DeepSeek V4 Pro vs Flash: Какой выбрать для продакшена?
Сравниваем DeepSeek V4 Pro и V4 Flash для продакшена: компромиссы по возможностям, задержка, стоимость и какая версия подходит для вашей задачи.

DeepSeek выпустил V4 как две модели, а не одну: V4-Pro с 1,6T параметрами и 49B активированными, и V4-Flash с 284B параметрами и 13B активированными. Обе имеют контекстное окно на 1M токенов. Обе доступны с открытыми весами под лицензией MIT. Обе работают на одном API-интерфейсе.
Это важно, потому что вопрос больше не стоит как «использовать DeepSeek или нет». Вопрос в том, какую из двух моделей поставить за каким эндпоинтом. И правильный ответ редко звучит как «просто используйте Pro везде».
Это руководство по выбору для команд AI-продуктов и технических лидов, которые пытаются правильно маршрутизировать рабочие нагрузки. Если вы читали мою предыдущую статью о возможностях DeepSeek V4 для API-разработчиков, она была написана в эпоху единой модели. Это — версия с разделёнными уровнями.
Все цифры актуальны на дату публикации. Всё, что я не могу проверить по официальной документации, явно помечено.
DeepSeek V4 Pro vs Flash: краткий обзор
Позиционирование каждой версии (по официальному предварительному релизу)
По карточке модели V4-Pro от DeepSeek на Hugging Face, разделение намеренное — это не одна и та же модель разных размеров. Flash обучена отдельно, а не дистиллирована из Pro.
Собственная формулировка DeepSeek:
- V4-Pro — богатые знания о мире, превосходящие открытые модели, первоклассное рассуждение в математике/STEM/программировании, наилучшие результаты в агентных задачах.
- V4-Flash — рассуждение «вплотную приближается» к Pro, работает наравне с Pro в простых агентных задачах, слабее в сложных. Дешевле в обслуживании, быстрее отвечает.
Различие между «простыми и сложными» задачами — это и есть вся суть выбора. DeepSeek прямо говорит вам, где Flash начинает уступать. Не игнорируйте это.
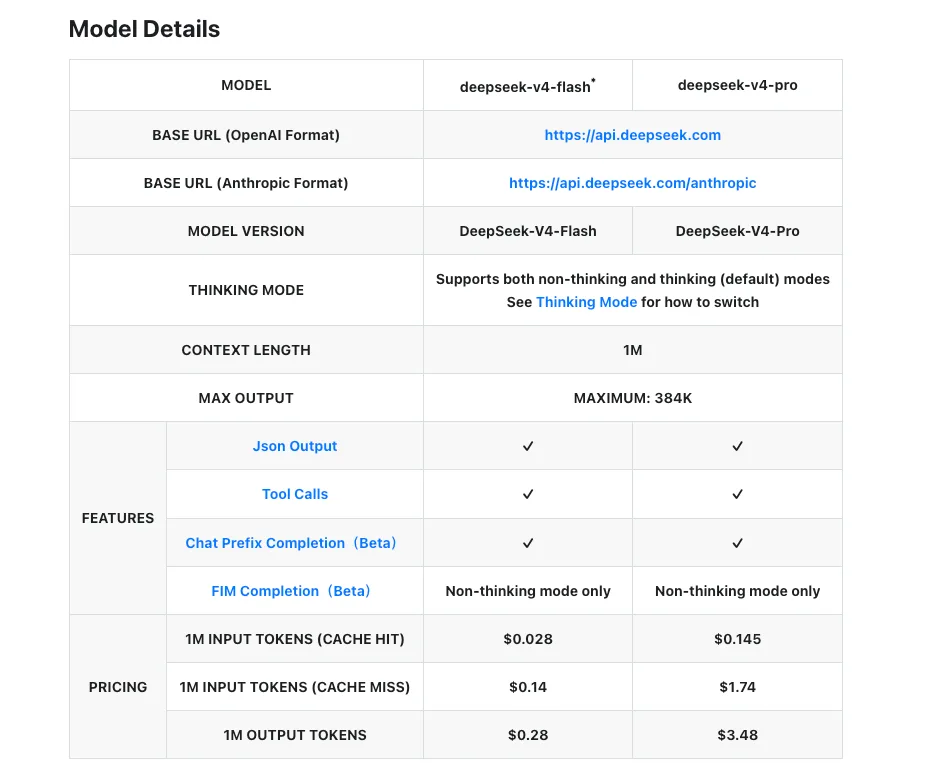
Общие функции (контекст 1M, режим мышления, совместимость API)
Функции, идентичные в обоих вариантах:
- Контекстное окно на 1M токенов в обоих вариантах, реализованное благодаря гибридной архитектуре внимания DeepSeek (CSA + HCA). По данным карточки Hugging Face, Pro требует лишь 27% вычислений на токен и 10% KV-кэша по сравнению с V3.2 при контексте 1M.
