层级约为 3 倍;请在 Google AI Developer 定价文档中核实 Pro 音频费率。批处理模式对异步工作负载的费率降低 50%。
规模化成本:高并发语音/音频工作负载
以具体的工作负载进行对比,考虑每月 100,000 分钟音频输入——大约是中等规模的转录或语音智能体操作:
- 按约 427 tokens/分钟音频(基于 Qwen 发布的上下文数学),每月约 4,270 万音频输入 tokens
- GPT-4o Realtime 按 $32/1M 音频输入:仅音频输入每月约 $1,366,不含文本输入/输出成本
- Gemini 2.5 Pro 音频(Flash 层级约 $1.00/1M,Pro 可能不同):如果在标准上下文范围内约 $427/月——请核实 Pro 音频费率
- Qwen3.5-Omni:成本完全取决于音频如何批处理到请求中;每个跨越分层边界的请求为整个请求支付更高的费率。在不知道请求大小分布的情况下无法给出固定数字
在非常高的用量和可预测的请求大小下,自托管 Qwen3.5-Omni 的 Flash 或 Light 变体值得计算。一台运行 FP8 精度的 H100 80GB 可以处理生产推理,GPU 小时费率在超过某个月度用量后会低于 API 成本。
决策框架:何时选择哪个
选择 Qwen3.5-Omni 的情况:
- 需要自托管——数据驻留、微调或供应商独立性是不可谈判的。这是本次对比中唯一具有开放权重路径的模型。
- 多语言语音是主要用例——113 种 ASR 语言和 36 种 TTS 语言,结合原生全模态架构,对于非英语优先产品是有意义的能力优势。请核实你的特定语言是否在可接受的质量水平上有效。
- 规模化成本敏感性很重要——在高用量下,自托管的 Flash 或 Light 变体可以显著低于 API 定价。在纯 API 使用上,在假设它更便宜之前,请针对你的请求大小分布仔细建模分层定价。
- 你需要声音克隆或长对话中的语音人设一致性——这目前在 Qwen3.5-Omni 中比在 GPT-4o 或 Gemini 中更容易实现。

选择 GPT-4o 的情况:
- OpenAI 生态系统已在你的技术栈中——Assistants API、微调、函数调用、Batch API。切换成本是真实存在的;工具成熟度是真实的。
- 工具成熟度比成本更重要——对于需要复杂工具调用、多轮状态管理或与现有 OpenAI 工作流集成的语音智能体,GPT-4o 的生产记录是三者中最强的。
- 你主要在英语或高资源西欧语言中构建——GPT-4o 对这些语言的 ASR 质量经过充分测试,在生产中可靠。
选择 Gemini 2.5 Pro 的情况:
- Google Cloud 是你的基础设施——如果你已经在 Google 生态系统中,原生 Vertex AI 集成、GCP IAM 和企业协议是真正的优势。
- 你需要 1M+ token 上下文——对于处理非常长的录音、多小时内容分析,或在不分块的情况下维护非常长的对话历史,Gemini 的上下文上限在本次对比中明显胜出。
- Google Workspace 集成很重要——对于涉及 Docs、Drive、Meet 或其他 Workspace 产品的企业用例,Gemini-Workspace 集成路径比其他选择更自然。
承诺前需要了解的局限性
Qwen3.5-Omni:MoE 推理开销、早期 API 稳定性
Plus 变体的 MoE 架构意味着推理性能不如同等质量的密集模型可预测。在可变并发下,路由开销可能导致延迟峰值。vLLM 对于自托管部署相比 HuggingFace Transformers 显著缓解了这一问题,但不能消除它——MoE 路由延迟是架构固有的。
API 稳定性是一个悬而未决的问题。目前速率限制未公开记录。负载下的端点行为、SLA 承诺和版本固定保证在这个阶段都是未知数。对于有运行时间要求的生产部署,请规划一个备用方案。
GPT-4o:无自托管、规模化定价不透明
没有自托管,句号。如果这是硬性要求,GPT-4o 不是候选项。
通过 Realtime API 的音频定价(输入 $32/1M,输出 $64/1M)在规模化下并不便宜,而且计费结构——同一对话中文本和音频 token 分别计费——如果开发者假设适用标准 Chat Completions 费率,可能会产生账单意外。Realtime API 基于会话的上下文窗口管理也为长对话增加了成本复杂性。
OpenAI 对模型和功能的定价历史包括降价和重组。对于需要持续 12 个月以上的成本模型,OpenAI 定价的可预测性不如 Google 的。
Gemini 2.5 Pro:Vertex 锁定、中国可访问性
Vertex AI 集成对 Google Cloud 团队是真正的优势,对其他所有人是真正的限制。企业功能、数据驻留控制和合规工具是 Vertex 原生的;Gemini Developer API 的企业控制较少。在 Developer API 上开始并迁移到 Vertex 用于生产的团队将遇到不同的 SDK、不同的认证和不同的计费。
Gemini 模型在中国大陆无法可靠访问。如果你的团队或用户在中国运营,DashScope 路径是实际可行的选择。
Gemini 2.5 Pro 的 200K token 定价阈值也值得注意:如果你的平均请求持续超过 200K tokens,你支付的是公告输入费率的 2 倍。要使 1M 上下文具有成本效益,你需要确实能从完整窗口受益而又不会过于频繁触及 2 倍分层的工作负载。
常见问题
Qwen3.5-Omni 在多语言语音应用中比 GPT-4o 更好吗?
从书面数据和基准测试来看,Qwen3.5-Omni-Plus 在语言数量(113 种 ASR,36 种 TTS)和音视频理解基准测试上处于领先。实际上,答案取决于你的具体语言、音频质量和领域。Qwen3.5-Omni 于 2026 年 3 月 30 日发布——独立的生产评估尚不存在。在决定之前,请用你目标用户的真实样本进行测试。
我可以在不使用 DashScope 的情况下将 Qwen3.5-Omni 用于生产吗?
Light 变体在 HuggingFace 上以开放权重提供,适合在适当硬件上进行自托管生产部署。Plus 和 Flash 目前仅可通过 DashScope API 使用。截至 2026 年 3 月 31 日,Plus/Flash 的开放权重尚未确认——在规划自托管 Plus 部署之前,请核实当前状态。
Qwen3.5-Omni 支持 OpenAI API 格式吗?
支持。DashScope 在 https://dashscope-intl.aliyuncs.com/compatible-mode/v1 暴露了 OpenAI 兼容端点,支持 Chat Completions API 格式。这适用于文本和文本+视觉输入。对于音频和视频输入,请核实你需要的特定模态是通过兼容端点处理还是需要 DashScope 的原生多模态端点——兼容层并非对所有模态同等覆盖。
往期文章:
