DeepSeek V4 Pro vs Flash:生产环境该如何选择?
对比 DeepSeek V4 Pro 与 V4 Flash 的生产适用性:能力权衡、延迟、成本,以及哪个版本更适合您的工作负载。

DeepSeek 发布的 V4 不是一个模型,而是两个:V4-Pro 拥有 1.6T 总参数,激活参数 49B;V4-Flash 拥有 284B 总参数,激活参数 13B。两者均支持 1M token 上下文窗口,均以 MIT 协议开放权重,均使用相同的 API 接口。
这一点至关重要,因为问题不再是”用不用 DeepSeek”,而是哪个端点该用哪个版本。正确答案很少是”所有地方都用 Pro”。
本文是为 AI 产品团队和技术负责人撰写的选型指南,帮助他们正确分配工作负载。如果你读过我此前关于 DeepSeek V4 API 开发者功能的文章,那是单模型时代的内容。这篇是分层版本。
以下所有数据均以发布日期为准。凡是无法对照官方文档核实的内容,均已明确标注。
DeepSeek V4 Pro 与 Flash 一览
各版本定位(来自官方预览)
根据 DeepSeek 在 Hugging Face 上的 V4-Pro 模型卡,这两个版本的划分是有意为之——它们并非同一模型的不同尺寸。Flash 是单独训练的,并非从 Pro 蒸馏而来。
DeepSeek 官方的定位描述:
- V4-Pro — 丰富的世界知识,超越开源模型;在数学/STEM/编程领域具备世界级推理能力;在智能体任务上表现最强。
- V4-Flash — 推理能力”接近” Pro,在简单智能体任务上与 Pro 相当,在复杂任务上表现较弱。服务成本更低,响应速度更快。
“简单 vs 复杂”这一区分,正是整个选型的核心。DeepSeek 已经直接告诉你 Flash 的短板在哪里,不要忽视。
共同特性(1M 上下文、思考模式、API 兼容性)
两个版本完全相同的特性:
- 1M token 上下文窗口,两个版本均支持,得益于 DeepSeek 的混合注意力架构(CSA + HCA)。根据 Hugging Face 模型卡,Pro 在 1M 上下文下每 token 仅需 V3.2 的 27% FLOPs 和 10% KV 缓存。
- 三种推理力度模式 — 不思考、思考(高)和 Think Max。API 参数相同,行为表面一致。
- OpenAI 兼容的 Chat Completions API 和 Anthropic 协议支持。相同的
base_url,只需替换模型 ID。 - 两者权重均采用 MIT 协议,可见官方仓库。
如果你在两者之间迁移,集成层面无需改动,只需更换模型 ID 和账单对象。
能力差异
两者的分歧体现在特定评测类别上——规律足够一致,可以据此建立路由规则。
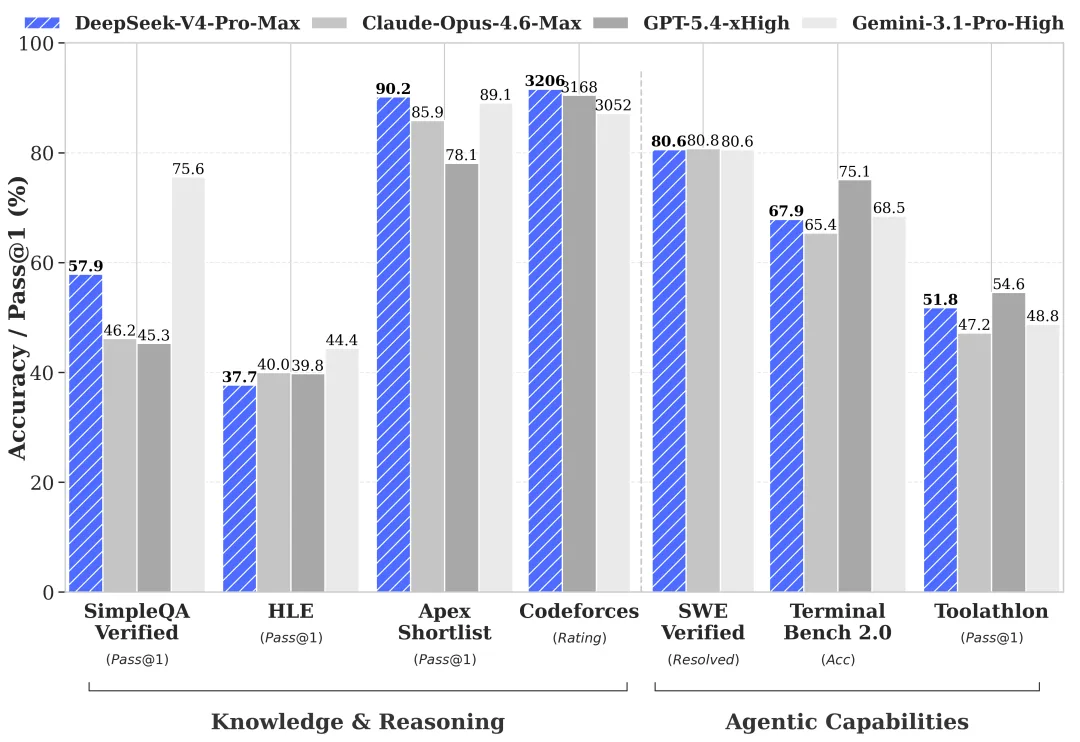
世界知识:Pro 领先,Flash 落后(来自官方基准测试——需验证)