- Три режима усилий рассуждения — без мышления, с мышлением (высокий) и Think Max. Один и тот же флаг API, одно и то же поведение.
- Совместимый с OpenAI Chat Completions API и поддержка протокола Anthropic. Один и тот же
base_url, просто меняется идентификатор модели. - Лицензия MIT на веса для обоих, согласно официальным репозиториям.
Если вы переходите между ними, поверхность интеграции не меняется. Меняется только идентификатор модели и сумма счёта.
Различия в возможностях
Расхождение происходит в конкретных категориях оценки — и паттерн достаточно последователен, чтобы построить правило маршрутизации.
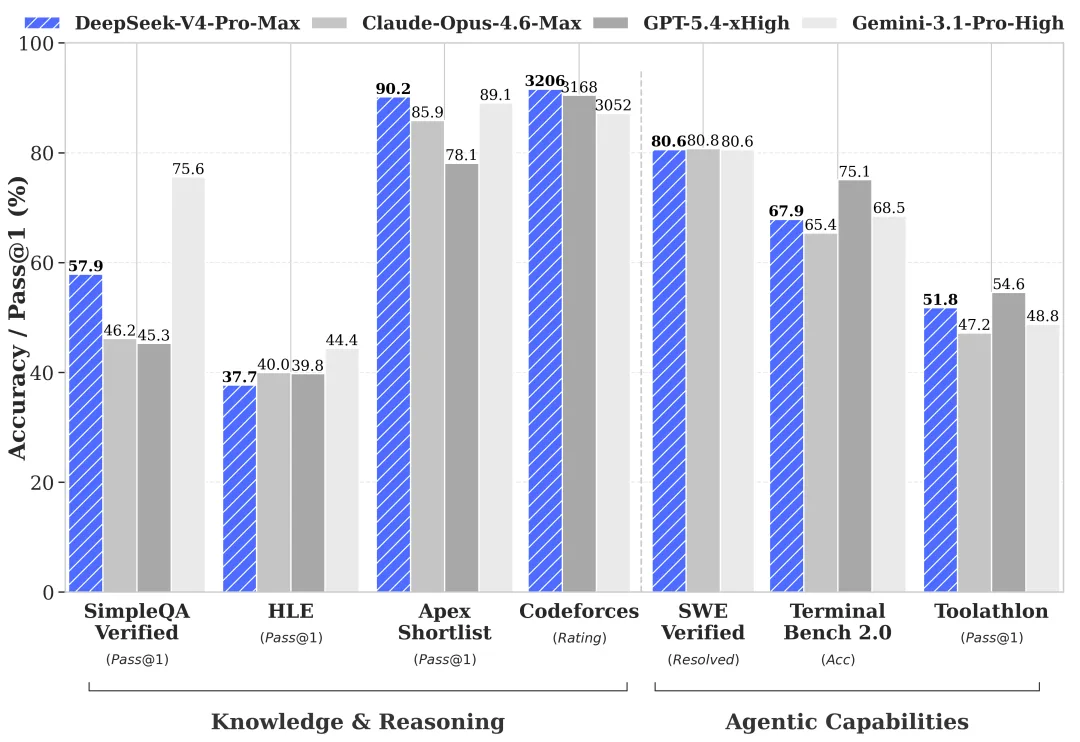
Знания о мире: Pro лидирует, Flash отстаёт (по официальным бенчмаркам — требует проверки)
По собственным предварительным бенчмаркам DeepSeek, обобщённым из их карточки HF и технического отчёта, разрыв между Pro и Flash узок в большинстве категорий оценки — но широк в нескольких конкретных местах:
| Бенчмарк | V4-Pro | V4-Flash | Разрыв |
|---|---|---|---|
| MMLU-Pro | 87,5 | 86,2 | 1,3 |
| LiveCodeBench | 93,5 | 91,6 | 1,9 |
| SWE-Verified | 80,6 | 79 | 1,6 |
| Codeforces | 3206 | 3052 | ~150 Elo |
| SimpleQA-Verified | 57,9 | 34,1 | 23,8 |
| Terminal Bench 2.0 | 67,9 | 56,9 | 11 |
Цифры предоставлены DeepSeek. На момент написания независимой репликации не существует — требует проверки перед внедрением в продакшн. Но форма разрыва — это сигнал, а не точные цифры.