DeepSeek 官方预览基准测试(汇总自其 HF 模型卡和技术报告)显示,Pro 与 Flash 在大多数评测类别上差距较小,但在少数特定类别上差距显著:
| 基准测试 | V4-Pro | V4-Flash | 差距 |
|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 1.3 |
| LiveCodeBench | 93.5 | 91.6 | 1.9 |
| SWE-Verified | 80.6 | 79 | 1.6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57.9 | 34.1 | 23.8 |
| Terminal Bench 2.0 | 67.9 | 56.9 | 11 |
数据由 DeepSeek 提供。目前尚无第三方复现——投入生产前需验证。但差距的形态才是信号,而非具体数字。
SimpleQA-Verified 考察的是事实回忆,Terminal Bench 2.0 考察的是多步骤工具使用。Flash 在这两项上均有明显下滑,与 DeepSeek 的说法一致:简单任务没问题,复杂智能体工作负载表现较弱。
简单任务上的推理持平
在编程、数学和有界推理任务上,差距收窄至 1-3 分。LiveCodeBench 和 MMLU-Pro 显示 Flash 与 Pro 相差无几。对于典型产品中的大多数推理调用——对话轮次、单次生成、代码补全、摘要——Flash 在用户可感知层面并无退步。
这是 Flash 价值主张的核心:它不是阉割版的 Pro,而是一个单独训练的模型,恰好在基准测试分布的中段接近 Pro 的水平。
高复杂度工作负载上的智能体任务分歧
长时程、多工具、多跳类别是两者拉开差距的地方。Terminal Bench 2.0 和 Toolathlon 是相关评测。Terminal Bench 上 11 分的差距不是可以归因于评测噪声的误差范围。
如果你的产品是运行 30 步循环并带有文件系统和 shell 访问权限的编程智能体,或是每次查询协调 5+ 个工具调用的研究智能体,Flash 会在调试成本高昂的地方更频繁地失败。这不是因为 Flash 差,而是因为这正是 DeepSeek 为 Pro 设计的工作负载。
生产环境决策框架
选型不是”哪个更好”,而是”哪个匹配这种工作负载形态”。以下三个默认策略效果良好。
何时选择 Pro(智能体编程、长时程推理、企业评估)
满足以下任一条件时,Pro 是正确选择:
- 你在运行多步骤智能体循环(Claude Code 风格、OpenCode,或任何每轮带有工具使用 + 规划 + 验证的场景)。
- 你的任务需要对长尾实体进行准确的事实回忆——23 分的 SimpleQA 差距预示着真实的幻觉差异。
- 你在做企业评估,错误答案的业务成本比每 token 成本高出几个数量级。