SimpleQA-Verified — это фактическое воспроизведение. Terminal Bench 2.0 — многошаговое использование инструментов. Flash существенно проигрывает в обоих случаях. Это согласуется с тем, что DeepSeek сказал простым языком: простые задачи — нормально, сложные агентные нагрузки — слабее.
Паритет рассуждения на простых задачах
В программировании, математике и ограниченном рассуждении разрыв сужается до 1-3 пунктов. LiveCodeBench и MMLU-Pro ставят Flash в пределах досягаемости от Pro. Для большинства вызовов инференса в типичном продукте — диалоговый ход, однократная генерация, дополнение кода, суммаризация — Flash не является ухудшением в каком-либо смысле, который заметят пользователи.
В этом и заключается основная ценность Flash: это не урезанный Pro. Это отдельно обученная модель, которая оказывается близкой к Pro в середине распределения бенчмарков.
Расхождение агентных задач на высокосложных нагрузках
Категория с длинным горизонтом, множеством инструментов и множеством переходов — это место, где двое разделяются. Terminal Bench 2.0 и Toolathlon — соответствующие оценки здесь. 11-пунктовый разрыв на Terminal Bench — это не погрешность, которую можно списать на шум оценки.
Если ваш продукт — это агент программирования, работающий в 30-шаговом цикле с доступом к файловой системе и командной строке, или исследовательский агент, оркестрирующий 5+ вызовов инструментов на запрос, Flash будет чаще ошибаться там, где это дорого обходится при отладке. Не потому что Flash плохой — а потому что именно для такой нагрузки DeepSeek создал Pro.
Фреймворк принятия производственных решений
Выбор — это не «что лучше». Это «что соответствует форме этой нагрузки». Три сценария по умолчанию работают хорошо.
Когда выбирать Pro (агентное программирование, рассуждение с длинным горизонтом, корпоративная оценка)
Pro — правильный выбор, когда верно любое из следующего:
- Вы запускаете многошаговый агентный цикл (в стиле Claude Code, OpenCode, что угодно с использованием инструментов + планированием + проверкой за ход).
- Ваша задача требует точного фактического воспроизведения по длинному хвосту сущностей — 23-пунктовый разрыв SimpleQA предсказывает реальные различия в галлюцинациях.
- Вы проводите корпоративную оценку, где бизнес-цена неправильного ответа превышает стоимость токена на несколько порядков.
- Вам нужно рассуждение с длинным горизонтом на действительно полном контексте 1M токенов — цифры эффективности Pro при контексте 1M — это суть архитектурного решения.
Когда выбирать Flash (классификация с высоким QPS, суммаризация, UX чата)
Flash — это не бюджетный вариант. Это правильный вариант, когда:
- Вы выполняете классификацию, теггирование или извлечение с высоким QPS — задержка и стоимость одного вызова доминируют над разницей в качестве.
- Суммаризация и перевод — ограниченные, однопроходные задачи, где разница Flash в 1-2 пункта бенчмарка невидима для пользователей.
- Интерактивный UX чата — задержка первого токена важнее, чем 99-й перцентиль качества ответа, а Flash заметно быстрее.
- Работа, смежная с эмбеддингами: перефразирование запросов, классификация намерений, оценка релевантности.
Выбор Pro здесь расходует 10× на выходных токенах без ощутимой выгоды. Это худшее решение, чем использование Flash для агентного цикла.
Гибридная маршрутизация: Flash по умолчанию, Pro как запасной вариант
Для большинства продуктов правильная архитектура — ни то, ни другое — это оба варианта с маршрутизатором:
- По умолчанию направляйте каждый запрос в Flash.
- Эскалируйте до Pro по одному или нескольким явным триггерам: сбой вызова инструмента, превышен порог уверенности, многоходовой агент входит в известно сложную фазу, пользователь помечает ответ как неверный.
- Записывайте частоту эскалаций. Если <5% запросов эскалируются, Flash покрывает вашу нагрузку. Если >30%, вы находитесь на территории Pro, и маршрутизатор является накладными расходами.
Это работает только потому, что Pro и Flash разделяют API-поверхность и флаг режима рассуждения. Переключение между ними в середине сессии — это однострочное изменение в большинстве клиентов. Официальная документация DeepSeek по ценам подтверждает, что идентификаторы моделей являются родственными, а не изолированными эндпоинтами.