- 你需要在真正完整的 1M token 上下文中进行长时程推理——Pro 在 1M 上下文下的效率数据是其架构优势的体现。
何时选择 Flash(高 QPS 分类、摘要、对话 UX)
Flash 不是预算选项,而是以下场景的正确选项:
- 运行高 QPS 分类、标注或抽取任务——延迟和每次调用成本优先于质量差距。
- 摘要和翻译——有界的单次任务,Flash 1-2 分的基准差距对用户不可见。
- 交互式对话 UX——首 token 延迟比答案质量的第 99 百分位更重要,Flash 明显更快。
- 嵌入相关工作:查询改写、意图分类、相关性评分。
在这些场景下选 Pro,为毫无可感知收益的输出 token 多花 10 倍费用,反而是更糟糕的决策。
混合路由:Flash 默认,Pro 兜底
对于大多数产品,正确的架构既不是单独用 Flash,也不是单独用 Pro——而是两者结合,加上一个路由器:
- 默认所有请求走 Flash。
- 满足以下一个或多个显式触发条件时升级到 Pro:工具调用失败、置信度阈值未达到、多轮智能体进入已知困难阶段、用户标记答案有误。
- 记录升级率。 如果不到 5% 的请求升级,Flash 能覆盖你的工作负载;如果超过 30%,你属于 Pro 用户,路由器只是额外开销。
这种方案之所以可行,是因为 Pro 和 Flash 共享 API 接口和推理模式参数。在大多数客户端中,会话中途切换只需修改一行代码。DeepSeek 官方定价文档确认两个模型 ID 是同级关系,而非隔离的端点。
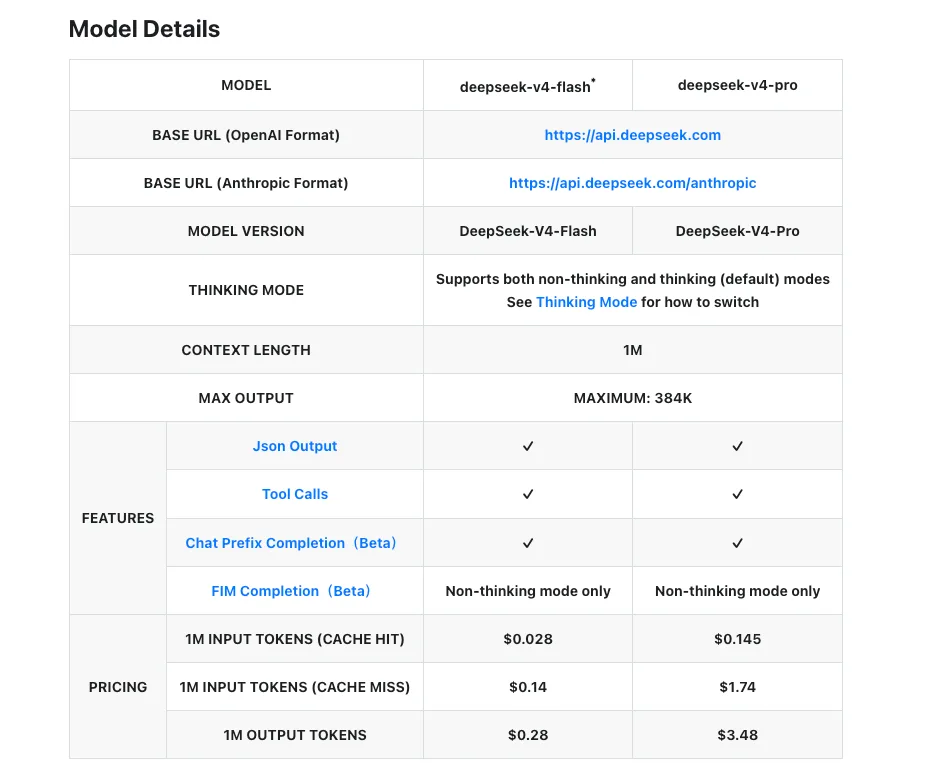
成本与延迟权衡(截至发布日期)
以下数据来自 DeepSeek 官方定价页面,日期为 2026 年 4 月 24 日。
| V4-Flash | V4-Pro | |
|---|---|---|
| 输入(缓存未命中) | $0.14 / M token | $1.74 / M token |
| 输入(缓存命中) | $0.028 / M token | $0.145 / M token |
| 输出 | $0.28 / M token | $3.48 / M token |
| 上下文窗口 | 1M tokens | 1M tokens |
| 最大输出 | 384K tokens | 384K tokens |
两个层级在缓存未命中情况下,输入和输出的价格比约为 12 倍。缓存命中的经济效益进一步拉大差距——凡是有较长稳定系统提示的场景(智能体工具模式、RAG 上下文、少样本示例),输入侧可节省 80-92%。根据 Simon Willison 的定价对比,V4-Flash 目前比 GPT-5.4 Nano 更便宜,V4-Pro 的输出成本低于所有前沿闭源模型。
延迟披露:撰写本文时,DeepSeek 尚未发布 V4 各层级的官方延迟数据。第三方报告显示 Flash 明显快于 Pro,但我无法提供官方基准——待预览稳定后需验证。