Компромиссы стоимости и задержки (на дату публикации)
Цифры ниже взяты с официальной страницы ценообразования DeepSeek по состоянию на 24 апреля 2026 года.
| V4-Flash | V4-Pro | |
|---|---|---|
| Входные (промах кэша) | $0,14 / M токенов | $1,74 / M токенов |
| Входные (попадание в кэш) | $0,028 / M токенов | $0,145 / M токенов |
| Выходные | $0,28 / M токенов | $3,48 / M токенов |
| Контекстное окно | 1M токенов | 1M токенов |
| Максимальный вывод | 384K токенов | 384K токенов |
Раскрытие информации о задержке: DeepSeek не опубликовал официальные цифры задержки по уровням для V4 на момент написания. Сторонние отчёты предполагают, что Flash обслуживается заметно быстрее, чем Pro, но я не могу указать на официальный бенчмарк — требует проверки после стабилизации предварительного релиза.
Ограничения и что ещё нуждается в проверке
Это предварительный релиз. Что нужно проверить перед направлением продакшн-трафика:
- Репликация бенчмарков. Все цифры выше взяты из собственного технического отчёта DeepSeek. Лидерборды в стиле Arena только начинают фиксировать результаты V4. Независимых запусков SWE-Bench Pro или Terminal Bench пока нет.
- Мультимодальность: пока недоступна. Оба варианта V4 работают только с текстом. DeepSeek заявил, что мультимодальность в разработке; сроков не названо.
- Коммерческий контекст. Репортаж Bloomberg о релизе отмечает, что V4 появляется на фоне продолжающегося геополитического контроля над DeepSeek, и некоторые не-китайские развёртывания имеют ограничения. Проверьте ваш compliance перед маршрутизацией пользовательских данных через официальный API; самостоятельный хостинг открытых весов — это чистый путь, если это вызывает беспокойство.
- Стабильность предварительного релиза. Метка «preview» явно указана и на карточке модели V4-Flash. Ожидайте изменений в поведении API и ценообразовании.
- Окно устаревания. Идентификаторы
deepseek-chatиdeepseek-reasonerперестанут работать 24 июля 2026 года. В настоящее время они маршрутизируются на V4-Flash. Если вы используете эти идентификаторы, вы уже получаете качество Flash, не зная об этом — мигрируйте явным образом.
На этом мои данные заканчиваются. Продолжаю следить. Обновлю, когда сторонние оценки догонят.
Часто задаваемые вопросы

Могу ли я переключаться между Pro и Flash в середине разговора?
Да. Оба разделяют одну API-поверхность и один формат, совместимый с OpenAI. Переключение — это изменение идентификатора модели в теле запроса. История разговора (которую вы передаёте в каждом вызове) переносима между ними.
Оба поддерживают reasoning_effort?
Да. Оба V4-Pro и V4-Flash поддерживают те же три режима усилий рассуждения — без мышления, с мышлением и Think Max — согласно официальным карточкам моделей. Ценообразование не меняется между режимами; выставляется счёт за сгенерированные токены, а Think Max просто генерирует их больше.
Какая версия лучше для агентных циклов в стиле Claude Code?
Pro. Разрыв Terminal Bench 2.0 (67,9 против 56,9) — это наиболее прямой показатель для многошаговых циклов оболочки/инструментов, и это 11-пунктовое различие. Flash справится с простыми агентными задачами, но цикл, объединяющий 10+ вызовов инструментов, попадает именно в категорию, где Flash регрессирует больше всего. Собственная формулировка позиционирования DeepSeek говорит об этом явно — «наравне с Pro для простых агентных задач», а не для всех агентных задач.
Условия коммерческого использования для обоих?
Оба выпущены под лицензией MIT согласно официальным репозиториям Hugging Face, что разрешает коммерческое использование, модификацию и распространение. Веса можно размещать самостоятельно. Для использования через хостинговый API поверх этого применяются собственные условия обслуживания DeepSeek — проверьте их для вашей географии развёртывания.
Структура ценообразования одинакова или различается?
Одинаковая структура, разные тарифы. Оба имеют уровни для входных данных, входных данных с попаданием в кэш и выходных данных. Оба поддерживают скидки на кэш для повторяющихся префиксов. Соотношение между тарифами Pro и Flash последовательно — Pro примерно в 12× дороже на выходном токене. В официальной документации на момент написания нет ценообразования на основе тарифных планов или обязательств.
Предыдущие публикации:
- DeepSeek V4: стоимость за миллион токенов — полная разбивка цен
- DeepSeek V4: требования к GPU и VRAM для самостоятельного хостинга
- Claude Opus 4.7: ближайшая альтернатива закрытой модели
- Паттерны агентных рабочих процессов: подключение инструментов и режимы сбоев
- MCP в продакшне: как реально работает контекст модели
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение
GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене
Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов
MAI-Image-2.5 API: что нужно знать разработчикам