局限性与待验证事项
这是预览版本。在将生产流量切入之前,需关注以下几点:
- 基准测试复现。 上述所有数据均来自 DeepSeek 自己的技术报告。Arena 风格排行榜刚开始记录 V4 结果,目前尚无独立的 SWE-Bench Pro 或 Terminal Bench 运行数据。
- 多模态:暂不支持。 两个 V4 版本均为纯文本。DeepSeek 表示多模态正在开发中,目前没有时间表。
- 商业背景。 Bloomberg 对本次发布的报道指出,V4 发布时 DeepSeek 正面临持续的地缘政治审查,部分非中国地区的部署存在限制。将用户数据路由至官方 API 前,请核查你的合规态势;如有顾虑,自托管开放权重是更干净的方案。
- 预览稳定性。 V4-Flash 模型卡上同样明确标注了”预览”。API 行为和定价预计会有变动。
- 弃用时间窗口。
deepseek-chat和deepseek-reasonerID 将于 2026 年 7 月 24 日停用,目前它们路由到 V4-Flash。如果你还在使用这些 ID,实际上已经在使用 Flash 质量,只是不知道而已——请明确迁移。
我的数据止于此处,持续关注中。等第三方评测跟上后会更新。
常见问题

可以在对话过程中切换 Pro 和 Flash 吗?
可以。两者共享相同的 API 接口和 OpenAI 兼容格式,切换只需在请求体中修改模型 ID。对话历史(每次调用时作为参数传入)在两者之间可以互通。
两者都支持 reasoning_effort 吗?
是的。V4-Pro 和 V4-Flash 均支持相同的三种推理力度模式——不思考、思考和 Think Max,可见官方模型卡。模式之间的定价不变,按生成的 token 计费,Think Max 只是生成更多 token。
哪个版本更适合 Claude Code 风格的智能体循环?
Pro。Terminal Bench 2.0 的差距(67.9 vs 56.9)是多步骤 shell/工具循环最直接的参考指标,相差 11 分。Flash 能处理简单的智能体任务,但链式调用 10+ 个工具的循环,正好落入 Flash 退步最明显的类别。DeepSeek 自己的定位语言也明确指出——“在简单智能体任务上与 Pro 相当”,而非所有智能体任务。
两者的商业使用条款如何?
两者均以 MIT 协议发布,可见官方 Hugging Face 仓库,允许商业使用、修改和再分发,权重可自托管。通过托管 API 使用时,DeepSeek 自身的服务条款在此基础上另行适用——请针对你的部署地区进行核查。
定价结构相同还是不同?
结构相同,费率不同。两者均有输入、缓存命中输入和输出三个层级,均支持重复前缀的缓存折扣。Pro 与 Flash 的费率比例一致——Pro 的每 token 输出费用约为 Flash 的 12 倍。撰写本文时,官方文档尚无套餐层级或承诺用量定价。
往期文章:
